Tópicos Especiais em Sistemas de Informação
Olá, aluno(a). Em 2017, uma das notícias que mais chocou os jogadores de Go, um jogo de tabuleiro, foi que uma máquina venceu por 2 x 0 o melhor jogador de Go, Ke Jie. Foi algo impressionante naquela época. E quem seria a máquina? A máquina foi denominada como AlphaGo, uma inteligência artificial (IA) desenvolvida pela Empresa Google no departamento chamado Google DeepMind. Demis Hassabis começou a criação dessa IA em 2014 e disse que o desfecho do jogo era algo muito imprevisível, já que a máquina operaria em sua capacidade máxima.
Ke tinha apenas 19 anos e se surpreendeu com a estratégia adotada pela AlphaGo, a qual informou que Ke jogou perfeitamente em seus 50 primeiros movimentos no jogo de tabuleiro. A disputa foi realizada no leste da China, e Ke foi o jogador mais próximo em comparação com as habilidades da IA. Para entender como a AlphaGo ganhou esse jogo, foi utilizando os conceitos de inteligência artificial, machine learning e deep learning, sendo estes dois últimos os objetos de estudo desta unidade! Vale ressaltar que as três áreas estão correlacionadas, mas não podem ser definidas como iguais.
Machine learning refere-se a como a máquina será treinada a partir da análise de grande quantidade de dados, utilizando os conceitos de ciência de dados e com a aplicação de algoritmos que permitem que a máquina tenha a habilidade de aprender a tarefa pela qual ela foi programada. Já deep learning permite que suas redes neurais artificiais calibrem mais suas respostas e precisão em seus acertos. Dessa forma, o AlphaGo da Google, após jogar contra si por várias vezes, aprendeu como funcionavam as regras do jogo e, assim, treinou sua partida, calibrando sua rede neural.
Ciência de dados, também conhecida como Data Science, é uma área emergente na computação de forma multidisciplinar, pois abrange várias áreas e possui um extenso modus operandi para realizar análise futura ou passada sobre os dados, que são disponibilizados na internet em uma grandeza de forma exponencial (PROVOST, 2016).
Em outra definição, podemos afirmar que é a habilidade em realizar a obtenção, compreensão, exploração, processamento, extração de valor e visualização dos dados, de diferentes segmentos do mercado (AMARAL, 2016).
Adicionalmente, a ciência de dados está envolvida na combinação de diversas técnicas de visualização e estrutura de armazenamento de dados para se chegar às conclusões dessas extensas quantidades de dados e, assim, poder aplicar esse conhecimento em situações reais (COELHO, 2019). Vejamos as principais técnicas, na Figura 4.1:
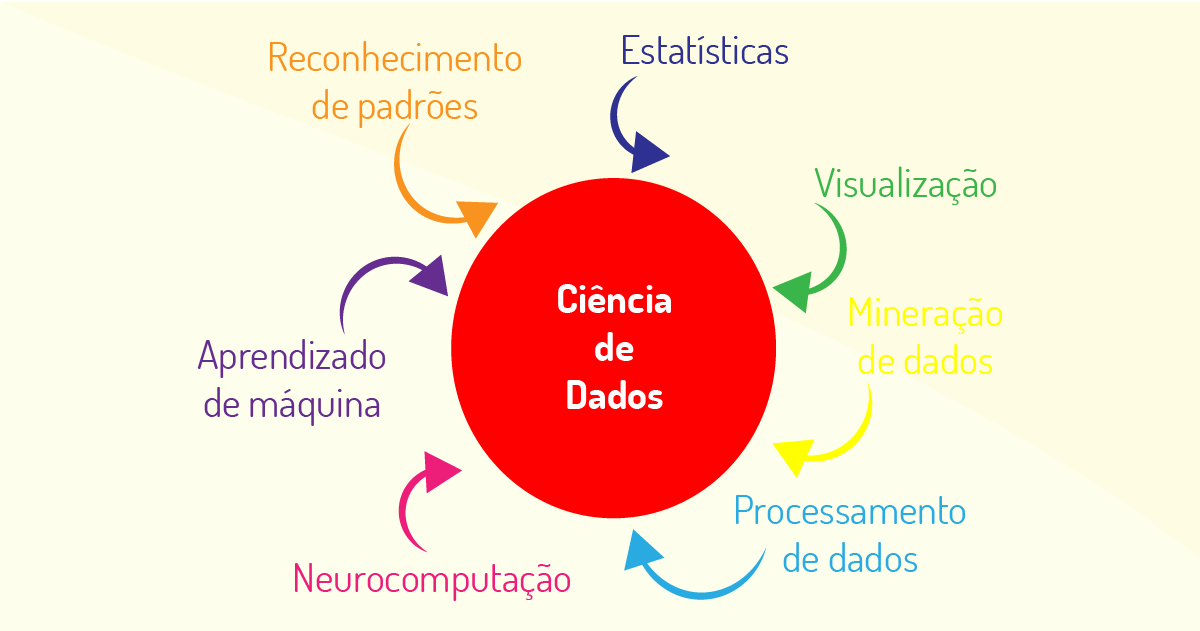
Sendo assim, cada uma dessas áreas visa oferecer diversas ferramentas para realizar toda uma análise dos dados para efetuar insights (visões) sobre o futuro dos dados processados e poder resolver problemas do mundo real e auxiliar na tomada de decisão das empresas, a depender da situação a ser analisada, podendo ser utilizadas em conjunto para se chegar à solução.
Por conseguinte, podemos ressaltar como exemplo prático o uso da área de ciência de dados no Design, no que se refere ao uso da análise dos dados coletados no mercado para apoiar à concepção de um novo produto para o cliente, desde a especificação com os aspectos do produto, definição da arquitetura, distribuição do produto e finalizando com a experiência final do usuário, maximizando as chances de sucesso (COELHO, 2019).
Podemos dizer que, apesar de a ciência de dados ter seu reconhecimento na área da computação, ela é considerada multidisciplinar, perpassando por várias áreas de conhecimento, como podemos visualizar na Figura 4.3:
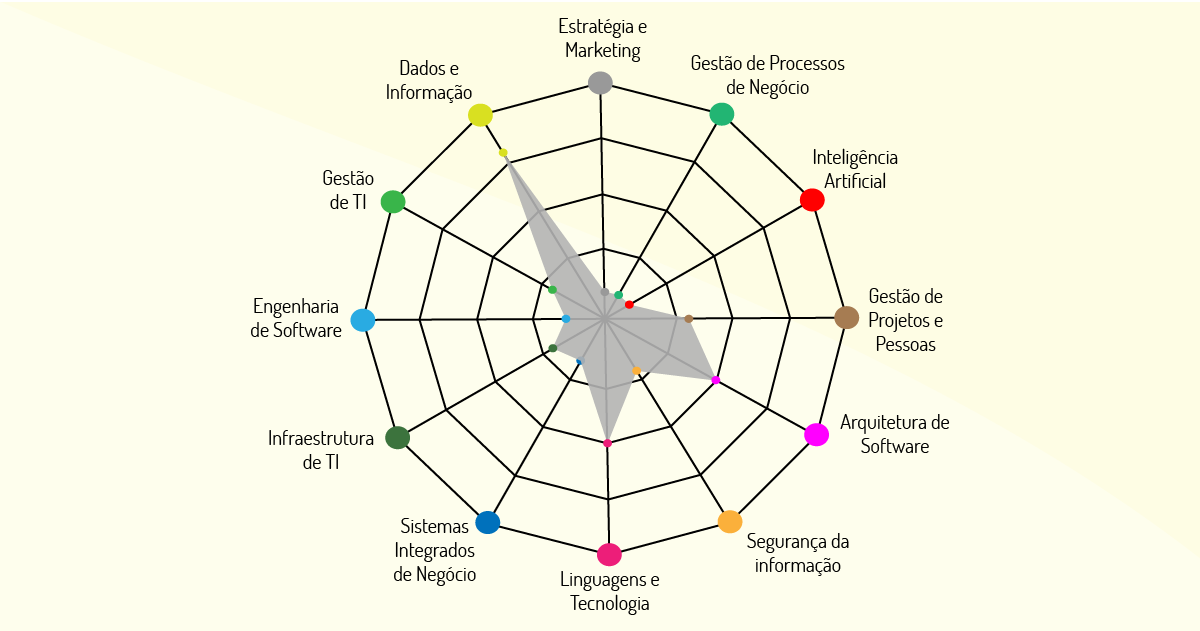
Todas essas áreas contribuem para que a ciência de dados possa ter sua ampla divulgação dentro do mundo de análise de dados. Cada qual com sua técnica, pode auxiliar as empresas na melhor classificação e organização de seus dados e, assim, se tornar mais competitiva dentro do mercado.
Outras definições sobre a ciência de dados podem ser (PORTAL GSTI, on-line):
Por fim, a ciência de dados visa desenvolver novas ferramentas e técnicas para análise de dados em função do extenso volume de dados que se tem na internet, posto que os métodos tradicionais acabaram ficando ultrapassados para analisar essas grandes quantidades de dados.
E qual o nome do papel de quem atua em Ciência de Dados? Dentro dessa área, tem-se o cientista de dados, que é o responsável por tratar dados (estruturados ou não), buscando transformá-los em oportunidades de negócio. Esse profissional precisa ter sólidos conhecimentos em Ciência da Computação, Modelagem Preditiva, Estatística, Matemática e Programação (AZAM, 2014).
Dentro da área de ciência de dados, é usual encontrarmos matemáticos, economistas, analistas de sistemas, estatísticos, engenheiros e profissionais de marketing, que estão sempre em busca de um produto perfeito; esses profissionais se utilizam da ciência para realizar a obtenção de dados valiosos.
Há uma série de habilidades necessárias para o cientista de dados, como: ser ágil na resolução de problemas, ter uma certa curiosidade para explorar os dados minuciosamente e padrões que não foram pensados para a solução de determinado problema; ter um bom raciocínio lógico e possuir uma boa visão de negócios, empreendedorismo e marketing. Tudo isso corrobora para que o cientista de dados seja versátil em um conjunto de características necessárias para a área (AZAM, 2014).
As funções relacionadas a esse profissional são: realizar análises quantitativas apoiando-se na modelagem matemática e análise estatística, transformar dados brutos para que sejam visualizados por todo o negócio, e até mesmo criar tendências aplicáveis na solução do problema e possuir uma visão profunda sobre o negócio da empresa e entender sobre gestão e tecnologia (BAUDISCH, 2016).
Conforme vimos, a ciência de dados, apesar de ser uma profissão recente, está envolvida com o conhecimento de diversas áreas e tem a responsabilidade de colocar em prática todo o processo de ciência de dados para a resolução de problemas. Alguns consideram o cientista de dados como um “pescador de dados”, já que busca os dados certos para a solução dos problemas.
Portanto, a área da ciência de dados está buscando descobrir conhecimento que tenha valor para o negócio, utilizando, para isso, a aplicabilidade de várias áreas, desde tecnologia à análise estatística. Para que ela possa ter uma maior efetividade, é necessária uma grande quantidade de dados, o que implica a busca de tecnologias que possam trazer novas fontes de dados, como a Internet das Coisas, e aumentar o desempenho de análise com Big Data. A ciência de dados objetiva não somente interpretar números, mas fazer previsões sobre eles, para que possam auxiliar na tomada de decisões. Para isso, tem-se o papel do cientista de dados, que faz a análise dos dados em massa, quase que em tempo real, para apoiar as empresas na geração de valor para o negócio.
O cientista de dados precisa ter uma série de conhecimentos em várias áreas, da estatística até a ciência da computação. Porém o mercado está com dificuldades de encontrar profissionais habilitados em ciência de dados. Você acha que a área precisaria segregar melhor seus campos de conhecimento? De que forma se pode melhorar a oferta de profissionais qualificados em ciência de dados?

Um dos principais papéis em ciência de dados é o do cientista de dados, o qual possui um conjunto de características importantes para realizar a análise de extensas quantidades de dados nessa área. Além disso, é correto afirmar que a função principal de um cientista de dados é:
ser ágil na resolução dos algoritmos de ciência de dados.
Incorreta. O cientista de dados precisa ser ágil na solução do problema, aplicando um algoritmo que responda perfeitamente ao problema.
encontrar dados que podem ser relevantes ou não para os negócios.
Incorreta. O cientista de dados precisa encontrar apenas dados relevantes para o negócio, para, assim, solucionar os problemas.
é considerado um “pescador de dados”, que busca os dados certos para a solução do problema proposto.
Correta. Uma das habilidades do cientista de dados é buscar o dado correto, para solucionar o problema de forma eficiente.
propor-se a criar redes neurais, como recurso trivial para buscar o conhecimento para a solução do problema proposto.
Incorreta. Não é a função principal do cientista de dados criar redes neurais, mas, sim, analisar grandes quantidades de dados; não pode ser considerada um recurso trivial, pois podem ter outras soluções.
implantar soluções para aprendizado de máquina.
Incorreta. Soluções de aprendizados de máquina são implementadas por profissionais de inteligência artificial.
Vimos que a ciência de dados é composta por diversas áreas de conhecimento, produzindo um produto que objetiva direcionar os usuários e/ou organizações em suas tomadas de decisões, por meio de uma série de etapas da análise de dados.
Para estruturar melhor as etapas para se realizar a análise de dados, foi criado um fluxo de atividades, conforme demonstrado na Figura 4.4:
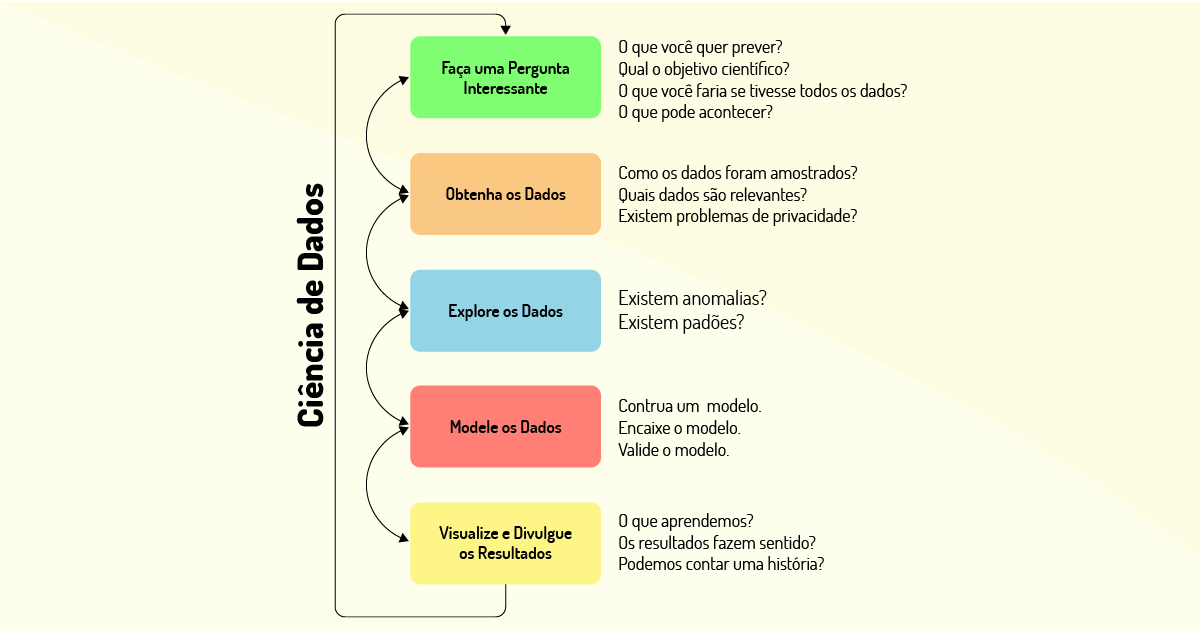
Agora, vamos explicar um pouco sobre o fluxo de atividades:
- Na etapa 1 (Faça uma Pergunta Interessante), é recomendado realizar uma pergunta interessante sobre o tema dos dados pesquisados. Algumas perguntas podem ser feitas como: O que você deseja prever? Qual o objetivo científico? O que pode ocorrer?
- Na etapa 2 (Obtenha os Dados), é realizada a obtenção dos dados que devem ser descritos, informando de que forma foi feita a amostra, quais dados são considerados relevantes e se existem problemas de privacidade atrelados a esses dados.
- Na etapa 3 (Explore os Dados), os dados são explorados massivamente até que se encontre alguma anomalia ou padrão que possa representar uma perspectiva de solução do problema.
- Na etapa 4 (Modele os Dados), é realizada a modelagem dos dados, por meio da construção e validação de um modelo que represente a estrutura dos dados analisados até chegar na resposta ao problema.
- Na etapa 5 (Visualize e Divulgue os Resultados), os dados podem ser visualizados e divulgados aos interessados. É interessante que algumas perguntas sejam feitas para verificar o aprendizado com o fluxo proposto, por exemplo: “o que foi aprendido com o fluxo?”; “os resultados têm noção lógica para a resposta do problema?”.
Essas etapas visam facilitar o processo para se realizar a análise de dados em ciência de dados. Essa abordagem permite que os dados sejam obtidos, preparados, analisados, visualizados e gerenciados, preservando as informações que podem ser obtidas com a ciência de dados.
Com base no livro R for Data Science, é definido um fluxograma do processo para ciência de dados com base em seis etapas, iniciando pela coleta de dados e finalizando com a comunicação dos resultados para os envolvidos de maneira automatizada e eficiente. As etapas são (vide Figura 4.5):
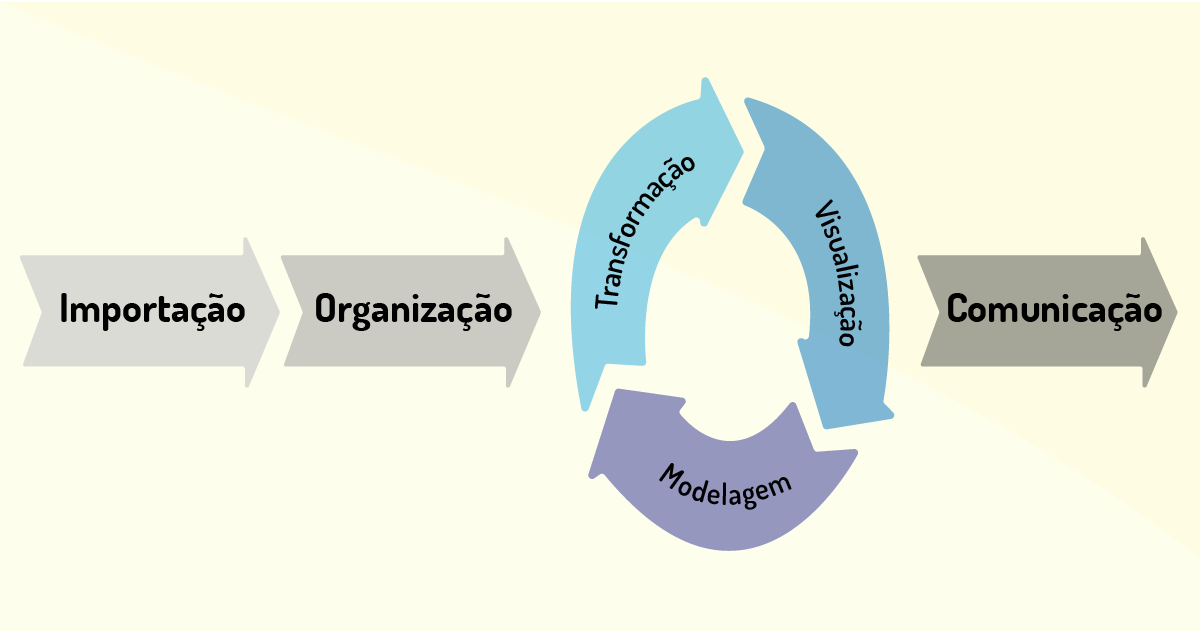
1- Importação: os dados são importados de diversos programas e/ou fontes de dados em que estão armazenados. Ex.: formato em arquivo do Word, em banco de dados como o MongoDB, entre outros.
2- Organização: aqui os dados serão organizados para poder armazenar a base de dados de forma consistente. Podem ser dispostos no formato de coluna, contendo uma variável, ou linha, contendo uma observação.
3- Transformação: nesta etapa podem ser criadas variáveis a partir das variáveis já armazenadas ou por meio de agrupamentos de variáveis, ou até mesmo utilizando cálculos estatísticos.
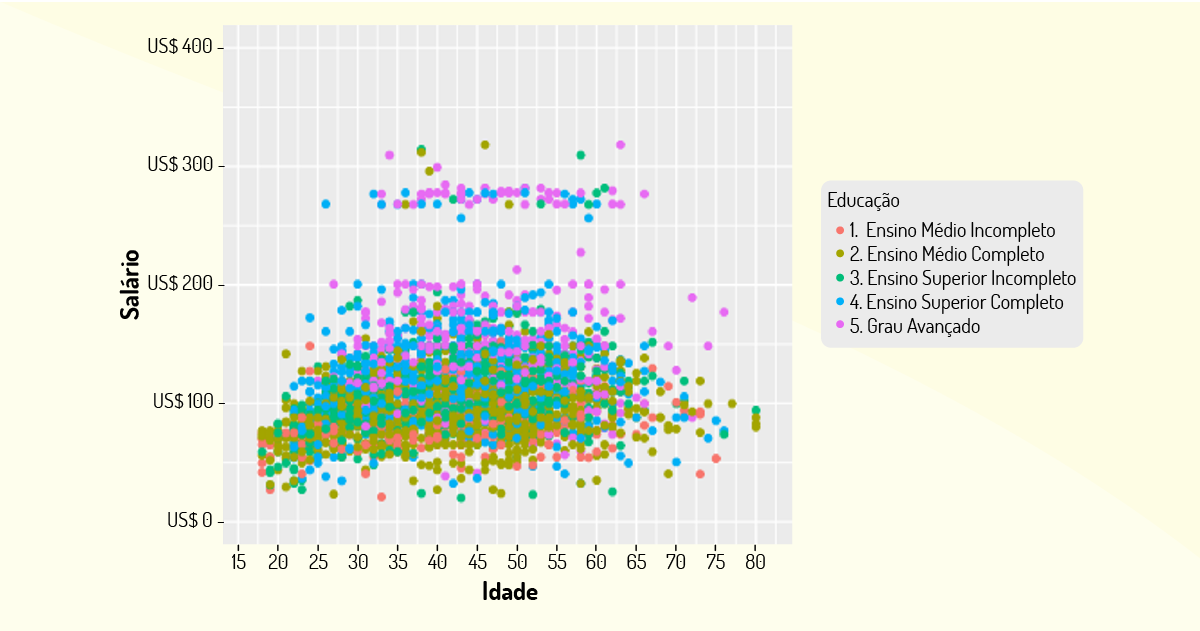
4- Visualização: consiste na primeira etapa em que o conhecimento é gerado, em que os dados são apresentados conforme um questionamento levantado. Na Figura 4.6, temos um exemplo de visualização dos dados de salário em função da idade e da educação de trabalhadores de uma empresa. A visualização de dados permite realizar novos questionamentos sobre eles, para que outras análises possam ser feitas, por exemplo: para os maiores salários com formação superior, qual a representatividade de cargos de chefia?
5- Modelagem: os modelos são ferramentas que complementam a etapa de Visualização, vista no ponto anterior. Podem ser utilizados modelos computacionais e até mesmo estatísticos para realizar o processamento dos dados que irão responder a questionamentos propostos para análise de dados.
6- Comunicação: são reportados a todos os interessados do processo os conhecimentos que foram obtidos com a extração dos dados.
Perceba que a diferença desse processo é que são utilizadas diversas ferramentas para que a análise de dados possa ser feita de forma automatizada e menos manual, como ocorre no processo descrito anteriormente.
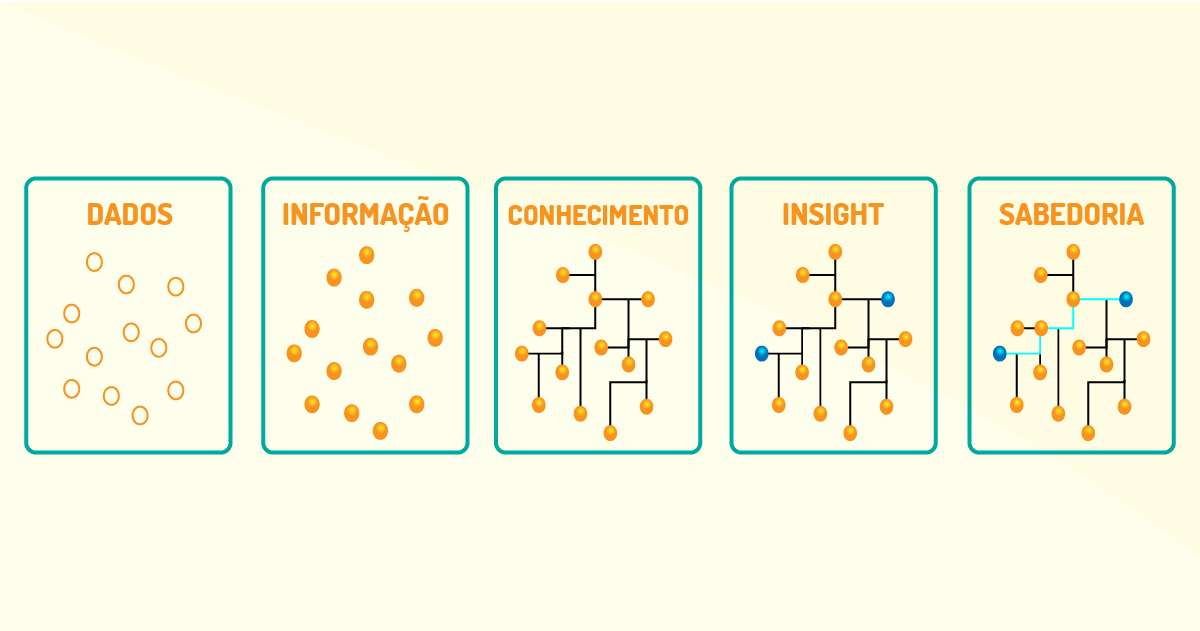
Vale ressaltar que a essência em ciência de dados é iniciar com uma base de dados extensa e analisar esses dados para que sejam geradas informações importantes. Após isso, por meio de combinações de informações, pode-se gerar o conhecimento que possibilita solucionar o problema proposto inicialmente. Por conseguinte, alguns insights (previsões), de forma isolada, podem ser adquiridos e, após analisá-los de forma extensa, pode ser obtida a sabedoria que se precisa para solucionar o problema corrente e, se eventualmente surgirem outros problemas similares, ser a base para a solução (WICKHAM; GROLEMUND, 2017). Podemos visualizar melhor na Figura 4.7:
Por fim, a ciência de dados pode ajudar a solucionar problemas de diversas áreas como: indústrias, setor financeiro, varejo, entre outras. Para isso, devem ser empregados algum processo para auxiliar as organizações em suas tomadas de decisões, gerenciamento de riscos, análises preditivas sobre o negócio, possibilidade de aumentar a oportunidade de negócios. Enfim, a ciência de dados é considerada uma técnica avançada para analisar uma extensa quantidade de dados em busca de padrões que possam auxiliar na resolução de problemas ou, ainda, na busca da melhoria de processos e/ou negócios.
Um fluxo de atividades determina quais passos devem ser seguidos para se chegar a um resultado. Os passos se propõem a ser esquemas de tarefas que, se seguidos sequencialmente em uma ordem predefinida, garantem a solução do problema.
Em ciência de dados, tem-se um fluxo de atividades com cinco tarefas, que são:
faça uma pergunta interessante, obtenha os dados, explore os dados, modele os dados e visualize e divulgue os resultados.
Correta. Esta é a sequência correta em um fluxo de atividades em ciência de dados, em que se começa com uma pergunta e depois são obtidos, explorados e modelados os resultados e, ao final, a partir da visualização de dados, os resultados são divulgados.
faça uma análise prévia dos dados, obtenha os dados, explore os dados, modele os dados e visualize e divulgue os resultados.
Incorreta. Não se começa o fluxo com uma análise prévia dos dados, mas com um questionamento.
minere os dados, obtenha os dados, explore os dados, modele os dados e visualize e divulgue os resultados.
Incorreta. Não se começa o fluxo com uma mineração dos dados, mas com um questionamento.
faça uma pergunta interessante, obtenha os dados, explore os dados, modele os dados e visualize e categorize os resultados.
Incorreta. Os resultados não são categorizados, mas dispostos em forma de respostas para a pergunta descrita no primeiro passo.
faça uma pergunta interessante, obtenha os dados, explore os dados, minere os dados e visualize e divulgue os resultados.
Incorreta. Os dados não são minerados, mas modelados no fluxo de atividades.
A ciência de dados é uma área multidisciplinar, conforme já vimos em nossos estudos. Requer, basicamente, os conhecimentos de estatística, ciência da computação e matemática para que análise de dados seja efetuada de forma metodológica. Para isso, são utilizadas diversas tecnologias que podem ser agrupadas em três categorias: linguagens de programação, armazenamento e processamento de dados e estruturas de banco de dados SQL e NOSQL.
Várias linguagens de programação podem ser utilizadas para ciência de dados, como Java, R, Python, Julia, dentre outras opções. A linguagem de programação Python tem sido a mais utilizada, porém, a linguagem Julia tem despontado, sendo uma linguagem de programação de alto nível, dinâmica e de alto desempenho. Neste tópico, veremos as linguagens de programação R e Python, bem como suas especificidades. Vamos lá?
É definida como uma linguagem de programação com o objetivo de solucionar problemas estatísticos, sendo bastante utilizada para a visualização gráfica de dados. Foi criada pelos pesquisadores Ross Ihaka e Robert Gentleman, que, com a letra inicial dos seus nomes, nomearam a linguagem como R (MSPERLIN, on-line).
O R apresenta algumas vantagens, dentre as quais destacam-se: definida como uma plataforma estável e utilizada amplamente na indústria; possui o suporte necessário para correção de erros e atualizações de versões; tem pacotes de códigos para as mais diversas funcionalidades; altamente compatível com outras linguagens de programação e sistemas operacionais, e é uma linguagem gratuita, o que influencia a sua seleção em um ambiente empresarial, sem custos com licença e distribuição (WICKHAM; GROLEMUND, 2017).
Para entender melhor como o R funciona, vamos observar sua arquitetura, conforme Figura 4.8:
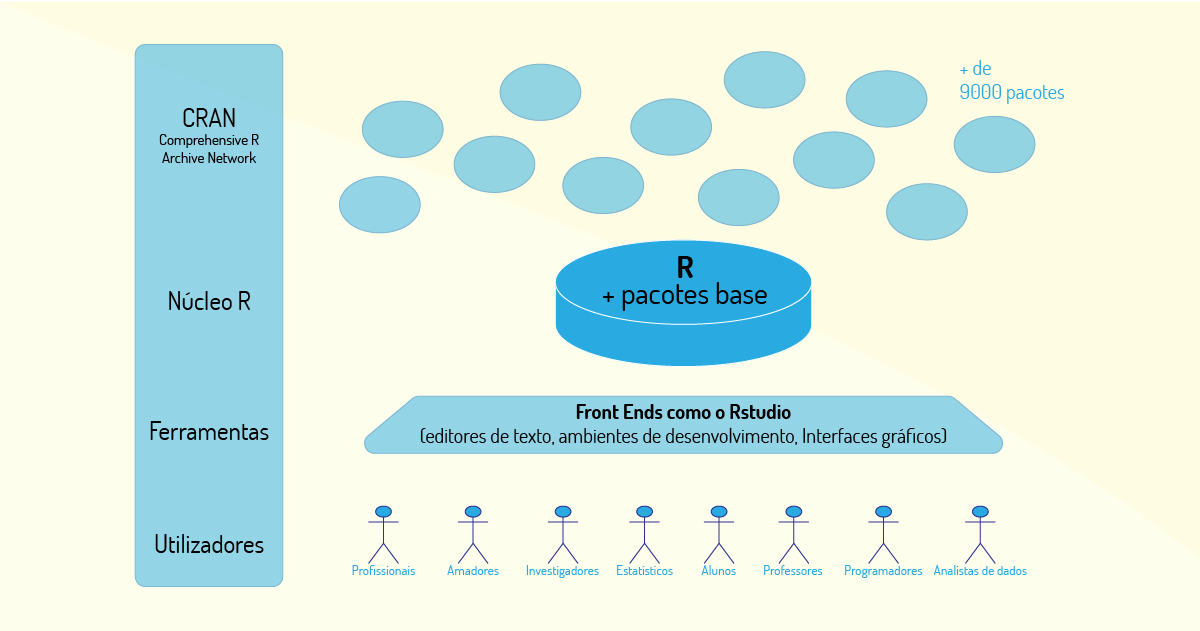
Basicamente, os componentes da arquitetura R podem ser descritos como: utilizadores, aqueles que podem utilizar o R para diversos fins; ferramentas, são disponibilizadas várias ferramentas, sendo a mais utilizada o RStudio; o núcleo R é composto por pacotes de código base do R e CRAN (Comprehensive R Archive Network), que é uma rede de servidores web, e FTP (File Transfer Protocol), que armazena códigos e documentação atualizados do R (GOUVEIA, 2017).
Adicionalmente, R é utilizado em ciência de dados quando as tarefas de análise de dados precisam ser efetuadas em um único computador (standalone), ou quando a análise precisa ser feita em servidores individuais. Além disso, é muito eficiente para a análise de dados, pois possui diversos pacotes com fórmulas e testes estatísticos (GOUVEIA, 2017).
É uma linguagem de programação com um diverso conjunto de funcionalidades que vão desde a coleta de dados até a construção de aplicativos. Por ser uma linguagem orientada a objetos, tem ampla aceitação no mercado, já que esse é um padrão para as novas linguagens de programação e, com ela, é mais acessível escrever um código em larga escala e robusto (PYTHON SOFTWARE FOUNDATION, 2010).
Quando Python é empregado com outras ferramentas (bibliotecas) conhecidas por cientista de dados – como Pandas (manipulação de dados), Numpy e Scipy (computação científica), Scikit-learn (Aprendizado de máquina) e Seaborn (visualização de dados) –, torna-se a linguagem preferida por eles e facilita o trabalho estatístico (MATOS, 2018).
Para que os usuários possam contribuir com a linguagem, podem adicionar novos pacotes no repositório Pypi, que também possui diversas bibliotecas disponíveis para os usuários, disponibilizando várias funcionalidades.
Python pode ser utilizado para análise de dados de forma integrada com aplicativos web ou por meio de códigos estatísticos integrados em um servidor em ambiente de produção. É considerada, também, uma ótima opção para scripts de automatização de mineração de dados, além de possibilitar o seu uso em partes do desenvolvimento de softwares frontend e backend.
Uma de suas ferramentas IDE é o Jupyter Notebook (antigo IPython Notebook), uma ferramenta para análise exploratória e apresentações de dados, sendo um ambiente computacional interativo e incremental que combina execução de código e cálculos matemáticos (MATOS, 2018; PYTHON SOFTWARE FOUNDATION, 2010).
Vale ressaltar que alguns atrativos podem ser mencionados para que Python seja utilizada como linguagem para análise de dados, como: código aberto, em que o usuário é livre para instalar onde quiser; comunidade on-line disposta a ajudar na criação dos pacotes para o repositório; maior facilidade de aprendizado sobre a linguagem, e pode se tornar a linguagem mais acessível para análise de dados (PYTHON SOFTWARE FOUNDATION, 2010).
Por fim, Python é uma linguagem de amplo uso, que possui características inerentes às linguagens de programação e pode ser utilizada por usuários com diferentes tipos de conhecimentos. Possui uma gama de pacotes estatísticos que auxiliam na análise de dados e pode executar trechos de código em R. Está se tornando uma das ferramentas mais utilizadas atualmente em ciência de dados.
Vamos conhecer, a seguir, o armazenamento e processamento de dados, por meio dos sistemas Pig e Hive, que têm como base o Apache Hadoop, plataforma que adota o conceito de MapReduce, a fim de prover a análise de dados em um ambiente de Big Data.
O Pig é um sistema de fluxo de dados de alto nível e de código aberto, que fornece uma linguagem simples chamada Pig Latin, para consultas e manipulação de dados. O Pig está sendo utilizado por empresas como Yahoo, Google e Microsoft para coletar grandes quantidades de conjuntos de dados na forma de fluxos de cliques, registros de pesquisa e rastreamentos da Web. O Pig também é usado em alguma forma de processamento e análise ad-hoc de todas as informações (EDUREKA, 2019).
Foi desenvolvido anteriormente pelo Yahoo, em 2006, para que os pesquisadores tenham uma maneira ad-hoc de criar e executar tarefas do Map Reduce em conjuntos de dados muito grandes. Foi criado para reduzir o tempo de desenvolvimento por meio da abordagem de várias consultas (EDUREKA, 2019).
Por fim, o Pig fornece operações de dados como filtros, junções, ordenações, suporte a tipos de dados aninhados, como tuplas e mapas, que estão faltando no Map Reduce, além de ser fácil de escrever e de ler, principalmente se houver conhecimento sobre SQL (Structured Query Language).
O Hive é um pacote de data warehouse criado sobre o Hadoop para executar a análise de dados. É direcionado para usuários que se sentem confortáveis com o SQL, pois possui uma linguagem de programação chamada 'HiveQL', que é semelhante ao SQL. O Hive é usado para gerenciar e consultar dados estruturados (EDUREKA, 2019).
Ele abstrai a complexidade do Hadoop, ou seja, você não precisa escrever um programa de Map Reduce. Com o Hive, também não é necessário que o usuário aprenda as APIs Java e Hadoop. Com os incríveis recursos do Hive, o Facebook agora pode analisar vários Terabytes de dados todos os dias, já que a empresa queria maneiras diferentes de armazenar, extrair e analisar dados. Hoje em dia, os dados do Facebook são coletados por cronjobs (tarefas agendadas) e armazenados no OracleDB (EDUREKA, 2019).
Como todos os dados disponibilizados podem ser armazenados de forma temporária ou não, é necessário ter conhecimento sobre tipos de banco de dados, relacionais ou não, para que seja gerado o conhecimento necessário para alcançar o objetivo da solução de um problema determinado.
Uma das formas de manipulação dos dados é utilizando a linguagem SQL (Structured Query Language), que é uma linguagem padrão universal para realizar essa manipulação por meio de SGBDs (Sistema de Gerenciamento de Banco de Dados), que podem ser definidos como um conjunto de softwares responsáveis por realizar o gerenciamento de uma base de dados (SQL, on-line).
O SGBD permite realizar várias tarefas relacionados aos dados, como salvá-los no HD, fornecer uma interface para que programas e usuários externos possam acessá-los, realizar a ligação de dados e metadados, permitir o controle de acesso às informações do banco de dados, o que pode ser realizado utilizando a linguagem SQL (SQL, on-line).
Em ciência de dados, os dados podem ser obtidos por meio de uma grande base de dados e, então, é interessante conhecer a linguagem SQL, que serve como linguagem universal para realizar qualquer operação em um SGBD, independentemente do tipo de programa, código e/ou tarefas utilizados nesse SGBD (VICTÓRIA, 2019).
Mas como a quantidade de dados a ser armazenada é muito grande, foi nesse contexto que surgiram os bancos de dados não relacionais (NOSQL), que permitem armazenar dados estruturados ou não, de forma mais veloz e flexível e têm escalabilidade, sendo ideais para soluções de Big Data (VICTÓRIA, 2019).
O NOSQL tem uma série de tipos de bancos de dados, como: colunas, em que os conjuntos de dados são armazenados em linhas particulares de uma tabela; grafos, em que os dados são armazenados em formato de arcos ou vértices conectados por arestas (conjunto de linhas); chave-valor, em que o banco armazena um conjunto de chaves com seus respectivos valores, simulando tabelas hash, e documento, em que todo dado não estruturado é um documento que pode possuir diversos formatos. Vale ressaltar, também, que o NOSQL é gratuito e possui um alto desempenho em consultas ao banco de dados (VICTÓRIA, 2019).
Por fim, essas estruturas de banco de dados, relacionais ou não, são adaptáveis para cada contexto em ciência de dados. Elas não são competitivas, pois, se tivermos um grande volume de dados, é recomendado o NOSQL, e, caso a análise e tratamento de dados não precise ser tão profunda, podem ser utilizados os bancos de dados relacionais.
Para que a ciência de dados possa ser implementada são necessários alguns recursos tecnológicos como linguagens de programação, estruturas de armazenamento e processamento de dados e banco de dados. Qual das alternativas a seguir refere-se a exemplos de banco de dados?
Java e Mysql.
Incorreta. Java é uma linguagem de programação.
Mysql e Nosql.
Correta. São tipos de banco de dados muito utilizados em ciência de dados.
Nosql e Java.
Incorreta. Java não é um tipo de banco de dados, mas, sim, uma linguagem de programação.
PHP e Mysql.
Incorreta. PHP não é um tipo de banco de dados, mas, sim, uma linguagem de programação.
Ruby e Nosql.
Incorreta. Ruby não é um tipo de banco de dados, mas, sim, uma linguagem de programação.
Agora que entendemos os conceitos acerca de ciência de dados, vamos compreender melhor como as organizações estão aplicando essa área em alguns casos de sucessos que corroboram para o crescimento dessa nova forma de analisar os dados.
Case 1: Airbnb
O serviço de hospedagem on-line Airbnb realiza sugestões de hospedagem para seus usuários baseadas nos parâmetros informados por eles. A busca retorna uma sugestão de local para que o usuário se hospede (AIRBNB, on-line).
Assim, o Airbnb sempre precisou dos dados para que o negócio pudesse ter sucesso, procurando entender seus dados com base na demografia dos locatários, preços, período e número de hóspedes. Baseando-se na enorme quantidade de clientes cadastrados na plataforma, demanda por aluguéis e locais, foi necessário analisar mais profundamente esses dados e, assim, se apoiaram na ciência de dados (AIRBNB, 2019).
A empresa criou um sistema de preço dinâmico denominado Aerosolve, que realiza uma predição de preço com base na localização do usuário que tem o local para alugar, período do ano e uma série de outros parâmetros para se chegar a uma faixa de preços ideal e compatível com o mercado de aluguel, e, assim, tanto a empresa quanto o locatário podem maximizar seus lucros (AEROSOLVE, on-line).
Além disso, a empresa divide suas equipes em duas grandes categorias: negócios, na qual os funcionários estão preocupados em como o locatário pode oferecer um serviço de qualidade e excelência, em que os locadores podem acompanhar suas despesas na locação do imóvel, e plataforma, que realiza o desenvolvimento de APIs (Application Programming Interface) para processar os pagamentos dos usuários, manter a segurança da comunidade Airbnb e fornecer a infraestrutura de dados para as ferramentas de análise (ILUMEO, on-line).
Nessas duas equipes há cientistas de dados que se propõem a descobrir as necessidades e desafios de cada equipe e trabalham de forma otimizada com vários setores, como: engenharia, design, arquitetura, entre outros, para que os dados sejam considerados itens avaliativos na maioria das decisões dos grupos (ILUMEO, on-line).
Por fim, Airbnb possui no seu quadro de funcionários de cientista de dados e especialistas de diversas áreas, como: ciência da computação, para a construção de algoritmos complexos de aprendizagem; economistas que avaliam como maximizar o lucro da empresa, e estatísticos que realizam análises sobre o impacto de cada mudança (ILUMEO, on-line).
Case 2: Netflix
Um dos maiores serviços de streaming, a Netflix obteve grande sucesso pela utilização da ciência de dados. Em todo o tempo que o usuário está utilizando o serviço, ele fornece informações valiosas para os cientistas de dados que fazem análise minuciosas sobre esses dados para aumentar o poder competitivo da empresa (COMO..., 2018).
Em 2015, a Netflix disponibilizou um infográfico em que apontou os episódios de séries mais populares, a partir do qual 70% dos espectadores assistiram até finalizar a primeira temporada. Dessa forma, a Netflix proporcionou o binge watching (“maratona de episódios”), em que os usuários assistem vários episódios de uma só vez, enquanto as outras emissoras só liberam um episódio por vez. Foi com base nessa pesquisa que a Netflix passou a disponibilizar todos os episódios de uma só vez e, assim, conseguiu fidelizar o seu usuário na plataforma (COMO..., 2018).
Além desse caso, mais precisamente em 2011, a Netflix analisou todos os dados de consumo do usuário e percebeu que os usuários gostavam de filmes estrelados por Kevin Spacey, os longas metragens produzidos por David Fincher e uma minissérie britânica (1990) sobre política. A partir disso, ela passou a produzir, em 2013, a série House of Cards, que é uma das séries de maior sucesso que consiste em um drama político produzido por Fincher e tem o ator Spacey como papel principal (COMO..., 2018).
Adicionalmente, ainda utilizando a ciência dos dados, a empresa produziu corretamente teasers para promover a série, e cada teaser era especial para cada perfil de usuário: se um usuário gostava mais de filmes com Spacey, o teaser teria mais cenas do ator; se outro usuário apreciasse mais cenas do sexo feminino, então, o foco do teaser era no elenco feminino da série. Tudo isso atraia o usuário para o que ele realmente apreciava em uma série.
Um outro caso de sucesso da Netflix foi o lançamento, em 2016, da série Stranger Things, uma das séries de maior sucesso da empresa. A série foi rejeitada por, pelo menos, 15 redes de TV até ser recebida pela Netflix para o lançamento. Essas redes de TV consideraram que não havia público-alvo para uma série estrelada por crianças que não fosse especificamente infantil. No entanto, a Netflix, utilizando os dados de seus usuários, percebeu que havia, sim, um público-alvo e conseguiu um grande sucesso lançando a série (GALLI, 2017).
Por fim, a empresa relata que utiliza da linguagem Python para análise de dados em seu serviço, realizando tarefas de monitoramento de dados, movimentação e sincronização dos dados, ativação de aplicativos dentro da plataforma para obter informações, entre outros. Dessa forma, a linguagem, juntamente com uma equipe de excelentes profissionais, auxilia no sucesso que a empresa é hoje!
Case 3: Bayes Impact
A empresa Bayes Impact, fundada em 2014 e sediada em São Francisco (Norte da Califórnia), composta por vários cientistas de dados, auxilia ONGs (Organizações sem fins lucrativos) a resolver vários problemas, sejam de ordem social e até mesmo de saúde (IMPACT..., on-line).
Um dos casos que a empresa ajudou a solucionar foi junto ao departamento de saúde dos EUA para realizar melhores combinações entre as pessoas que se predispõem a doar órgãos e as que precisam de transplantes. A partir dos dados informados por esses tipos de pessoas, os cientistas de dados conseguiram realizar uma análise melhor desses dados e, assim, propor uma combinação mais eficiente e que teve a maioria de acertos (IMPACT..., on-line).
Outros casos em que a empresa teve grande importância com a utilização dos dados foi para a Michael J. Fox Foundation, em que desenvolveu melhores métodos de ciência de dados para corroborar com as pesquisas de Parkinson.
Além disso, a Bayes criou rotinas específicas para combater fraudes em microfinanças. As empresas de microcrédito estavam com altas taxas de fraude e esses obstáculos impediam sua capacidade de fornecer crédito rapidamente aos interessados, mas também no quanto eles poderiam emprestar (IMPACT..., on-line).
A Bayes Impact trabalhou com a organização de microfinanças Zidisha, que conecta diretamente credores e mutuários sem passar por uma estrutura intermediária. Zidisha trabalha, principalmente, no Quênia e Gana. O Bayes Impact desenvolveu algoritmos para o Zidisha para detectar rapidamente possíveis tentativas de fraude. Após essa intervenção, a fraude caiu 35% na plataforma e 10% dos novos pedidos de empréstimo foram aceitos graças à detecção de fraudes da Bayes (IMPACT..., on-line).
Vale ressaltar que a empresa está construindo um modelo com base na ciência de dados para auxiliar a cidade de São Francisco na otimização de serviços básicos e essenciais da cidade, como otimizar as taxas de respostas em emergências.
Percebe-se que a Bayes maximiza o uso da ciência de dados para tentar solucionar problemas sociais. Eis aqui uma outra finalidade desse tipo de ciência: enquanto algumas empresas preferem utilizar os dados para auxiliar na geração de lucro e tomada de decisão, essa empresa está voltada a promover iniciativas que solucionem problemas de ordem social e que possam causar um grande impacto em um mundo que é orientado por dados.
Case 4: Merck
A Merck KGaA, em Darmstadt, Alemanha, é uma empresa líder em ciência e tecnologia nas áreas de cuidados com a saúde, avaliada em 40 bilhões e presente em 140 mercados em todo o mundo (MERCKGROUP, on-line).
Um dos grandes problemas da empresa era que seus engenheiros dispendiam entre 60% e 80% para analisar, acessar e visualizar os dados valiosos para cada projeto e, assim, o esforço era muito alto e lento, o que fazia com que os negócios da empresa fossem comprometidos pela baixa velocidade na aquisição de informações (MERCKGROUP, on-line).
Dessa forma, a empresa implantou o MANTIS (Manufacturing and Analytics Intelligence) para obter dados do ERP e sistemas centrais de fabricação e controle de estoque para obter mais insights para os negócios (MERCKGROUP, on-line).
Esse sistema, classificado como armazenamento de dados, é composto por vários bancos de dados e ferramentas de código aberto que processam dados estruturados ou não e que estejam armazenados nos sistemas da empresa. Os dados processados pelo MANTIS poderiam ser textos, áudios, vídeos, imagens, entre outros (MERCKGROUP, on-line).
A partir disso, analistas de negócios, que não têm a expertise técnica, começaram a visualizar os dados a partir de uma interface de visualização dos dados desse sistema e, assim, puderam sugerir melhores insights para a empresa com essa melhoria.
Outro ponto foi que os cientistas de dados da empresa melhoraram suas análises a partir de ferramentas de alta tecnologia desse sistema, como as de simulação e modelagem dos dados, auxiliando o trabalho dos engenheiros da empresa.
Assim, o MANTIS ajudou nos processos da empresa e reduziu em 45% o tempo e o custo do portfólio geral de projetos de análise de TI (Tecnologia da Informação) da empresa. Além disso, trouxe resultados comerciais tangíveis, com uma redução de 30% no tempo médio de entrega dos projetos e uma redução de 50% nos custos médios de estoque com os medicamentos. Vale ressaltar que a empresa realizou um teste piloto desse sistema em uma fábrica da Ásia e Pacífico e percebeu que haveria um grande retorno para a empresa; dessa forma, seguiu para implantar por toda as filiais da empresa (MERCKGROUP, on-line).
Considere o trecho a seguir:
“A equipe do Booz Allen conseguiu desenvolver um aplicativo para os treinadores da MLB para prever qualquer lançamento de arremessador com até 75% de precisão, mudando a maneira como as equipes se preparam para um jogo, formação da equipe adversário e o melhor arremesso com base em alguns parâmetros” (3 EXEMPLOS…, 2019, on-line).
Pode-se afirmar que o aplicativo mencionado no contexto anterior está utilizando técnicas de ciência de dados, pois:
com as predições do aplicativo, o treinador procura formas específicas para se preparar para o jogo.
Correta. As previsões têm a capacidade de analisar a formação de uma equipe adversária e executar previsões para antecipar como estruturar suas jogadas.
por meio das previsões do aplicativo, a equipe fica limitada em suas jogadas.
Incorreta. As previsões não limitam as jogadas da equipe, mas funcionam como formas de auxiliá-la para executar os melhores arremessos em suas jogadas.
as equipes treinam movimentos específicos, mas não sabem qual é o melhor momento para o arremesso.
Incorreta. O aplicativo analisa várias formas de arremesso, até chegar em um arremesso ideal com base em várias características do jogador, fazendo com que o aplicativo informe o momento ideal do arremesso.
as equipes antecipam as suas jogadas, mas não conseguem analisar como será a formação da equipe adversária.
Incorreta. O aplicativo oferece várias formas de combinação das equipes adversárias, o que influencia no melhor arremesso da equipe do Booz, resultando na melhor estruturação das suas partidas.
mediante as predições do aplicativo, o jogo não mudará a forma como acontece.
Incorreta. As previsões são a base para a formação do jogo, mas pode existir casos de exceção não analisados pelo aplicativo que podem mudar a forma como o jogo acontece.
Existem várias definições para esse termo, mas vamos, aqui, tentar resumir para você. Do inglês machine learning, o aprendizado de máquina pode ser definido, basicamente, como uma subárea de inteligência artificial que permite a construção de sistemas automatizados, possuindo a capacidade de aprender com a grande quantidade de dados recebidas e auxiliar na tomada de decisões sem a interferência humana (SAS, on-line).
Outros conceitos estão atrelados ao aprendizado de máquina, como:
- é uma técnica de análise de dados que pode ser entendida como a capacidade de transformar dados brutos em informações relevantes. Essa técnica automatiza a concepção de modelos analíticos (MOHRI; ROSTAMIZADEH; TALWALKAR, 2012).
- é um método que permite que as máquinas aprendam, de forma isolada, determinadas tarefas humanas a partir da análise de um grande volume de dados (MAGNUS, 2018).
- é um ramo da ciência da computação que fornece respostas automatizadas ao usuário, utilizando conceitos de Big Data e Inteligência Artificial (SILVA et al., 2007).
Dessa forma, percebe-se que o aprendizado de máquina tem um conceito bem amplo e está intrinsecamente ligado à Big Data e à inteligência artificial (conceitos vistos anteriormente) e, assim, conseguem analisar essa quantidade de dados por meio do uso de uma infinidade de algoritmos para estabelecer padrões nos dados analisados. Mas o que são esses algoritmos? Bom, vamos prosseguir para explicar melhor.
Os algoritmos são a base fundamental para que o aprendizado de máquina possa funcionar. Tais algoritmos fazem uso de análises estatísticas para realizar previsões das respostas de forma mais precisa e, assim, entregar o melhor resultado da predição com uma chance de erro mínima.
Esses algoritmos podem ser classificados em (MOHRI; ROSTAMIZADEH; TALWALKAR, 2012):
Com relação à aprendizagem, eles podem fazer uso do algoritmo supervisionado, não supervisionado, ou de nenhum deles, podendo ser classificados em quatro aprendizados de máquina existentes, que são (MOHRI; ROSTAMIZADEH; TALWALKAR, 2012):
- aprendizado supervisionado: com a base do algoritmo supervisionado, o sistema tem como entrada um conjunto de dados com a resposta correta (dados rotulados), e o que a máquina precisa é retornar a resposta correta a partir do aprendizado dessas variáveis de entrada e saída. Ex.: busca de imagens no Google, em que o algoritmo busca a origem da imagem, já classificada como a resposta correta para aquela determinada busca, com base nos dados fornecidos. A supervisão humana ocorre, pois os que buscam a imagem inserem novos dados de busca, melhorando o algoritmo de forma que os novos dados aperfeiçoem, de forma semântica, as chances de acerto na busca pela solução correta.
- aprendizado não supervisionado: não se tem um resultado prévio (dados não rotulados), conforme já vimos nos algoritmos não supervisionados. Por ser mais complexo, a descoberta de padrões é sempre uma nova descoberta e depende das variáveis de entrada no sistema. Ex.: para descobrir hábitos alimentares, é necessário realizar um conglomerado de informações como frequência da compra de certos alimentos, registros de compras e perfil do cliente. Tudo isso deve ser associado para se chegar a um padrão. O algoritmo realiza essa associação de forma autônoma, sem a intervenção humana.
- aprendizado semissupervisionado: utiliza o algoritmo supervisionado, mas pode receber dados rotulados e não rotulados. Esse tipo de aprendizado é utilizado quando o custo com dados rotulados (aqueles em que o computador já conhece a resposta advinda desses dados) é muito caro e precisa de um treinamento rotulado. As respostas para as incertezas do algoritmo são pequenas e, assim, auxiliam no direcionamento de descobertas de padrões da máquina. Ex.: identificação do rosto de uma pessoa por meio do recurso de webcam. O rosto terá partes como dados rotulados e partes como não rotulados para o aprendizado (treinamento) que irão auxiliar a máquina na redução de erros para a sua identificação.
- aprendizado por reforço: não utiliza nenhum tipo de algoritmo (supervisionado ou não supervisionado). Ele é baseado em tentativa e erro e, a partir disso, analisa quais das suas ações tem os melhores resultados e as guarda para futuras iterações no algoritmo. Esse aprendizado é bastante empregado em áreas como robótica e jogos, em que o robô é lançado em um ambiente e faz diversos testes para coletar informações e se adaptar. Um outro exemplo é quando a máquina estrutura um portfólio de ações para investimentos; ela analisa o retorno financeiro e como o mercado está evoluindo naquele momento a fim de predizer a melhor solução de investimento, sem possuir nenhum treinamento prévio disso.
Com isso, temos diferentes tipos de aprendizados de máquinas, sendo que não há um melhor entre eles. Lembre-se de que as máquinas são programadas por humanos para executarem as tarefas que solucionem o problema. Diante disso, é o humano quem treina a máquina para escolher o melhor algoritmo para um determinado contexto.
Quando, em 1946, foi criado o primeiro sistema de computador, o ENIAC (Electronic Numerical Integrator and Computer), quase tudo era realizado pelos humanos, até mesmo a busca de conexões entre as diferentes partes do sistema para se obter um resultado. Nesse contexto, a máquina se equiparava apenas com as habilidades humanas em realizar cálculos matemáticos, porém, com maior desempenho (MAGNUS, 2018).
Já em 1950, o pesquisador e pai da computação, Alan Turing, começou a questionar se as máquinas poderiam pensar e começou a desenvolver o Teste de Turing, que realizava análises de interações entre a máquina e os seres humanos (MAGNUS, 2018).
A partir disso, um grande estudioso de Inteligência Artificial, Arthur Samuel, criou o primeiro sistema capaz de aprender a jogar damas. Samuel foi vencido pela máquina nesse jogo, em que a máquina ia melhorando suas jogadas e seu desempenho a cada nova partida, realizando estudos dos melhores movimentos no jogo e até mesmo propondo novas estratégias. Foi a partir disso que Samuel começou a empregar o termo “Aprendizado de Máquina”, em 1959 (SAS, on-line).
Outro grande software que ajudou a propagar o termo “aprendizado de máquina” nos anos 1960 foi a construção do sistema ELIZA, desenvolvido pelo professor Joseph Weizenbaum, do laboratório de Inteligência Artificial do Instituto de Tecnologia de Massachusetts (Massachusetts Institute of Technology – MIT). O objetivo desse sistema é a simulação de diálogos, como uma psicóloga, construindo novas perguntas com base no que o paciente informa. Muitos usuários acreditavam que a ELIZA era uma psicoterapeuta humana. Na Figura 4.9, tem-se o professor interagindo com ELIZA:

A partir desse contexto de origem, podemos perceber que a resposta à pergunta que Alan Turing fez (“As máquinas podem pensar?”) é: sim, as máquinas são capazes de reproduzir o raciocínio humano e estão cada vez mais inteligentes!
Vimos a Eliza em aprendizado de máquina, certo? Ela foi considerada o primeiro chatbot que simula diálogos, comportando-se como uma psicóloga, fazendo novas perguntas com base no que o paciente está falando naquele momento. Interessante não é mesmo? Se você tem facilidade com o inglês, acesse o link indicado e converse diretamente com a Eliza, em uma implementação desenvolvida em JavaScript, disponível em: http://www.masswerk.at/elizabot/. Acesso em: 26 fev. 2020.

Vale ressaltar, aqui, a diferença entre inteligência artificial (IA) e aprendizado de máquina. Em IA, temos que a máquina será programada para simular algumas características humanas, como reconhecimento de voz, percepção visual, traduzir idiomas e tomada de decisão com base em algum contexto. Já em aprendizado, os computadores são programados para aprender com os dados analisados e, assim, fornecer uma resposta mais exata. Apesar do aprendizado ser uma subárea de IA, em que todo aprendizado utiliza recursos de IA, nem toda IA tem o aprendizado automático da máquina (SAS, on-line).
Adicionalmente, o aprendizado de máquina tem a capacidade de adaptar-se, conforme é exposto, a outras quantidades de dados; isso faz com que ele seja um sistema dinâmico e não precise de especialistas humanos para realizar certas modificações no algoritmo. Por fim, a adoção de aprendizado de máquina só tende a aumentar e se tornar mais presente em aplicativos, assistentes digitais e na inteligência artificial de forma geral, haja vista que a demanda por dados e algoritmos está cada vez mais em expansão.
Analise as definições a seguir em relação aos tipos de aprendizado de máquina.
1) Supervisionado.
2) Semissupervisionado.
3) Não supervisionado.
4) Por reforço.
I - ( ) É um tipo de aprendizagem de máquina que investiga como agentes de software devem agir em determinados ambientes, utilizando técnicas de tentativa e erro.
II - ( ) É considerado um tipo de aprendizado de máquina que realiza o treinamento de dados rotulados para solução de uma tarefa, tendo a intervenção humana.
III - ( ) É um tipo de aprendizado de máquina que trabalha tanto com dados rotulados quanto com dados não rotulados, melhorando significativamente a acurácia.
IV - ( ) É classificado como um tipo de aprendizado de máquina em que a aprendizagem ocorre com dados não rotulados, ou seja, não dizemos ao computador o que é aquela entrada.
V - ( ) É uma forma de ensinar ao computador qual ação priorizar dada uma determinada situação, por meio de várias tentativas. Por reforço.
Em seguida, assinale a alternativa que relaciona cada item das descrições acima com o tipo de aprendizado de máquina de forma correta:
I - 1, II - 1, III - 2, IV - 3 e V - 4.
Incorreta. O item I não pode ser classificado como supervisionado, mas por reforço, posto que utiliza técnicas de tentativa e erro. O item II é supervisionado, pois há a supervisão humana nesse tipo de aprendizagem. O item III é semissupervisionado, pois a característica principal desse tipo de aprendizagem é trabalhar com os dois tipos de dados: rotulados e não rotulados. O item IV é não supervisionado, pois a máquina não sabe a classificação da entrada de dados e, assim, pode realizar previsões incalculáveis, sendo o resultado algo imprevisível. O item V é aprendizagem por reforço, pois são necessárias várias tentativas para que a máquina seja treinada.
I - 4, II - 3, III - 2, IV - 3 e V - 4.
Incorreta. O item I pode ser classificado como por reforço, posto que utiliza técnicas de tentativa e erro. O item II é supervisionado e não pode ser classificado como não supervisionado, pois há a supervisão humana nesse tipo de aprendizagem. O item III é semissupervisionado, pois a característica principal desse tipo de aprendizagem é trabalhar com os dois tipos de dados: rotulados e não rotulados. O item IV é não supervisionado, pois a máquina não sabe a classificação da entrada de dados e, assim, pode realizar previsões incalculáveis, sendo o resultado algo imprevisível. O item V é aprendizagem por reforço, pois são necessárias várias tentativas para que a máquina seja treinada.
I - 4, II - 1, III - 2, IV - 3 e V - 4.
Correta. O item I pode ser classificado como por reforço, posto que utiliza técnicas de tentativa e erro. O item II é supervisionado, pois há a supervisão humana nesse tipo de aprendizagem. O item III é semissupervisionado, pois a característica principal desse tipo de aprendizagem é trabalhar com os dois tipos de dados: rotulados e não rotulados. O item IV é não supervisionado, pois a máquina não sabe a classificação da entrada de dados e, assim, pode realizar previsões incalculáveis, sendo o resultado algo imprevisível. O item V é aprendizagem por reforço, pois são necessárias várias tentativas para que a máquina seja treinada.
I - 4, II - 1, III - 2, IV - 4 e V - 4.
Incorreta. O item I pode ser classificado como por reforço, posto que utiliza técnicas de tentativa e erro. O item II é supervisionado, pois há a supervisão humana nesse tipo de aprendizagem. O item III é semissupervisionado, pois a característica principal desse tipo de aprendizagem é trabalhar com os dois tipos de dados: rotulados e não rotulados. O item IV é não supervisionado e não pode ser classificado por reforço, pois não está sendo utilizado o método de tentativa e erro. O item V é aprendizagem por reforço, pois são necessárias várias tentativas para que a máquina seja treinada.
I - 1, II - 1, III - 2, IV - 3 e V - 4.
Incorreta. O item I pode ser classificado como por reforço, posto que utiliza técnicas de tentativa e erro. O item II é supervisionado, pois há a supervisão humana nesse tipo de aprendizagem. O item III é semissupervisionado, pois a característica principal desse tipo de aprendizagem é trabalhar com os dois tipos de dados: rotulados e não rotulados. O item IV é não supervisionado, pois a máquina não sabe a classificação da entrada de dados e, assim, pode realizar previsões incalculáveis, sendo o resultado algo imprevisível. O item V é aprendizagem por reforço, pois são necessárias várias tentativas para que a máquina seja treinada.
Agora que entendemos melhor o que é machine learning e seus diferentes tipos de aprendizados de máquina, que constituem a base do funcionamento dessa área, veremos quais os principais métodos estatísticos que auxiliam no alcance dos objetivos esperados ao utilizar esse tipo de aprendizado.
No aprendizado de máquina, são utilizados diversos métodos estatísticos, que também são empregados pelos cientistas de dados, a depender do problema a ser solucionado e, assim, alcançar o desempenho que se espera na utilização do método selecionado. Vejamos, a partir de agora, os três principais métodos (SILVA et al., 2007).
Esse tipo de método é aplicável em algoritmos supervisionados com o objetivo de prever os resultados em uma saída de forma contínua, com base no mapeamento das variáveis de entrada (dados rotulados), ou seja, realiza-se uma análise das variáveis de entrada para descrever as suas características e, assim, prever uma saída contínua, aquela que possui somente uma categoria e já é conhecida com base nos dados rotulados.
Na Figura 4.10, temos um exemplo de gráfico gerado em uma regressão linear, em que, no eixo x, temos as variáveis independentes (dados de entrada) e, no eixo y, as variáveis dependentes (dados de saída). Os pontos dos dados plotados permitem a construção da linha de regressão, que, por sua vez, permite a predição de valores de saída para um certo valor de entrada.
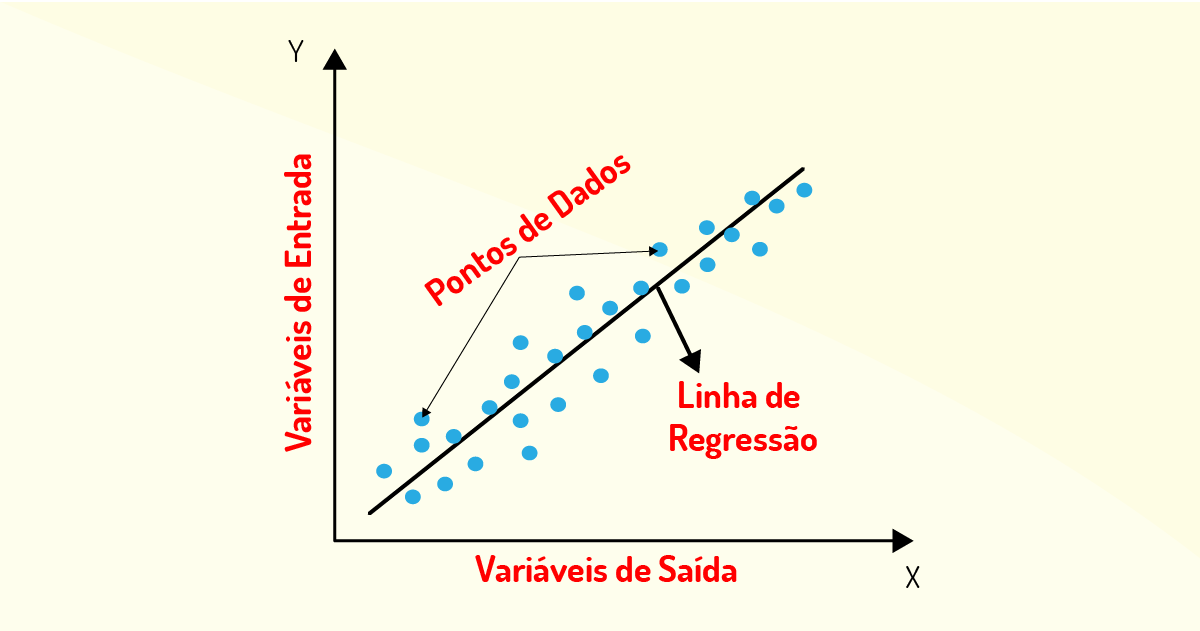
Vejamos, a seguir, dois exemplos para clarificar melhor o uso da regressão.
Em um contexto imobiliário, recebe-se como dado de entrada o tamanho das casas e é solicitada a previsão de preço. Logo, sabe-se que existe uma relação entre tamanho da casa e preço, e o algoritmo só vai ratificar essa relação. A saída será contínua, pois será determinado o preço da casa conforme a média dos tamanhos. Assim, é um problema de regressão que vai buscar mapear o tamanho das casas para se chegar a um preço ideal.
Um outro exemplo que podemos citar é que podemos ter como variáveis de entrada a imagem de um homem ou mulher, sendo necessário informar uma saída, já conhecida, que é a idade. O método de regressão, então, analisa os dados da imagem e fornece uma saída contínua, que é a idade.
É importante frisar que o método da regressão faz o mapeamento procurando entender como as variáveis de entrada podem evoluir para gerar uma saída contínua. A ideia é encontrar uma saída que seja a média das oscilações que ocorrem ao analisar as entradas fornecidas.
Por fim, o método da regressão procura analisar de que forma ocorre a relação entre duas ou mais variáveis classificadas como quantitativas e, assim, tentar prever uma saída com base nessa relação.
É um tipo de método aplicável a algoritmos supervisionados em que o intuito é prever duas ou mais saídas com base nos dados rotulados de entrada, ou seja, será realizado um mapeamento das variáveis de entrada, agrupando-as em diferentes categorias para se chegar às saídas correspondentes.
Na Figura 4.11, temos um exemplo de gráfico utilizado pelo método de classificação, em que os dados de entrada são classificados nas categorias classe A e classe B.
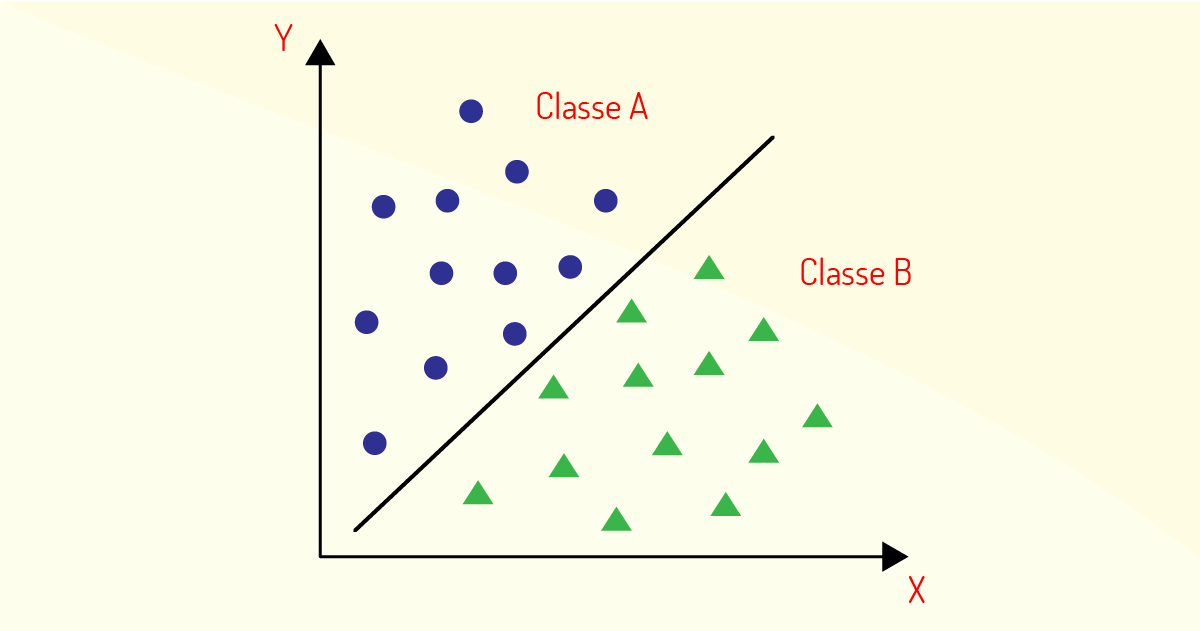
Vejamos, a seguir, dois exemplos para ilustrar melhor o método da classificação.
Ainda no contexto imobiliário descrito acima, ao utilizar o método de classificação, com base nos dados fornecidos como tamanho da casa, o método iria agrupar as casas em que possuem um determinado tamanho e seriam classificadas com um preço abaixo do que foi estipulado como saída e as casas com tamanhos maiores estariam classificadas com um preço acima dessa saída.
Um outro exemplo da classificação, pode ser utilizado na oncologia, em que se conhece um tumor cancerígeno por algumas variáveis de entrada como tamanho e forma, e, com base nisso, tenta-se prever se o tumor é maligno ou benigno. A classificação vai categorizar os dados de entrada (tamanho e forma) para se chegar à conclusão do tipo de tumor.
Vale ressaltar que esse tipo de método busca analisar, entender e realizar previsões de variáveis em categorias e não quantitativas, como ocorre nos métodos de regressão. Essas categorias podem ser do tipo:
- binárias: que possuem somente duas categorias: ou é 1 (um), que significa que um evento ocorreu, ou 0 (zero), em que não existe ocorrência de evento.
- faixas: em que os dados são classificados por faixas que podem ser de idade, de renda, de escala, dentre outras.
- categóricas não ordenadas: em que cada categoria possui uma variável única em comparação com outras categorias, como exemplos têm-se gênero, cor, raça, entre outras.
Adicionalmente, o método de classificação recebe um dado de entrada e tenta atribuir algum rótulo a essa entrada, para, assim, classificar e realizar as previsões de saída. Geralmente, as respostas são simples e correspondem a “sim” ou “não”.
Por fim, o método da classificação é muito utilizado quando se tem um objetivo bem descrito e as saídas conhecidas, para que assim seja utilizado o algoritmo de aprendizagem supervisionada e poder informar resultados com base em categorias e não numéricas.
Esse tipo de método é aplicável a algoritmos não supervisionados, em que não se tem ideia do que os resultados podem apresentar, com base em um banco de dados. Além disso, esse método busca encontrar padrões e os dados só serão agrupados conforme se encontram as relações entre as variáveis.
Na Figura 4.12, temos um exemplo de gráfico que representa o processo do algoritmo de clustering, em que os dados que apresentam algum padrão são agrupados em clusters (no caso, cluster 1, cluster 2 e cluster 3).
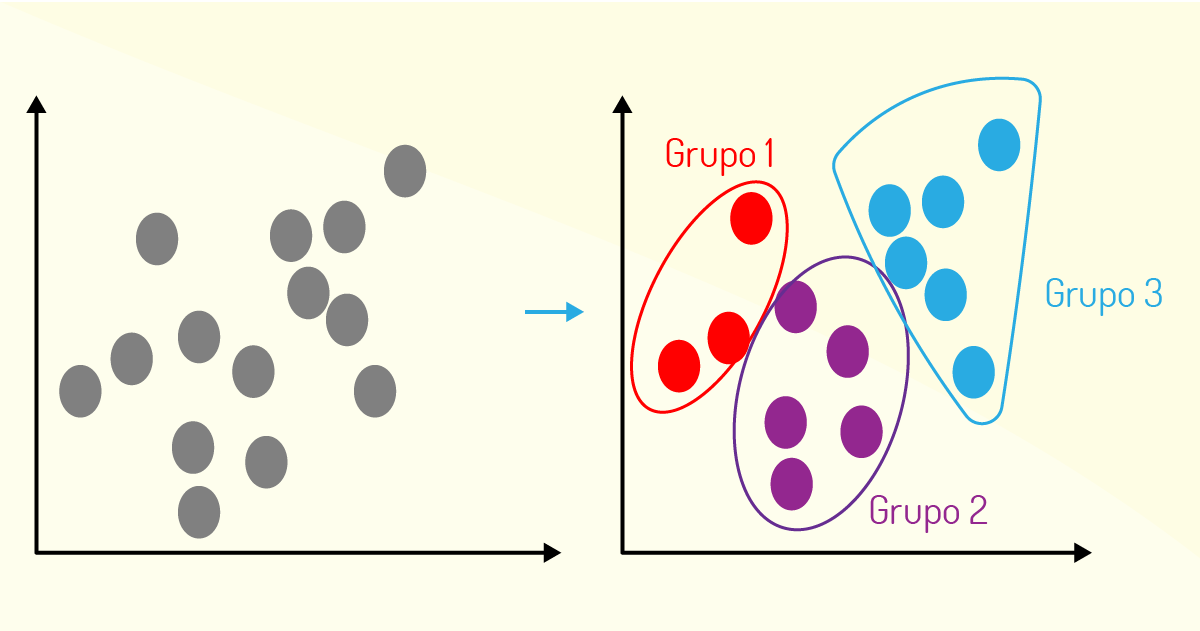
Além disso, esse método pode ser bastante útil quando se deseja reduzir o espaço amostral, dado um conjunto de dados para se ater somente nos atributos que têm relevância para o problema, ou até mesmo realizar detecção de tendências.
Vejamos, a seguir, um exemplo para exemplificar melhor o uso do método.
Caso você tenha uma coleção de 500 pesquisas realizadas por uma universidade e deseje encontrar uma maneira de agrupá-las, o método de Clustering pode auxiliar fazendo o agrupamento a partir de grupos que podem ser semelhantes, ou não, e que estariam relacionados por algumas variáveis, como número de páginas, frequência de palavras, frases, entre outras.
Um outro exemplo é a aplicação do algoritmo Cocktail Party, que consiste encontrar um padrão com base em uma estrutura de dados desorganizada. Esse algoritmo também é conhecido como separação de sinais de áudio. Caso você tenha duas pessoas conversando em uma sala, ambas utilizando um microfone com captação de áudio, o algoritmo tentará agrupar (Clustering) as vozes das pessoas e, assim, dizer de quem é cada voz (SILVA et al., 2007).
Por fim, o método do Clustering pode gerar saídas que podem nem ser explicáveis, posto que as relações entre os dados de entrada ainda serão criadas e analisadas. Dessa forma, vários clusterings (agrupamentos) podem ser criados e, assim, serão utilizados somente aqueles que respondem ao problema descrito.
Agora que você entendeu os principais métodos em machine learning, pode selecionar o método mais adequado para o contexto do problema, tendo como ponto principal a pergunta de negócio que será respondida e, a partir das análises encontradas com o método, poder gerar valor com essa informação. O método é apenas o meio para se encontrar a resposta da pergunta do problema informado.
Portanto, com base no que você já sabe dos algoritmos, tipos de aprendizado de máquina e classificação dos métodos utilizados em machine learning, vamos entender como funciona o fluxo do processo de aprendizado de máquina. Vamos lá!
O processo de aprendizado de máquina possui um fluxo que consiste em fornecer etapas de forma sequencial, que provê um aprendizado de forma automatizada para que, assim, consiga chegar às respostas de forma mais eficiente (MOHRI; ROSTAMIZADEH; TALWALKAR, 2012, p. 89). Vide Figura 4.13:
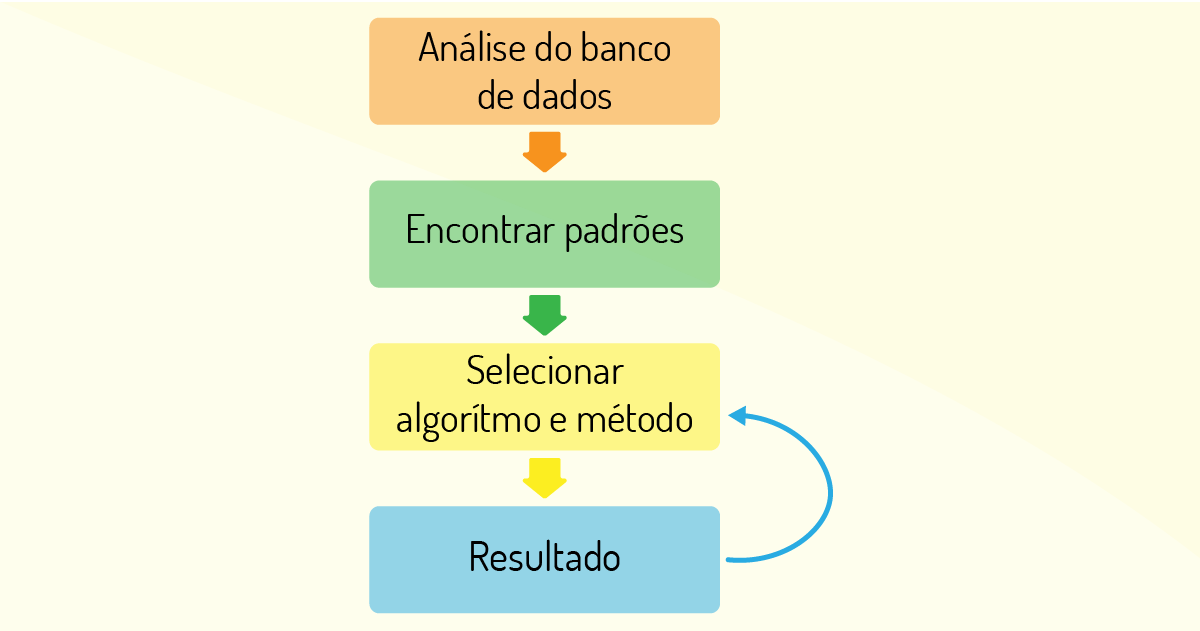
O primeiro passo é ter um banco de dados que possua uma certa qualidade dos dados, pois isso influencia nas respostas. Para tanto, pode ser necessário um pré-processamento dos dados, para que possa ser realizado um tratamento, em especial para dados de diferentes fontes, com diferentes formatos, desconhecidos ou incompletos. Se o banco de dados for automatizado, erros básicos serão evitados, como erros de digitação, valores errados, entre outros. Há uma relação direta entre a quantidade de dados de qualidade e a precisão da aprendizagem, pois, quanto maior for a quantidade desses dados, maior será a aprendizagem do sistema e com muito mais precisão.
Em seguida, os dados são separados em duas amostras: uma base para treinamento e outra para verificação do desempenho do modelo treinado. Na base de treinamento, os dados serão analisados, e o sistema tenta encontrar padrões nas relações (existentes ou não) entre as variáveis e passa a aprender com esses dados. Aqui, a máquina está em processo inicial de treinamento e tem os seguintes objetivos: o que e como procurar essas relações, o que pode ser encontrado e como irá encontrar o resultado.
Por conseguinte, selecionando o modelo (algoritmo e o método adequado), a máquina é capaz de realizar predições. Nesse momento, ela realiza apenas uma previsão, pois está aprendendo. O treinamento ocorre por meio de ciclos iterativos, aprendendo com os erros, sendo que cada resultado gerado pode ser ajustado e melhorado para que a máquina se aperfeiçoe em suas previsões e seja mais preciso em suas avaliações. A base de verificação, que contém dados não conhecidos e diferentes da base de treinamento, deve ser utilizada para avaliar a eficácia do modelo, que tem como objetivo atingir um nível de acerto almejado.
Por fim, quando a máquina passa a gerar resultados mais precisos e confiáveis com base nesse fluxo e sem a interferência de melhorias em seus resultados, tem-se que a máquina de aprendizagem está utilizando o processo de forma automatizada.
Analise a situação a seguir:
“A partir de dados de animais em um zoológico, deve-se aproximar animais por suas características, ou seja, a partir dos dados como ‘quantidade de pernas’, ‘quantidade de dentes’, ‘põe ovo’, ‘tem pelos’ e vários outros, procuramos animais que estão mais próximos. Poderíamos, assim, separar animais em mamíferos, aves ou répteis, mas sem ‘contar’ ao algoritmo sobre estas classificações. Apenas comparando a distância entre dados o algoritmo mostraria que um tigre está “mais próximo” de um leão do que de uma garça” (HONDA, 2017, on-line)
Nesse contexto, pode-se utilizar que tipo de método estatístico de aprendizado de máquina?
Regressão.
Incorreta. Esse tipo de método utiliza dados rotulados, isto é, aqueles que são informados ao algoritmo.
Classificação.
Incorreta. Utiliza dados não rotulados (não são informadas as entradas para o algoritmo) e precisa da intervenção humana.
Supervisionado.
Incorreta. Não é um tipo de método estatístico, mas, sim, de aprendizado de máquina.
Aprendizagem por reforço.
Incorreta. Não é um tipo de método estatístico, mas, sim, de aprendizado de máquina.
Clusterização.
Correta. Os dados não rotulados só serão agrupados (Clustering) conforme são encontradas as relações entre as variáveis.
Uma das tecnologias envolvidas na área de Machine Learning é o que está sendo denominada como Deep Learning. Na seção seguinte, serão apresentados a você a definição, o funcionamento e alguns aspectos relevantes dentro dessa área. Vamos começar!
Em português, o termo é traduzido como aprendizagem profunda, a qual é uma subcategoria do aprendizado de máquina e tem como objetivo realizar aprendizagens profundas e extensas com o uso de redes neurais (DEEP LEARNING, on-line).
Outra definição pode ser descrita como o treinamento de um modelo da computação que utiliza algoritmos para realizar o processamento dos dados e imitar esse processamento como se fosse um cérebro humano (DEEP LEARNING, on-line).
Os algoritmos utilizados pela deep learning são bem mais complexos dos que os que são empregados em machine learning e estão baseados nos princípios das redes neurais (como já vimos nesta unidade) para que possa simular o processamento de um cérebro humano com muito mais fidelidade e precisão, no que se refere à forma como as informações são compreendidas e quais resultados são gerados a partir dessas informações (DEEP LEARNING, on-line).
Outras tarefas inerentes aos seres humanos podem ser realizadas com a deep learning, como: reconhecimento de fala, percepção, detecção de imagens, realizar previsões, entre outros. Para isso, a deep learning realiza configuração de alguns parâmetros sobre os dados de entrada e faz com que a máquina seja treinada para que aprenda a reconhecer, sozinha, todos os padrões estabelecidos em várias camadas de processamento.
Vale ressaltar que tanto a deep learning quanto o machine learning são os pilares da Inteligência Artificial (IA) e que fazem com que a área de IA esteja evoluindo e se propagando de forma rápida e que viabilizam a aplicação de IA no nosso dia a dia. A Figura 4.14 expõe essa relação entre as áreas (DEEP LEARNING, on-line):
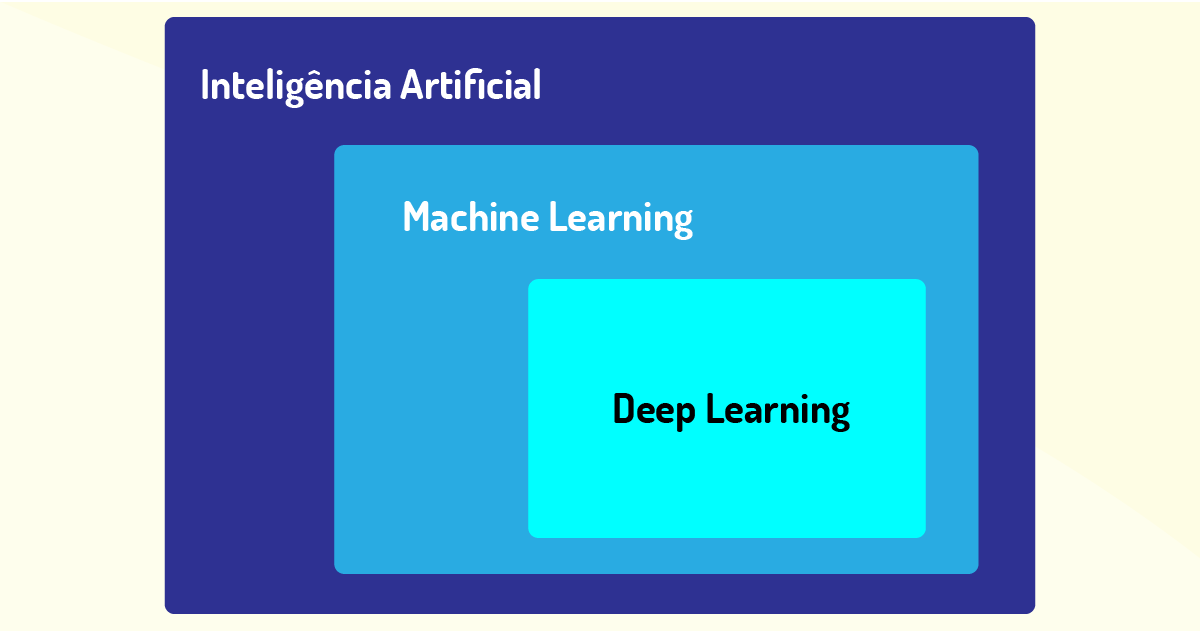
Conforme se percebe na imagem, a área de IA engloba as duas outras áreas e que deep learning é uma subárea dentro de machine learning, já que, como o próprio nome diz, é uma aprendizagem profunda do aprendizado de máquina.
E como funciona a deep learning? Após receber uma grande quantidade de dados, a deep learning utiliza um modelo computacional para relacionar os termos e as palavras encontrados na análise dos dados para inferir significados e, assim, decifrar a linguagem natural (DEEP LEARNING, on-line).
Esse modelo computacional possui uma série de camadas de neurônios que são utilizados para diversos fins, como processar os dados e reconhecer a fala humana e objetos de forma visual. Assim, a primeira camada de neurônio (de entrada) recebe a informação e passa para as camadas seguintes, denominadas de camadas ocultas que recebem a informação da camada anterior, realizam o processamento e repassam para a camada seguinte, até gerarem um resultado na camada de saída (DEEP LEARNING, on-line).
Cada camada possui um algoritmo simples para realizar o processamento computacional e possui uma determinada função, que lhe foi atribuída para que possam ser treinadas e, assim, gerarem um resultado esperado. Vale ressaltar que uma rede neural simples possui apenas uma camada oculta, enquanto a deep learning possui N camadas ocultas, conforme podemos visualizar na Figura 4.15 (DEEP LEARNING, on-line):
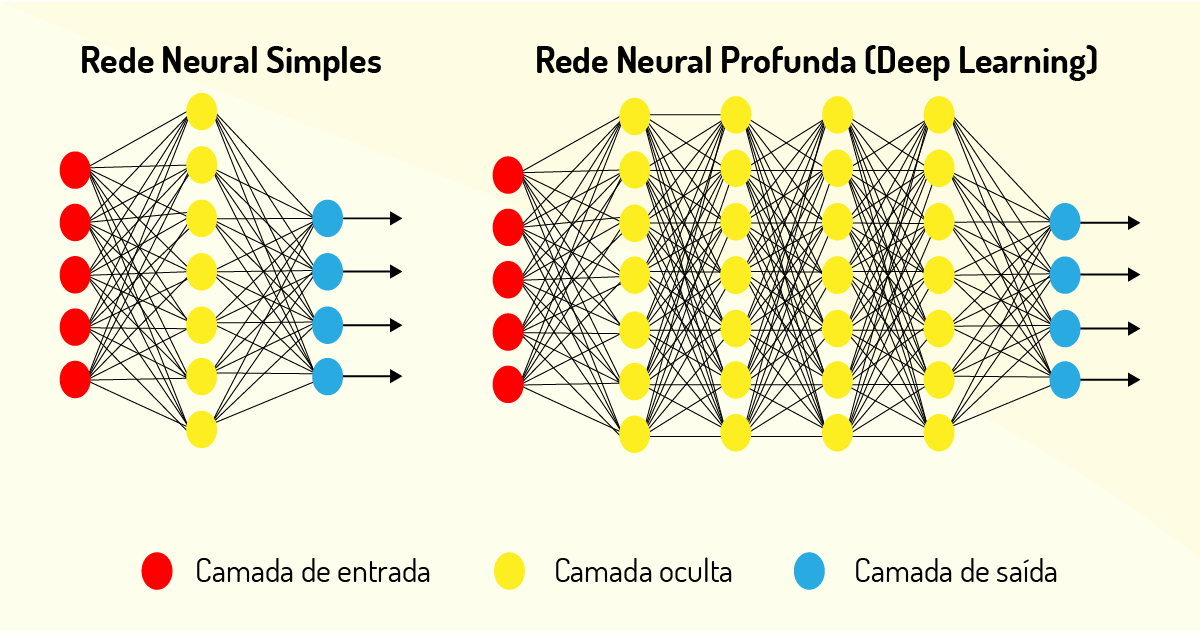
Por meio da Figura 4.15, pudemos descrever melhor que os dados são submetidos a diversas camadas não lineares de processamento. Esses neurônios artificiais das camadas de deep learning são capazes de realizar diversas atividades humanas e complexas, sem a necessidade da intervenção de um humano neste processamento.
Além de se basear em redes neurais simples, outra característica importante da deep learning é a extração de recursos dos dados brutos, a qual utiliza um algoritmo para construir, de forma automática, os recursos essenciais dos dados para que seja possível treinar e prover aprendizado e compreensão da rede neural. Esses recursos são aprendidos de forma hierárquica em camadas, sendo que na camada inicial são aprendidos os recursos de baixo nível, obtendo um nível de abstração maior à medida que sobe na hierarquia. Na Figura 4.16, temos um exemplo de extração de recursos, como valores médios de pixels, forma, textura, cor, posição e orientação e os respectivos níveis de abstração. Essa extração de recursos feita pelo algoritmo é supervisionada, seja pelo cientista de dados ou pelo engenheiro de IA.

Por conseguinte, um exemplo prático da deep learning foi realizado pela empresa Google em seu sistema de tradução. Com apenas aprendizado de máquina, a tradução era feita considerando apenas as palavras do texto, o que muitas das vezes não fazia sentido para o contexto da frase. Então, para solucionar isso, a Google implementou o Google Neural Machine Translation (GNMT), com base na deep learning, que traduz frases completas e as adapta conforme o contexto do texto. Assim, o serviço de tradução tornou-se mais preciso e inteligente (DEEP LEARNING, on-line).
Por fim, podemos perceber que as duas áreas Deep Learning e Machine Learning tornaram-se a essência de processamento para que as máquinas se tornem cada vez mais inteligentes e possam evoluir de forma muito rápida e sem intervenção humana.
Vejamos, agora, algumas ferramentas que utilizam o aprendizado de máquina para prover funcionalidades, seja para aplicativos individuais, seja para soluções complexas.
Por fim, temos uma pequena amostra das ferramentas que utilizam os algoritmos de aprendizado de máquina em diferentes linguagens para diversos contextos. Não existe a ferramenta correta, mas, sim, a ideal que vai se propor a solucionar da melhor maneira o problema que precisa ser resolvido dentro do aprendizado de máquina.
O uso da ferramenta e biblioteca adequada é importante para um projeto de aprendizado de máquina. Para tanto, é sugerida a busca de maiores detalhes sobre cada recurso disponível no mercado, para que comparações possam ser feitas tanto do ponto de vista técnico como no modelo de negócio.
Seguem os links com informações sobre as principais ferramentas e bibliotecas mencionadas nesta unidade:
É considerada uma subárea do aprendizado de máquina e tem como objetivo simular a rede neural do cérebro humano, por meio da utilização de algoritmos de alto nível. O contexto apresentado no enunciado da questão refere-se à(ao):
inteligência artificial.
Incorreta. Inteligência Artificial é a área de ciência da computação concentrada em criar programas e máquinas que podem exibir comportamentos considerados inteligentes.
machine learning.
Incorreta. Aprendizado de máquina é a utilização de algoritmos para estruturar os dados e reconhecer padrões para que o computador aprenda a solucionar um problema.
deep learning.
Correta. É a parte do aprendizado de máquina que, por meio de algoritmos de alto nível, imita a rede neural do cérebro humano.
ciência de dados.
Incorreta. É um campo interdisciplinar que utiliza métodos, processos, algoritmos e sistemas científicos para extrair valor dos dados.
aprendizado por reforço.
Incorreta. Não é uma subárea do aprendizado de máquina, mas, sim, um tipo de aprendizado.
Agora chegou o momento de apresentarmos alguns exemplos práticos utilizados por empresas, as quais estão se apropriando dos conhecimentos da área de machine learning para realizar melhorias ou, até mesmo, inovações em seus processos.
Case 1: General Eletric (GE, on-line)
A General Eletric é uma empresa multinacional com sede global em Boston, nos EUA, tendo como objetivo desenvolver soluções para as áreas de: transporte, saúde, iluminação e energia.
Em seu processo produtivo automatizado por máquinas, as quais possuem gêmeas digitais que seriam as réplicas de forma virtual dos equipamentos físicos, o objetivo é simular o comportamento da máquina física e, assim, aprender os diferentes estados que as máquinas possuem mediante um contexto.
Se a máquina de verdade apresentar algo considerado fora do normal, seja um aumento de calor, emissão de ruídos e vibrações inconsistentes, isso é coletado por sensores na gêmea digital e armazenado na nuvem. A partir disso, o aprendizado de máquina é ativado, para determinar o que fazer mediante essa situação anormal.
Além disso, há uma simulação dessa situação anormal na gêmea digital para saber se a réplica induz que essa anormalidade pode acarretar alguma falha no processo produtivo ou até mesmo sugerir manutenções nas máquinas físicas.
Case 2: JPMorgan (JPMORGAN, on-line)
O grupo JPMorgan é um banco americano e líder mundial em serviços financeiros e oferece esses serviços a governos, corporações e instituições em mais de 100 países. Os serviços oferecidos são: investiment bank, global corporate bank, asset management, private banking e treasury & securities services. Para os clientes, o banco oferece uma gama de serviços que se propõe a combinar conhecimento especializado com técnicas avançadas de liderança para os negócios do cliente.
Uma das grandes tarefas que não era automatizada nesse banco era a análise e interpretação de acordos realizados em empréstimos comerciais. Essa tarefa era realizada por advogados, pois era necessário analisar algumas cláusulas contratuais para que a empresa já se respaldasse mediante alguns processos realizados pelos clientes.
A empresa, então, resolveu criar um algoritmo baseado em machine learning, que realizou essa tarefa em segundos, quando os advogados humanos precisavam de mais ou menos 360 mil horas por ano. Esse foi um grande avanço de melhoria nessa rotina, e os advogados tendem a realizar outras rotinas de análise na empresa.
Case 3: Tati (TATI..., on-line)
O aplicativo para smartphones nomeado como Tati tem o objetivo de fornecer uma série de recursos de estudos para os alunos, mediante suas dificuldades apresentadas no aplicativo.
Tati foi desenvolvida pela empresa Conexia Educação, que se propõe a oferecer uma gama de soluções educacionais pertencentes ao grupo SEB. O aplicativo tem seu funcionamento realizado por meio de computação cognitiva, a qual permite a simulação de um atendimento virtual como se fosse um humano e ainda auxilia no aprendizado dos estudantes no aplicativo.
Adicionalmente, Tati utiliza machine learning quando observa e analisa as quantidades de dados que lhe são fornecidas pelo aplicativo e, após aprender com esses dados, transmite o conhecimento que aprendeu a partir da relação encontrada, por exemplo: dificuldade do aluno e rotina de estudos para aumentar o aprendizado.
Hoje em dia, Tati realiza os atendimentos aos alunos do ensino médio, nas dificuldades de disciplinas como história, geografia, matemática entre outras, mas futuramente, poderá ser integrada para alunos do ensino superior, por meio da descrição das competências e habilidades que devem ser analisadas por Tati nesse contexto.
Case 4: Plataforma SAGAH (SAGAH, on-line)
A SAGAH é uma ferramenta de cunho educacional desenvolvida pelo Grupo A, a qual provê soluções educacionais customizadas para as empresas e instituições de ensino. Possui um portfólio de negócios com o foco na educação, fazendo a integração de conteúdos, tecnologias e serviços.
Por meio do machine learning, a SAGAH possui uma plataforma adaptável para realizar o nivelamento dos seus estudantes em disciplinas como português e matemática. A plataforma reconhece as dificuldades dos alunos sobre os exercícios ofertados e, assim, fornece algumas recomendações para sanar tais dificuldades.
E como funciona? A plataforma disponibiliza uma lista de exercícios com o objetivo de identificar as principais dificuldades do aluno assim que ele inicia a graduação. Com base na pontuação do aluno (dados de entrada), o sistema analisa e procura uma recomendação que pretende diminuir esse gap de dificuldade com a disciplina da lista de exercício.
Um exemplo que podemos citar é: para o nivelamento de matemática, há atividades referentes aos assuntos logaritmo, exponencial e regra de 3. O aluno realiza esses exercícios e, se a máquina perceber que o aluno não acertou nenhuma das questões ou se está abaixo da média que precisa para o exercício, a máquina sugere uma série de vídeos e outros materiais que auxiliam o aluno.
O propósito da ferramenta é simular um professor que percebe que o aluno tem dificuldade em tal assunto e, assim, sugere alguns recursos educacionais para melhorar seu aprendizado. Vale ressaltar que a plataforma não pretende substituir os professores humanos, pois estes são necessários para explorar o potencial da tecnologia e, assim, poder implementar para cada aluno que tem dificuldade. Isso faz com que a aula se torne mais dinâmica e faz uma aproximação entre docente e discente, em que ambos têm melhorias em seus desempenhos, seja para uma aula mais atrativa (para o professor) ou melhoria do aprendizado da disciplina (para o aluno com a aula mais dinâmica).
Case 5: Waze (WAZE, on-line)
O aplicativo Waze tem o propósito de indicar as melhores rotas de caminho terrestre a partir das informações dos seus usuários. Ele já é bastante popular entre as pessoas que dirigem carros e cada vez mais as pessoas o fazem de um recurso principal no momento de escolher uma rota, principalmente em horários de rush.
A essência do funcionamento do aplicativo consiste em receber as informações de tráfego dos usuários em uma mesma rota e, assim, o aplicativo recomenda ou não, que se utilize essa via para se chegar ao seu destino.
Os humanos não conseguiriam, em tempo real, processar toda essa informação e fazer as devidas sugestões de melhor caminho, porém, os algoritmos conseguem realizar isso em tempo hábil, 24 horas por dia.
O aprendizado de máquina no Waze está relacionado ao fato de que o aplicativo tem a capacidade de aprender por conta própria as informações retiradas das análises dos dados e, assim, prover informação útil aos seus usuários.
O resultado do machine learning fornece resultados cada vez mais precisos, rápidos e eficientes, mesmo que se tenha uma grande massa de dados para serem analisados; conforme os usuários inserem informações no aplicativo, os riscos são bem menores do que se fossem realizados exclusivamente por seres humanos.
Agora que já vimos alguns cases de sucesso, vejamos alguns exemplos de usos de aprendizado de máquina, que podem ser aplicados em diversas áreas.
Aqui, vimos muitos exemplos de cases e usos relacionados ao aprendizado de máquina. É importante frisar que o mundo está cada vez mais tecnológico, e aquele que detém a tecnologia a seu favor está dando um passo mais adiante no processo de inovação tecnológica e, por mais que as máquinas substituam muitas tarefas realizadas exclusivamente por seres humanos, serão necessários humanos que saibam descobrir as melhores oportunidades no benefício da tecnologia.
Em sistemas de recomendação de compras on-line, são utilizados mecanismos de aprendizado de máquina. É quase inacreditável o fato de que o programa sabe qual produto você tem mais chances de comprar! De que forma esses sistemas estão utilizando aprendizado de máquina?
Por meio do histórico de compras anteriores e visualização de determinados produtos.
Correta. Os sistemas de aprendizado de máquina são capazes de prever itens que você pode gostar, de acordo com suas compras anteriores ou hábitos de visualização.
Criando uma rede neural para entender o perfil do consumidor.
Incorreta. Dessa forma seria deep learning, que consiste na utilização de redes neurais artificiais, e não machine learning, que é a forma como a máquina aprende a solucionar um problema.
Simulando um consumidor que realiza compras on-line.
Incorreta. Isso seria para treinar uma rede neural, que teria o comportamento de um consumidor que realizaria compras on-line de forma automática.
Analisando grande quantidade de dados de perfis de consumidores de produtos on-line.
Incorreta. É utilizado como técnicas de análise de dados em ciência de dados, que visam categorizar os dados para, assim, gerar informação relevante.
Com base na forma de pagamento do consumidor.
Incorreta. O objetivo não é analisar a forma de pagamento, mas, sim, os produtos que serão comprados pelo consumidor.
Nome do livro: Aprendizado de máquina para leigos
Editora: Alta Books
Autores: John Paul Mueller e Luca Massaron
ISBN: 8550802344
Este livro é bem didático para quem está iniciando na área de aprendizado de máquina, com discussões explicadas sobre o funcionamento dos algoritmos básicos de aprendizado de máquina, utilizando as linguagens Python e R. O livro apresenta vários exemplos práticos que aplicam a utilização desses algoritmos.
