Tópicos Especiais em Sistemas de Informação
Caro(a) aluno(a), imagine a seguinte situação: você acorda pela manhã com a sua assistente pessoal lhe despertando e desejando “bom dia” ao som da música que você quer escutar. Ela também já analisa as melhores notícias para que você esteja atualizado sobre o que está ocorrendo em sua região e pelo mundo. Quando você está escovando os dentes, ela analisa sua caixa de e-mails e já o notifica sobre quais e-mails importantes você precisa ler, quais reuniões precisa participar e lembra, também, do aniversário de sua mãe. Além disso, a assistente já envia como está o fluxo de trânsito e em qual horário você chegará ao trabalho. Ela também já preparou seu café da manhã e já deixou o carro na melhor direção para o momento de sua partida. Por fim, se despede e lhe deseja um bom retorno para casa.
É esse o contexto do nosso assunto: a Inteligência Artificial (IA). Com essa abordagem, percebemos que o assunto pode ser aplicado no nosso dia a dia de forma bem simplista. É possível perceber, também, que a análise humana ficou a cargo totalmente da assistente pessoal, e é isso que um dos ramos da inteligência artificial pretende: tarefas que antes eram atribuições somente humanas passam a ser realizadas por máquinas. Não é fantástico? Mas, para que tudo isso ocorra, é necessária uma série de recursos que possibilitam o crescimento e a aplicação da inteligência artificial, como: algoritmos, redes neurais, conceitos atrelados à inteligência humana, entre outros. Veremos alguns desses recursos em nossos próximos tópicos. Preparado(a)? Vamos começar!
É comum que muitos se assustem com a ideia de termos uma máquina com características do ser humano, como o ato de pensar e se movimentar. Porém, essa é uma realidade cada vez mais presente no cotidiano das pessoas, sobre a qual muitos estudos estão sendo realizados em todas as partes do mundo, envolvendo diferentes disciplinas do conhecimento humano e a computação, no campo denominado Inteligência Artificial.
A evolução da IA, atrelada ao poder computacional, começou nos anos 1930, quando Alan Turing (Figura 3.1), que trabalhou no escritório de decodificação de mensagens da Inteligência Britânica, forneceu uma visão matemática à ciência da computação e, a partir disso, a computação pôde se expandir, não se restringindo à visão limitada de uso para operações de cálculos matemáticos (MEDEIROS, 2018).

Tudo começou com o experimento de Turing, conhecido como a máquina de Turing: era a Segunda Guerra Mundial, e os alemães, que estavam em vantagem computacional, possuíam uma máquina chamada Enigma, a qual escrevia mensagens alemãs com rotores, que mudavam seus códigos diariamente. Isso servia como forma de embaralhar as mensagens trocadas pelas tropas alemãs de Hitler. Caso alguém desvendasse esse segredo, era capaz de ler essas mensagens. A única saída era utilizar a mesma chave de encriptação original, a qual era trocada mensalmente pelos rotores e formulavam milhares de combinações (ALAN..., on-line).
De forma similar à máquina Enigma, as mensagens trocadas via aplicativo WhatsApp baseiam-se nesse tipo de criptografia, em que uma pessoa precisa ter a chave para poder ler a mensagem trocada no aplicativo.
Você pode entender melhor sobre isso em: https://faq.whatsapp.com/pt_br/android/28030015/. Acesso em: 20 fev. 2020.

Nesse contexto, Turing e sua equipe conseguiram descobrir como decifrar a máquina Enigma utilizando uma técnica eletromecânica nomeada de “bombas”, com mecanismos que permitiam a análise simultânea de muitos textos em uma velocidade superior aos humanos. Por exemplo, os ingleses passaram a ler mais de 50 mil mensagens por mês, em que cada mensagem era lida em 1 minuto (ALAN…, on-line). Dessa forma, os ingleses conseguiram ler todas as mensagens trocadas entre as tropas alemãs e, assim, surgiu a máquina de Turing (Figura 3.2):

Uma grande contribuição da máquina é o Teste de Turing, criado em 1950, que serve para identificar uma IA, em que, durante uma conversa textual, por um longo período de tempo, se não for possível classificar o sujeito com quem se comunica, entre humano ou IA, o sistema é considerado um autômato inteligente (ALAN..., on-line).
Com base nesse contexto, a IA se apoia nisso, quando utiliza o computador para processar símbolos de maneira eficiente e eficaz. A modelagem dos processos de IA pode ser feita primeiramente no papel, mas, depois, é necessária a automatização disso para se fazer analogias completas e complexas com o cérebro, utilizando, para isso, uma linguagem de símbolos.
Em uma visão generalizada, a computação engloba tudo o que é um processo efetivo, com o objetivo de obter um resultado, seja por meio de padrões, símbolos e desde que estes estejam bem-definidos no processamento computacional. E, assim, o computador é utilizado como recurso para executar todo esse processo.
Mas o que vem a ser IA? Vejamos algumas definições:
Todas essas definições visam tentar simplificar o conceito de IA, o que é bem difícil. Pode-se basear em um conceito genérico que envolve o estudo de capacidades humanas apoiadas pelo uso do processamento computacional de símbolos.
Adicionalmente, ao longo da evolução de IA, ela foi dividida em quatro grandes linhas de pensamento baseadas na divisão de sistemas, que são (RUSSEL; NORVIG, 2013):
I. Sistemas que pensam como seres humanos: nesse tipo de sistema, tem-se todo o conhecimento acerca do funcionamento da mente humana, como tomadas de decisão, resolução de problemas e aprendizagem, e essas teorias são executadas em programas de computador. A ciência cognitiva apresenta modelos computacionais da IA e técnicas experimentais da psicologia para a construção de teorias dos processos de funcionamento da mente humana. Um exemplo de sistemas que pensam como seres humanos são as redes neurais artificiais.
II. Sistemas que agem como seres humanos: essa linha está relacionada a sistemas que requerem a atuação como humanos no sentido comportamental. A inteligência, aqui, é criada para executar funções que também podem ser executadas por humanos. Um exemplo é o Teste de Turing, em que o computador deve ter as capacidades de processamento de linguagem natural, representação de conhecimento, raciocínio automatizado e aprendizado de máquina, a fim de responder a questionamentos como um ser humano.
III. Sistemas que pensam de forma racional: o sistema é considerado racional se faz uso da notação lógica, simulando o pensamento lógico racional do ser humano, dentro das limitações dos recursos computacionais. Um exemplo de sistema que pensa de forma racional são os sistemas inteligentes.
IV. Sistemas que agem de forma racional: esse tipo de sistema requer um agir racional, que consiste na utilização de um agente, o qual é uma entidade com sensores que percebe o ambiente e possui algumas formas de pensar racional programadas, para que, assim, possa tomar a ação correta no intuito de atingir um objetivo proposto. Um exemplo que podemos citar é a criação de agentes inteligentes para completar formulários de busca de passagens aéreas, ao invés do cliente com o objetivo de monitorar os preços de um determinado trecho.
Vale ressaltar que os sistemas I e III estão ligados ao pensamento e raciocínio, enquanto as demais estão atreladas ao comportamento humano. Além disso, os sistemas I e II envolvem estudos empíricos, formulação de hipóteses, confirmação do experimento e realizam a medição do sucesso da solução encontrada com base no quão fidedigna suas ações são das atitudes humanas. Já os sistemas III e IV comparam o sucesso com um conceito ideal de inteligência – que é a racionalidade – e utilizam a matemática e a engenharia na busca de soluções.
Por conseguinte, desde a sua evolução histórica, a IA tem alcançado um grande desenvolvimento através dos estudos desses quatro tipos de sistemas. Tais sistemas contribuem para realizar abordagens tanto centradas em seres humanos, quanto em torno da racionalidade. Agora, vamos entender a evolução da história da IA com base nos períodos a seguir (SELVAMANIKKAM, 2018):

Além dessa evolução história de IA, tem-se as três principais abordagens que podem ser utilizadas nessa área: conexionista, que está relacionada à hipótese de causa e efeito em que há a modelagem do cérebro humano para reproduzir as ações humanas – um exemplo são as redes neurais; simbólica, baseia-se na hipótese de sistemas de símbolos físicos, que dado um conjunto de estruturas simbólicas e regras de manipulação, são recursos suficientes para criar a inteligência – um exemplo são os sistemas; evolucionária, está relacionada à teoria evolutiva de Darwin, em que sistemas inteligentes são modelados a partir da evolução de indivíduos aleatórios e utilizam operações genéticas de recombinação e mutação – um exemplo são os algoritmos genéticos. Ainda se tem uma quarta abordagem em desenvolvimento, denominada IA Híbrida, que utiliza diversas ferramentas e mescla as abordagens acima para encontrar a solução de um problema (SELVAMANIKKAM, 2018).
Por fim, vimos como a IA é uma grande área de pesquisa e, atualmente, considerada uma grande evolução da tecnologia, dividindo os sistemas nas diversas formas de pensar e raciocinar e também com suas diferentes abordagens. Tudo isso corrobora para que a IA se sedimente como uma área de inovação na criação de máquinas que podem ser comparadas à forma de pensar e agir de forma humana!
Agentes inteligentes são capazes “de fazer uma leitura do ambiente em que está inserido e, a partir daí, propor soluções que maximizem as chances de sucesso. A Inteligência Artificial, que antes estava restrita às grandes empresas, hoje influencia a compra de produtos, muda o ambiente, melhora o dia a dia corporativo e facilita a vida das pessoas, de maneira racional” (ALVES, 2019, on-line).
Conforme a classificação dos sistemas ao longo da evolução da IA (Inteligência Artificial), os agentes inteligentes citados no texto, podem ser classificados corretamente como:
sistemas que pensam como seres humanos.
Incorreta. Nesse tipo de sistema, é necessário ter a programação das faculdades mentais para começar a criar o pensamento humano.
sistemas que agem como seres humanos.
Incorreta. Esses sistemas requerem a atuação como humanos no sentido comportamental. A inteligência, aqui, é criada para executar funções que também podem ser executadas por humanos, como o Teste de Turing.
sistemas que pensam de forma racional.
Incorreta. Esse tipo de sistema é baseado em notações lógicas.
sistemas que agem de forma racional.
Correta. Nesse tipo de sistema tem-se a utilização de um agente que analisa o ambiente e propõe formas racionais de pensar conforme foi programado.
sistemas especialistas.
Incorreta. Um sistema especialista imita o comportamento de um especialista em uma área do conhecimento.
A inteligência artificial foi elaborada com dois grandes objetivos: o primeiro é ter a habilidade de entender que a eficácia foi atingida em determinada situação e, assim, aplicar esse aprendizado para outros contextos de problemas; o segundo se refere à possibilidade de resolver situações e problemas novos com êxito, com base no conhecimento que a IA adquiriu durante a solução do problema (LUGER, 2013).
No que se refere aos tipos de problemas que a IA pode auxiliar, temos uma diversidade de exemplos que corroboram que utilizar IA não é novidade e que já faz parte do nosso dia a dia. Vamos categorizar os problemas e exemplos a partir das seções seguintes.
O problema de automatizar os processos industriais vem ocorrendo há muito tempo. Desde que mudaram os modelos de fabricação, por exemplo, já foi uma tentativa de fazer com que as tarefas manuais fossem automatizadas, principalmente com a evolução das máquinas industriais e até mesmo com os computadores (LUGER, 2013).
A partir disso, a ideia era produzir mais em menor tempo, para obter o maior lucro possível. Esse contexto está atrelado aos processos produtivos contínuos, que possuem atividades repetitivas e frequentes, fazendo com que a IA aprenda esse tipo de atividade, ou seja, as máquinas copiam esses padrões humanos de atividade.
Quando esse aprendizado ocorre, muitos dados podem ser combinados de forma rápida, os quais são processados de forma eficiente, fazendo com que haja uma interpretação dos dados gerado, para, assim, serem adquiridos como conhecimento pelas máquinas.
Um dos grandes benefícios atrelados ao uso de IAs em processos contínuos das empresas é a eliminação de erros em virtude da falta de atenção humana naquele processo ou até mesmo a fadiga, pois as máquinas trabalham ininterruptamente e, assim, produz-se um nível de produtividade muito maior (LUGER, 2013).
Outro benefício que podemos citar é a redução de custos com pessoal. Em algumas lojas de comércio eletrônico, são utilizados chatbots, programas de IA que simulam uma conversa com seres humanos, enquanto o atendente humano só é solicitado quando envolve um problema de complexidade maior. Sendo assim, os custos com os funcionários são menores, ou até podem alocar alguns funcionários para áreas mais estratégicas da indústria para maximizar o lucro da empresa e focar nos negócios da organização (LUGER, 2013).
Mas, na prática, como podemos perceber que as IAs resolvem os problemas da indústria? Vejamos, a seguir, alguns exemplos (LUGER, 2013).

Além dessas áreas, podemos citar algumas situações em que as IAs já substituíram os humanos nos processos produtivos, como: algumas máquinas inteligentes já realizam a conferência dos produtos, sem passar por operadores humanos; já existem máquinas atreladas ao processo criativo da empresa, que, por conta própria, executam novos projetos de tarefas criativas, similares aos humanos.
Nessa área, as IAs estão sendo aplicadas para a prevenção de doenças, aprimoramento de diagnósticos e a indicação de tratamentos em diversos casos de saúde. Em um estudo publicado pela Nature (YU; BEAM; KOHANE, 2018), alguns robôs já são utilizados para fornecer orientações de conduta dentro de um ambiente hospitalar, baseado nos padrões adquiridos dentro desse ambiente.
Além disso, as IAs possuem uma quantidade significativa de dados e algoritmos (sequência lógica de dados) com o objetivo de fornecer informações precisas nas tomadas de decisões para auxiliar os profissionais de saúde. Para isso, todos os dados (prontuários, pesquisas acadêmicas relevantes, entre outros) são armazenados em nuvem, e, após realizar o processamento e o cruzamento de informações, as IAs oferecem aos médicos uma diretriz para fazer um diagnóstico mais preciso ou até mesmo prescrever tratamentos terapêuticos (NOSÉ, 2019).
Dentre as diversas áreas de saúde podemos citar a oftalmologia, que já se prevalece do uso de IAs em cirurgias de cataratas. A IA calcula em tempo real todas as informações sobre o globo ocular no momento da cirurgia e sugere a lente intraocular mais recomendada após a remoção do cristalino (lente natural do olho); dessa forma, evita limitações visuais do paciente após a cirurgia (NOSÉ, 2019).
Um exemplo que podemos citar em precisão de diagnósticos com câncer é o software IBM Watson for Oncology, que, baseado em uma gama de informações disponibilizadas a ele sobre o paciente em questão, consegue chegar a um diagnóstico mais preciso e assertivo (IBM WATSON, 2019).
Outro problema que as IAs podem solucionar é a triagem automática de pacientes para priorizar os casos emergenciais. Dessa forma, aqueles casos mais críticos aparecem em primeiro para atendimento médico (OS BENEFÍCIOS..., 2020).
Outra questão é a utilização de rede neural como forma de fornecer uma análise mais aprofundada nos prontuários para detectar descobertas de doenças em nível sobre-humano (OS BENEFÍCIOS..., 2020).
Adicionalmente, alguns aparelhos já vêm com IAs programáveis, que notificam o médico instantaneamente sobre mudanças no estado clínico do paciente. Dessa forma, o médico já registra isso no prontuário e, assim, começa o atendimento de forma eficaz.
Outra utilização é na precisão de um diagnóstico muito complexo, pois a demora em acertar o diagnóstico do paciente pode prejudicá-lo, pela demora no início do tratamento. Sendo assim, a IA faz a associação dos sintomas com todo o histórico médico do paciente e sugere as possíveis doenças que este pode desenvolver, para, então, o médico poder iniciar as profilaxias adequadas (OS BENEFÍCIOS..., 2020).
Uma perspectiva futura nessa área é na predisposição de determinadas doenças, mas com base no histórico familiar. Para isso, todos os prontuários precisarão estar armazenados na nuvem, sendo necessárias mais regras de segurança e, até mesmo, permissões do conselho de ética da área de saúde para aprovar o registro desses prontuários na internet (OS BENEFÍCIOS..., 2020).
Por fim, o setor de saúde está sendo muito otimizado com a aplicação das IAs para buscar recursos na melhoria das experiências dos pacientes, agilizando seus atendimentos, e dos melhores procedimentos para a redução de custos dentro do hospital.
Umas das questões em educação e que as IAs estão auxiliando é na criação de plataformas adaptativas, que consistem na sugestão de trilhas de aprendizado individualizadas com base nos dados que se tem de cada aluno (STEFANINI, 2019).
Para fazer esse trabalho, a IA mapeia todo o conteúdo de uma determinada área de conhecimento e associa com as dificuldades que o aluno tem na disciplina. Assim, para ajudar ao aluno, a IA propõe um plano de estudo adequado para ele, como forma de minimizar as dificuldades encontradas naquele conteúdo.
Outra solução que a IA pode resolver são para os cursos de educação a distância no que se refere à correção automática de provas, como forma de auxiliar a rotina do professor, sendo mais rápido que a correção manual, melhorando a sua eficiência nos planos de aula (MARTINS, 2010).
Uma nova aplicação é o Professor 24 Horas, que consiste em uma IA que se propõe a tirar as dúvidas dos alunos 24 horas por dia e pode ajudá-los a aprofundar os conhecimentos nas disciplinas do seu curso à distância. A plataforma ainda oferece um conteúdo extenso e respostas bem precisas para as dúvidas dos alunos, que podem acompanhar sua evolução a partir de relatórios e, ainda, compartilhar tudo isso em uma rede social própria (STEFANINI, 2019).
Por conseguinte, a gamificação pode ser melhorada para promover o aprendizado dos alunos por meio de jogos. Fazendo o equilíbrio entre o jogo ser desafiador e seu nível de dificuldade adequado, a IA analisa o desempenho de cada estudante e faz adaptações no jogo para cada nível de atuação do aluno. Se o aluno sempre ganha, o jogo evolui para se tornar mais difícil, mas, se o aluno está sempre perdendo, o jogo também é adaptado para as suas capacidades. É assim que a gamificação está se tornando inteligente (MARTINS, 2010).
Por fim, as IAs estão sendo utilizadas para conter alunos propensos à evasão. A partir disso, a escola pode trazer iniciativas eficazes (seja acompanhamento ou até comunicado para a família) para promover a aprendizagem mais eficiente e o favorecimento da permanência do aluno na instituição.
E como podemos perceber a utilização da IA em nosso dia a dia? Vamos entender, agora, como isso funciona!
De acordo com Martins (2010), a IA aparece em nosso cotidiano das seguintes formas:
De repente, você está em casa sozinho à noite e a sua assistente pessoal Alexa começa a rir sozinha. Desesperador não? Uma assistente pessoal totalmente programável, criando atitudes de forma autônoma. Foi isso que ocorreu nos Estados Unidos com alguns usuários que registraram com vídeos e enviaram à Amazon. A empresa confirmou o problema e estava corrigindo-o.
Será que, ao inserirmos tanta Inteligência Artificial em nosso cotidiano, fazendo com que elas assumam nossas tarefas, chegará um dia em que elas começarão a decidir da forma que quiserem o que pretendem ou não fazer com a inteligência que lhes foi atribuída? (YUGE, 2018).
Por fim, vimos algumas das áreas em que as IAs podem ser utilizadas, sendo que algumas já estão totalmente imersas em nosso dia a dia e até mesmo algumas perspectivas futuras em cada área. É importante que as IAs possam contar com o acesso a um grande volume de dados para prover processamentos cada vez mais assertivos, havendo, nesse sentido, uma relação muito forte com o uso de tecnologias como Big Data.
Muitas pesquisas ainda estão sendo realizadas dentro da área de inteligência artificial para fazer com que ela se solidifique e se intensifique, seja em nossa vida pessoal ou profissional. A IA passa de uma perspectiva meramente de ficção científica para se adequar à otimização de tarefas feitas por humanos. No entanto, é necessário, também, compreender os riscos inerentes à utilização das IAs e seus impactos na vida cotidiana das pessoas.
Leia o trecho a seguir.
“São softwares movidos por Inteligência Artificial, capazes de executar pequenas tarefas e fornecer informações solicitadas pelo usuário. Eles partem, em resumo, da conta do usuário, reconhecimento de voz e de sua geolocalização para acessar várias fontes sobre clima, trânsito, horários, entre outros temas. São exemplos desses softwares: Siri, Alexa, Cortana entre outros” (RAHDE, 2019, on-line).
Com base no texto acima, podemos afirmar que esses softwares podem ser definidos como qual tipo de utilização de inteligência artificial (IA) em nosso dia a dia?
Assistentes pessoais.
Correta. Esses softwares executam tarefas diárias e, a partir do reconhecimento de voz, podem realizar e sugerir opções para o dia a dia do usuário.
Chatbots.
Incorreta. Esse software tem o objetivo de sanar as dúvidas dos usuários após uma conversa on-line.
Leitor de e-mail.
Incorreta. O leitor de e-mail utilizando IA se propõe a fazer a varredura nos e-mails dos usuários e realizar classificações, como spam, e enviá-los para a lixeira.
Análise de dados.
Incorreta. A análise de dados é uma técnica que permite que, após analisar uma quantidade enorme de dados, seja oferecido um padrão para o usuário poder otimizar rotinas.
Gestores de pessoas.
Incorreta. Esse tipo de sistema está interessado em encontrar um padrão para uma possível vaga de emprego ofertada.
Vimos, até agora, os conceitos inerentes à Inteligência Artificial e em quais contextos ela pode ser aplicada, certo? Mas, agora, precisamos ir um pouco mais além: se precisássemos de sistemas inteligentes que aceitassem parametrização de dados subjetivos ou até mesmo incertos (ex.: pouco alto, pouco caro, entre outros), de que forma poderíamos realizar isso? Iríamos precisar utilizar a lógica fuzzy para realizar esse tipo de tratamento com esses dados. Vamos começar!
O termo “fuzzy”, quando traduzido do inglês para o português, significa “difuso, confuso, vago”, e a palavra “lógica” denota um estudo para saber se os argumentos são válidos ou não. Sendo assim, a lógica fuzzy pode ser entendida como a forma com que os argumentos considerados vagos podem ser válidos ou não em determinadas situações (SIMÕES, 2007).
Em outra definição, pode-se dizer que a lógica fuzzy consiste em uma forma da lógica multivalorada, em que são considerados os valores no intervalo entre 0 e 1 para representar situações de imprecisão ou incertezas do mundo real (ZADEH, 1976).
Além disso, a lógica fuzzy é um ramo da inteligência artificial, de sistemas computacionais e para o controle de processos. Ela permite que as informações descritas em linguagem natural possam ser convertidas em formatos binários. Essas informações formam o que são denominados de termos Fuzzy (MARRO et al., 2010).
Mas o que são termos Fuzzy? Vejamos situações do nosso dia a dia que refletem isso (MARRO et al., 2010):
Os termos entre aspas refletem medidas incertas ou imprecisas e são considerados conceitos muito vagos. No exemplo da altura, não existe um limite preciso que determine essa medida; mesmo se considerarmos que homens altos são aqueles que medem a partir de 1.90 m, então, os homens que estão com 1.89 m são considerados “quase altos”, e não altos.
Perceba que, com a lógica fuzzy, não há como responder somente “sim” ou “não” para as situações específicas com todas as informações conhecidas. É necessário informar valores mais relativos, como “talvez”, para que seja mais apropriado para o contexto informado.
Os conceitos de lógica fuzzy começaram por volta do ano 1920, por Jan Lukasiewicz, que iniciou o conceito de graus de pertinência que, combinados com a lógica clássica desenvolvida por Aristóteles, formaram a base da lógica fuzzy. Os graus de pertinência iniciaram com os valores 0, ½ e 1 e, depois, expandiram para um conjunto infinito de valores entre 0 e 1 (SIMÕES, 2007).
Vale ressaltar que um grau de pertinência se refere a diferentes graus que são considerados verdadeiros. Assim, os graus de verdade estavam dispostos entre 0 e 1, e as informações que se quer medir admitem graus. Como exemplos dessas informações pode-se citar: altura, velocidade, temperatura, entre outros (SIMÕES, 2007).
A partir desse estudo, em 1960, um professor de ciência da computação da universidade de Califórnia, Lotfi Asker Zadeh, começou a se basear nesse estudo e foi o autor que publicou o primeiro artigo denominado “Fuzzy sets”.
Zadeh (1976) começou a observar que muitas das regras que as pessoas costumeiramente usavam não podiam ser explicadas com base na lógica tradicional. Por exemplo, pode-se olhar para uma pessoa e supor que ela tem 40 anos, mas não se sabe explicar esse fato.
Zadeh procurou explicar ideias assim por meio da lógica fuzzy. Porém, os estudos de Zadeh (1976) não foram aceitos de forma branda e foram alvo de muitas críticas que não consideravam os conceitos divergentes da lógica clássica, já que acreditavam que a lógica tradicional ainda poderia encontrar uma forma de explicar os valores difusos.
Contudo, conforme os estudos de Zadeh (1976) foram avançando, alguns precursores foram utilizando-os na prática, como os japoneses, que construíram os primeiros sistemas de controle fuzzy, em 1987, para ser utilizado na estrada de ferro de Sendai, localizada no Japão. Esse sistema visava controlar a aceleração, frenagem e a parada nas estações metroviárias. Além desse uso, houve, também no Japão, a aplicação dessa lógica em um sistema de água. Somente nos anos 1990 é que a lógica fuzzy ganhou a importância em empresas nos Estados Unidos (ZADEH, 1976).
Dessa forma, a lógica fuzzy foi aplicada em diversos setores, principalmente os industriais, que serviram para solidificar os conceitos desse tipo de lógica. Por isso é considerada uma técnica padrão e tem uma boa aceitação tanto em processos industriais quanto comerciais.
Antes de começarmos a conceituar os conjuntos fuzzy, os quais são de extrema importância para o entendimento da lógica fuzzy, vejamos, a seguir, alguns princípios que norteiam a lógica (MARRO et al., 2010).
Além desse princípio, faz-se necessário explicar também como a lógica fuzzy diverge da lógica clássica (GOMES; RODRIGUES, on-line).
\[f_A (x) \left\{\begin{matrix} 1~se~e~somente~se~x~∈ ~A\\ 0 ~se~e~somente~se~x~∉~A \end{matrix}\right.\]
Na lógica fuzzy, o resultado de uma proposição pode ter variância em graus de verdade, podendo ser parcialmente verdadeiro ou parcialmente falso. Sendo assim, a função de pertinência \(\mu \left( x \right)\) pode assumir valores no intervalo entre 0 e 1, podendo ser totalmente verdadeiro ou totalmente falso, conforme explicitado na função de pertinência de um conjunto fuzzy (GOMES; RODRIGUES, on-line):
\[{{\mu }_{A}}\left( x \right):X\to \left[ 0,1 \right]\]
Agora, podemos conceituar os conjuntos fuzzy como funções que fazem o mapeamento de um valor escalar no intervalo entre 0 e 1, o qual indica seu grau de pertinência a um determinado conjunto (GOMES; RODRIGUES, on-line).
Podemos dizer, ainda, que o conjunto fuzzy é representado pela letra A e que o grau de pertinência determina os valores do conjunto \(\mu \) em relação ao conjunto fuzzy A, ou seja, quanto é possível para um elemento x pertencer ao conjunto A.
Vamos entender melhor a aplicação da fórmula, por meio de alguns exemplos (MELO NETO, on-line)?
1. Vamos representar o conceito de céu ensolarado através do conjunto:
A: {(0, 1.0), (20, 0.8), (30, 0.4), (75, 0.0)}
Os valores de pertinência são: 1.0, 0.8, 0.4 e 0.0. Podemos, então, interpretar que: a pertinência de 1.0 tem uma cobertura de nuvens de 0%, a de 0.8 tem uma cobertura de nuvens de 20%, a de 0.4 tem cerca de 30% de nuvens, e a de 0.0 tem cerca de 75% de nuvens ou mais. Logo, o céu ensolarado está presente no primeiro par ordenado (0, 1.0).
2. Sendo A o conjunto de pessoas altas, tem-se os seguintes gráficos para representar se uma pessoa com 1.70 é alta ou não, diferenciando-se pela definição de conjuntos clássico e fuzzy:
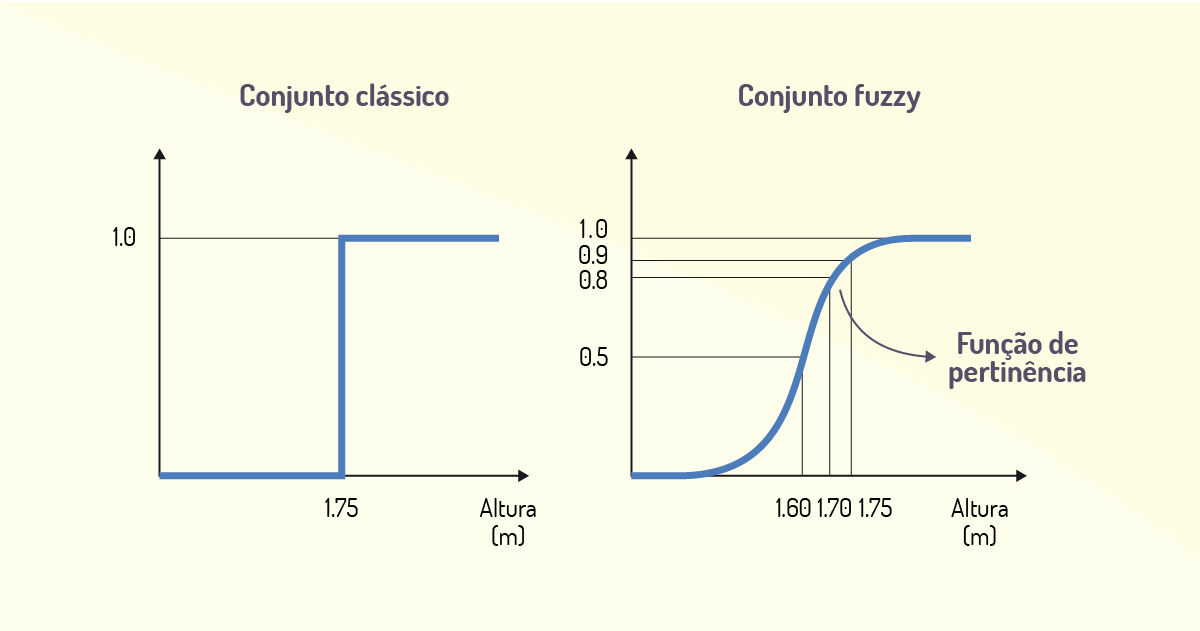
Pode-se visualizar que, no conjunto clássico, uma pessoa com 1.70 de altura não pertence ao conjunto A de pessoas altas e tem grau de pertinência 0. Já no conjunto fuzzy, essa pessoa em questão pertence ao conjunto A de pessoas altas e tem grau de pertinência 0.8.
Por fim, entendemos que a lógica fuzzy é uma técnica que permite capturar as informações precisas ou incertas descritas em linguagem natural para, depois, serem convertidas em formato numérico, formando os conjuntos fuzzy.
Com o conceito dos conjuntos fuzzy para representar as incertezas de algumas informações, tem-se a necessidade de entender como se dará a modelagem de um sistema que se baseia na lógica fuzzy. Esse tipo de sistema é nomeado de Sistemas de inferência fuzzy, ou Fuzzy Inference Systems (FIS), que visam representar a modelagem do raciocínio humano em um formato de regras (GOMES; RODRIGUES, on-line).
É comum expressarmos o raciocínio de forma lógica, com alguns conectivos que antecedem uma ação e, depois, um conectivo para representar a reação disso. São utilizados, por exemplo, SE (antecedente), ENTAO (consequência), e ainda podem ser utilizados diversos operadores lógicos como “e” e “ou”.
Nesse contexto, uma arquitetura para sistemas de inferência fuzzy é proposta (Figura 3.5) (GOMES; RODRIGUES, on-line):
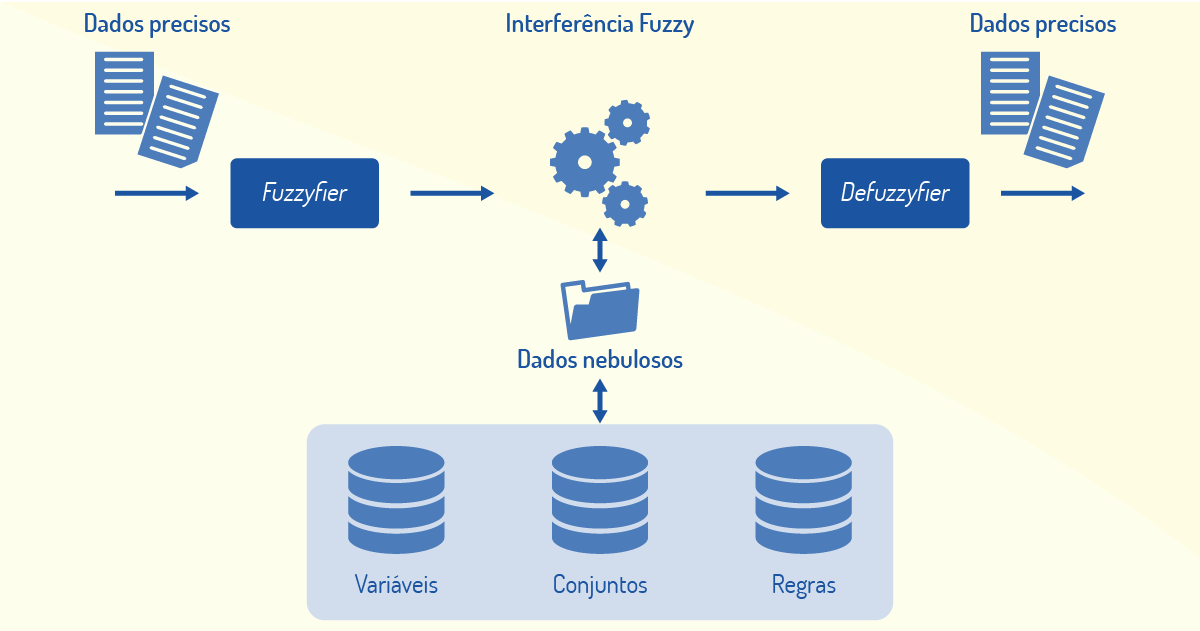
A arquitetura possui quatro componentes: processador de entrada (fuzzyfier), que transforma os dados de entrada precisos em representações nebulosas; uma base de conhecimento, representada pelas variáveis nebulosas, suas funções de pertinência e um conjunto de regras descritas por um especialista; uma máquina de inferência fuzzy, responsável pela avaliação das regras e inferência da saída; e um processador de saída (defuzzifier), que fornece um número real como saída da inferência.
Dessa forma, os dados precisos fornecidos como entradas para o sistema de inferências são transformados em dados nebulosos (fuzzification). Estes são processados pelo núcleo de cálculo, em função do mapeamento de regras definidas e, então, transformados novamente em dados precisos (defuzzification), que são retornados como saída pelo sistema de inferências. É importante destacar que tanto as entradas como a saída de um sistema de inferências fuzzy são valores numéricos, que são internamente processados utilizando-se definições fuzzy.
Vejamos como um sistema desses pode auxiliar na tomada de decisão em um sistema de RH (Recursos Humanos), em que se tem a implantação de uma nova funcionalidade: determinar os valores de gratificação dada aos funcionários, evitando a parcialidade e promovendo a isenção reivindicada pelo quadro de funcionários insatisfeitos (GOMES; RODRIGUES, on-line). O projetista informou que os critérios de experiência e de capacitação serão usados como variáveis de entrada do sistema, sendo a experiência expressa entre 0 e 30 anos, enquanto o tempo de capacitação é expresso entre 0 e 15 anos. A gratificação é a variável de saída, com valores entre R$ 0,00 e R$ 1.000,00. Esses intervalos são conhecidos como o universo de discurso das variáveis. O especialista definiu que a variável de entrada experiência se divide em três segmentos: pouca, média e muita. A variável de entrada capacitação seguiu uma divisão similar em três partições: fraca, média e forte. E a saída, representada pela variável gratificação, foi dividida em cinco termos: muito baixa, baixa, média, alta e muito alta.
Na sequência, o especialista determina as regras que direcionarão a decisão feita pelo sistema, constituídas pelo encadeamento de condições e uma conclusão, na forma: SE <condição1> E <condição2> ENTÃO <conclusão>. A conclusão indica a qual conjunto a variável de saída pertence. As regras para o problema de valoração de gratificação definidas pelo especialista são as seguintes:
SE capacitação é “Fraca” E experiência é “Pouca”, ENTÃO, gratificação é “Muito-Baixa”.
SE capacitação é “Fraca” E experiência é “Média”, ENTÃO, gratificação é “Baixa”.
SE capacitação é “Fraca” E experiência é “Muita”, ENTÃO, gratificação é “Média”.
SE capacitação é “Média” E experiência é “Pouca”, ENTÃO, gratificação é “Baixa”.
SE capacitação é “Média” E experiência é “Média”, ENTÃO, gratificação é “Média”.
SE capacitação é “Média” E experiência é “Muita”, ENTÃO, gratificação é “Alta”.
SE capacitação é “Forte” E experiência é “Pouca”, ENTÃO, gratificação é “Média”.
SE capacitação é “Forte” E experiência é “Média”, ENTÃO, gratificação é “Alta”.
SE capacitação é “Forte” E experiência é “Muita”, ENTÃO, gratificação é “Muito-Alta”.
Uma visão segmentada dos processos de fuzzificação e defuzzificação pode ser observada no diagrama da Figura 3.6, em que é avaliado o caso de um profissional com 10 anos de capacitação e 20 anos de experiência. O processo usa a capacitação e a experiência informada para rastrear as regras que foram ativadas e conclui que o profissional é merecedor de uma gratificação de R$ 600,00.
Observando as regras já definidas e o diagrama da Figura 3.6, nota-se que as regras 5, 6, 8 e 9 foram ativadas por atenderem às condições impostas. Com os graus de inclusão dos conjuntos fuzzy de gratificação já ponderados, a defuzzificação é efetuada, gerando a saída única, que é o valor de gratificação esperado como resultado final do processo de decisão nebuloso.
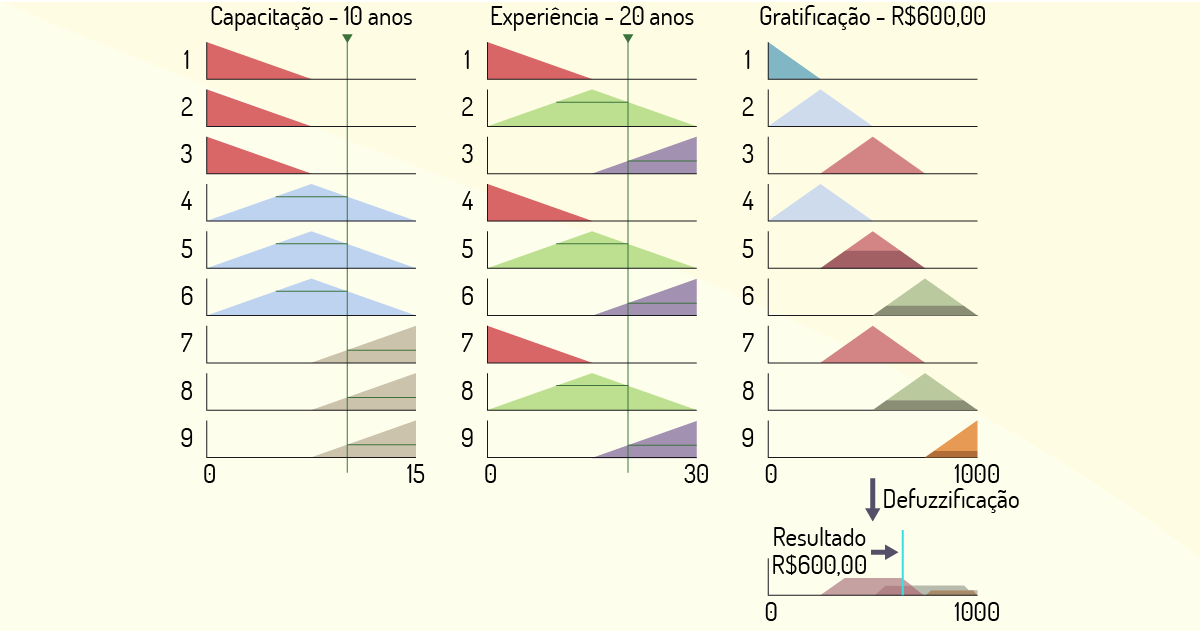
Para se chegar ao valor de R$ 600,00, foram consideradas as áreas em negrito da terceira coluna na direita do diagrama, realizadas por uma API JFuzzyLogic, que recebeu os valores para realizar a defuzzificação e gerou a saída por meio do cálculo do centro de gravidade das áreas em negrito da coluna gratificação do diagrama. Esse cálculo já está implementado como método dentro da API e é transparente para o projetista da lógica fuzzy.
Por fim, esse exemplo da determinação do valor de gratificação, apoiado pela lógica fuzzy, esclarece o processo de modelagem de uma solução orientada a regras de negócio encontrada no dia a dia de muitos sistemas corporativos.
Termos fuzzy são utilizados diariamente em linguagem natural para representar dados incertos ou, como são denominados em computação, nebulosos. Tais dados são considerados muito vagos e/ou subjetivos e não possuem um limite muito bem definido.
Com base na definição dos termos fuzzy, qual das alternativas abaixo aplica corretamente esse conceito ao termo sublinhado? Assinale a alternativa correta.
O dólar está com cotação de R$ 3,50 (reais) na bolsa de valores.
Incorreta. O termo “cotação” foi definido em seu limiar em 3.50, portanto, não há incerteza no valor da cotação.
O trabalho está realizado, de forma concluída, em 100%.
Incorreta. O termo “realizado” tem o limite de 100% para ser considerado realizado.
A água está muito quente.
Correta. O termo “muito” está incerto na frase, pois não se tem um limite que informe o que torna a água quente.
Siga a estrada por 10 km.
Incorreta. “10 km” refletem, matematicamente, o limite que se deve seguir pela estrada.
O idoso tem uma escala de idade a partir de 50 anos.
Incorreta. O idoso tem uma escala definida, em seu limiar, em a partir de 50 anos. Não há outras classificações de idade nessa frase.
Os algoritmos genéticos (AG) podem ser definidos como uma classe particular de algoritmos evolutivos que utilizam as técnicas da biologia evolutiva, seleção natural e crossing over (recombinação) e se baseiam na teoria da evolução de Darwin (FERNANDES, 2003).
Os AGs são considerados algoritmos de otimização global que se baseiam nos mecanismos de seleção natural e de genética. Eles utilizam uma estratégia de busca paralela, de forma estruturada, aleatória e direcionada para buscar informações históricas de novos pontos de busca para obter o melhor desempenho (GILLIARD; PACHECO, on-line).
Adicionalmente, técnicas de busca e otimização tradicionais operam com um único candidato que, de forma iterativa, utiliza algumas estatísticas a serem associadas ao problema a ser solucionado. Tais processos estatísticos não são algorítmicos, e a simulação nos computadores pode se tornar muito complexa (GILLIARD; PACHECO, on-line).
Já as técnicas de computação evolucionária trabalham com uma população de candidatos em paralelo e realizam a busca em diferentes áreas para a solução do problema, tendo um número de membros específico para cada região a ser realizada a busca da solução (FERNANDES, 2003).
Por conseguinte, os AGs diferem-se dos métodos tradicionais de busca e otimização nos seguintes aspectos (FERNANDES, 2003):
Por fim, os algoritmos genéticos são utilizados para a busca de soluções ótimas de forma eficiente, ou até mesmo para solucionar uma grande variedade de problemas, já que não há tantas limitações como ocorre com os métodos tradicionais. Além disso, os AGs são considerados uma classe de procedimentos com várias etapas separadas, em que cada uma dessas etapas possui uma grande variação de soluções possíveis.
Antes de começarmos a descrever os AGs, vamos conceituar alguns termos relevantes para o entendimento dessa área (RUSSEL; NORVIG, 2013). Os AGs atuam sobre uma população, que representa um conjunto de indivíduos dentro de um espaço de busca. Realizando uma ligação com a genética, um indivíduo corresponde a um cromossomo, que contém genes que o caracterizam. Do ponto de vista computacional, cada indivíduo (ou cromossomo) é codificado por uma cadeia de valores representativos, em uma função objetivo utilizada para buscar a solução de um determinado problema de otimização, sendo que os genes são os seus parâmetros utilizados no formato binário, inteiro ou real.
Assim, a proposta de um AG é selecionar, a partir de uma população com indivíduos gerados aleatoriamente, indivíduos melhor adaptados (aptidão) a uma função objetivo para resolver um problema por meio de uma análise conhecida como adaptação (fitness). Essa seleção é feita para que possam ser criados descendentes que irão estar mais aprimorados para a solução, sendo esta conhecida como reprodução. A descendência de indivíduos é criada por meio de processos de cruzamento (crossover) (combinação de dois indivíduos/cromossomos intercambiando sua informação genética) ou mutação (introdução de novas combinações genéticas nos indivíduos), aumentando, assim, a diversidade e variabilidade da população. Dessa forma, novos indivíduos com novos códigos genéticos serão gerados, como pode ser visto na Figura 3.7, a seguir.

Assim como ocorre na evolução dos seres humanos – que não aconteceu apenas uma única vez, mas continua ocorrendo através de vários ciclos ao longo da história –, os algoritmos realizam, de forma interativa e sequencial, cada processo de seleção e reprodução, gerando uma nova população, denominada geração. Cada indivíduo de uma geração apresenta uma aptidão bruta, um valor gerado pela função objetivo, que pode ser normalizada (aptidão normalizada) para o algoritmo de seleção. Assim, a média das aptidões de uma população é representada pela sua aptidão média, sendo que o indivíduo que apresenta melhor adaptação é encontrado pela aptidão máxima desta.
Nos subtópicos a seguir, veremos com mais detalhes como esses passos retratados pelos conceitos de um AG são tratados.
Operadores genéticos são formas de diversificar uma população que mantenha as características de adaptação adquiridas em gerações anteriores. O objetivo desses operadores é que, após sucessivas gerações, a população se transforme até chegar em um resultado satisfatório (CARVALHO, on-line).
Um exemplo é o operador de mutação que visa introduzir e manter a diversidade genética de uma população, alterando, de forma arbitrária, uma estrutura da população para gerar novos elementos, conforme podemos visualizar na Figura 3.8:

Na Figura 3.8, um indivíduo, representado pelo número 1 (um), sofreu mutação e gerou um novo indivíduo, representado pelo número 0 (zero). Dessa forma, a mutação assegura que a probabilidade de se chegar a qualquer ponto do espaço de busca nunca será zero, além de contornar o problema de mínimos locais, pois, com esse mecanismo, altera-se levemente a direção da busca.
Outro operador é o cruzamento (crossover), que faz a recombinação de características dos pais que, durante a reprodução, faz com que as gerações seguintes herdem essas características. Conforme aponta Carvalho (on-line), ele é um operador genético dominante e pode ser utilizado de várias maneiras, como:
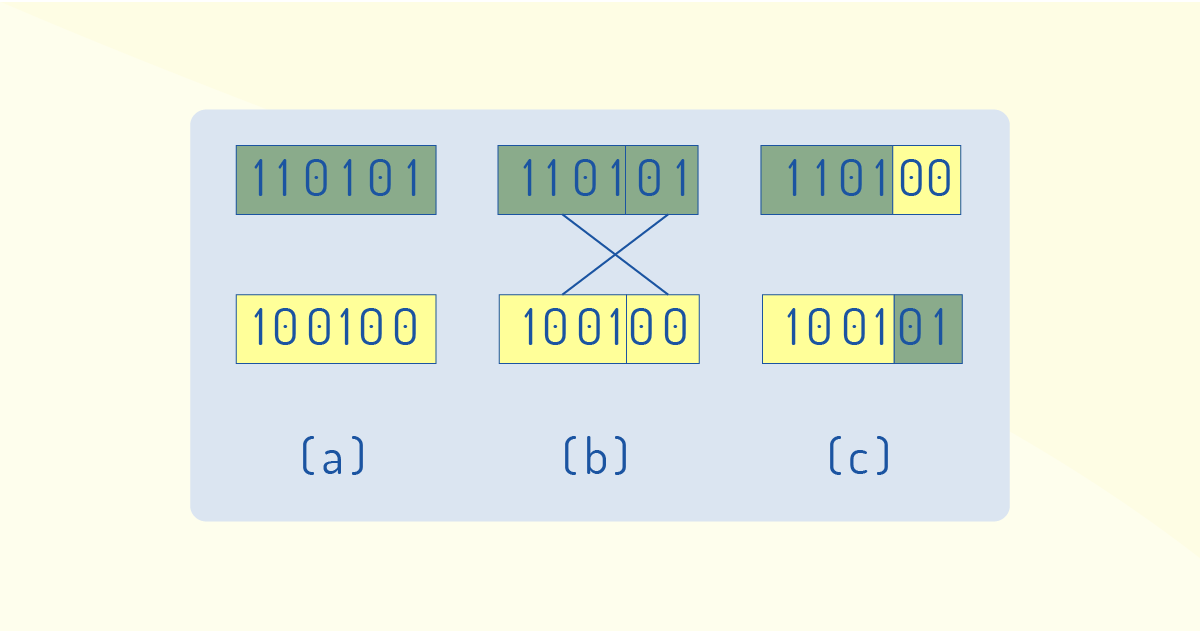
A Figura 3.9 ilustra o crossover de um ponto em que dois indivíduos (a) foram selecionados de forma aleatória, um ponto (4 genes) de cruzamento foi selecionado (b) e foram recombinadas as características, gerando dois novos indivíduos (c).
Além dos operadores, os parâmetros também influenciam o comportamento dos AGs, que são configurados diante da necessidade do problema em questão e dos recursos que estão disponíveis para a solução do problema. Alguns desses parâmetros são (GILLIARD; PACHECO, on-line):
Dessa forma, tanto os parâmetros quanto os operadores são importantes para alcançar uma população com características diversas e que mantenham aqueles mais aptos ao ambiente configurado, para se chegar à solução do problema.
Um AG simples tem seu funcionamento de forma que, na inicialização, seja gerada uma população aleatória de n indivíduos, em que cada indivíduo representa um ponto no espaço de possíveis soluções para o problema. Após cada iteração do algoritmo, são realizadas quatro operações básicas (GILLIARD; PACHECO, on-line):
Todas essas operações podem ser visualizadas no fluxo de atividades da Figura 3.10:
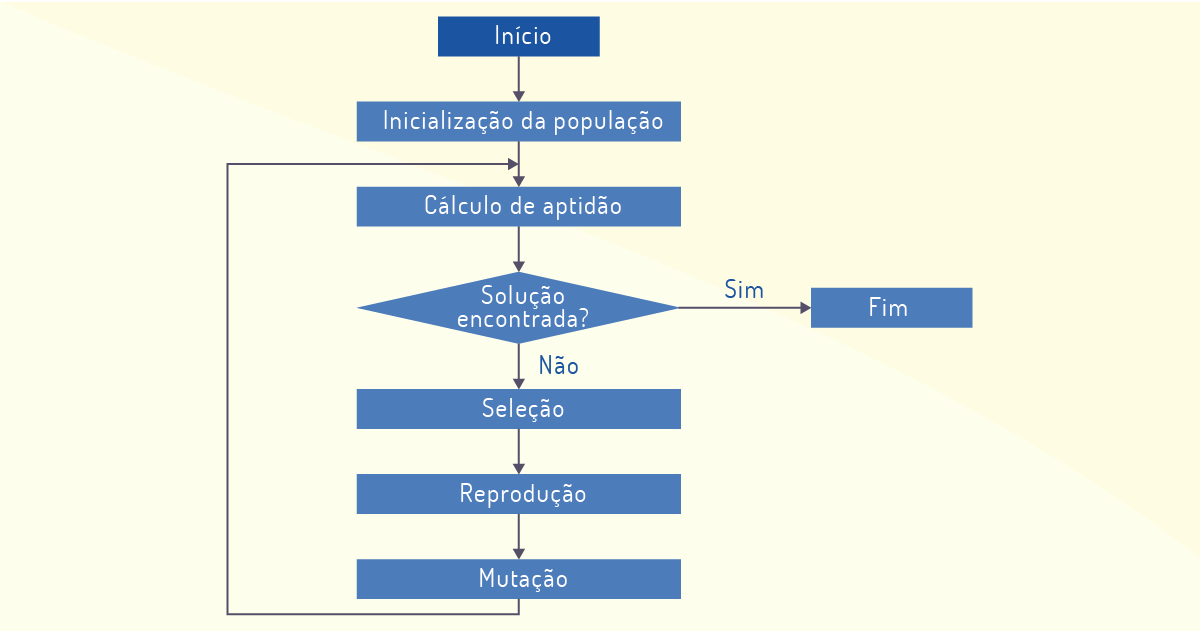
Caso o algoritmo não encontre a solução para o problema, uma nova iteração é realizada a partir do cálculo de aptidão para buscar novos indivíduos considerados aptos, que, se não forem a solução para o problema, passarão pelas quatro operações básicas de um AG simples. Quando encontrarem uma estagnação na varredura da solução dos problemas, as iterações param e fornecem a solução ótima.
Os AGs são utilizados em larga escala para a solução de problemas de otimização em muitas áreas. São considerados uma classe específica de algoritmos que se baseiam na evolução de Darwin e na biologia evolutiva.
Vejamos, a seguir, algumas das áreas em que os AGs podem ser implementados (MIRANDA, on-line).
- Circuitos analógicos: tendo como uma entrada e uma saída desejada, pode ser especificada como Tensão. O AG, então, gera uma topologia, o tipo e os valores do circuito para gerar a tensão desejada.
- Síntese de protocolos: determinação de quais funções do protocolo devem ser implementadas em hardware e quais devem ser implementadas em software para que um certo desempenho seja alcançado.
- Programação genética: gera a listagem de um programa, em uma determinada linguagem especificada, para que um determinado conjunto de dados de entrada forneça uma saída desejada.
- Ciências biológicas: modela processos biológicos para o entendimento do comportamento de estruturas genéticas.
- Problemas de otimização complexos: problemas com muitas variáveis e espaços de soluções de dimensões elevadas. Ex.: problema do caixeiro viajante, gerenciamento de carteiras de fundos de investimento.
Além desse tipo de AG, podemos descrever outros como o Genitor, que é um algoritmo que conserva os melhores pontos encontrados na população, realizando elitismo e o CHC (Cross generational elitist selection, Heterogeneous recombination and Cataclysmic mutation), mais utilizado atualmente, pois os N melhores indivíduos são selecionados a partir da população atual e após o cruzamento, removendo os indivíduos duplicados.
Portanto, os AGs têm inúmeras aplicações, podem ser adaptáveis para uma série de problemas e possuem elevado custo computacional. Contudo, para problemas específicos, aconselha-se o uso de algoritmos híbridos que mesclam técnicas de AG com métodos de otimização tradicionais.
Considere o trecho a seguir:
“Este estudo usa ‘algoritmos evolutivos genéticos’ para prever o crescimento urbano, mirando especificamente o distrito de Minato em Tóquio. O arquiteto Ivan Pazos, principal autor do novo estudo, explicou a ciência por trás do algoritmo: ‘Operamos dentro da computação evolutiva, um ramo da inteligência artificial e aprendizagem automática que usa as regras básicas da genética e a lógica da seleção natural de Darwin para fazer previsões’” (ABDALLAH, on-line).
As regras básicas de um algoritmo simples como o da matéria acima fazem uso de operações básicas da genética. Diante disso, analise as assertivas a seguir.
I. A primeira operação é a inicialização da população, que é uma amostra de indivíduos coletada de forma padronizada para descartar indivíduos que não se encaixam no problema.
II. A segunda operação é o cálculo de aptidão, que consiste em analisar os indivíduos da população inicial e fornece um ranking selecionando os melhores indivíduos.
III. A terceira operação é, após receber os indivíduos ranqueados, a seleção dos indivíduos para gerar uma nova população.
IV. A quarta operação é o cruzamento, em que é realizado um corte de forma configurada na primeira lista de indivíduos da seleção, para, assim, gerar duas listas de indivíduos que serão cruzados.
V. A quinta operação é a mutação que seleciona um indivíduo qualquer da nova geração e modifica seu gene, para que seja gerada uma nova população de indivíduos.
Estão corretas as afirmativas:
I, II e III, apenas.
Incorreta. A afirmativa I está incorreta, pois a amostra de indivíduos é feita de forma aleatória. A afirmativa II está incorreta, pois, no cálculo de aptidão, os indivíduos não são selecionados. A afirmativa III está correta, pois os indivíduos recebem um número para selecionar os indivíduos mais aptos para a solução do problema.
I, III e IV, apenas.
Incorreta. A afirmativa I está incorreta, pois a amostra de indivíduos é feita de forma aleatória. A afirmativa III está correta, pois os indivíduos recebem um número para selecionar os indivíduos mais aptos para a solução do problema. A afirmativa IV está incorreta, pois o corte na primeira lista de indivíduos é feito de forma aleatória.
II e III, apenas.
Incorreta. A afirmativa II está incorreta, pois, no cálculo de aptidão, os indivíduos não são selecionados. A afirmativa III está correta, pois os indivíduos recebem um número para selecionar os indivíduos mais aptos para a solução do problema.
III e IV, apenas.
Incorreta. A afirmativa III está correta, pois os indivíduos recebem um número para selecionar os indivíduos mais aptos para a solução do problema. A afirmativa IV está incorreta, pois o corte na primeira lista de indivíduos é feito de forma aleatória.
III e V, apenas.
Correta. A afirmativa III está correta, pois os indivíduos recebem um número para selecionar os indivíduos mais aptos para a solução do problema. A afirmativa V está correta, pois a mutação consiste na modificação de um gene da lista de indivíduos anteriores para gerar uma nova geração.
Os computadores foram criados como formas de acelerar atividades e raciocínios humanos. As máquinas realizam tarefas de forma muito mais eficaz que um ser humano, desde que configuradas corretamente sobre a forma que devem solucionar um determinado problema (DEEP LEARNING, on-line).
Baseando-se nisso, muitos pesquisadores procuraram entender como funciona a inteligência, que pode ser entendida como uma série de pensamentos lógicos, ou que a inteligência é estruturada sob a forma como o cérebro é organizado. Assim, foram criados sistemas lógicos para se adequar a esse tipo de inteligência (DEEP LEARNING, on-line).
Foi com base nesse contexto que se procurou entender como os neurônios funcionam, já que estão relacionadas ao processo de aprendizagem de novos conhecimentos e fazem parte do principal órgão que estava sendo estudado: o cérebro humano. A partir desse estudo, foi criado o conceito das redes neurais. Mas o que vem a ser uma rede neural?
Existem várias definições para redes neurais (RN). Vejamos, a seguir, algumas delas (REDES..., 2019).
Haykin (2001) enfatiza a visão de uma rede neural como uma máquina adaptativa, sendo um processador maciça e paralelamente distribuído, que tem a propensão natural para armazenar conhecimento experimental, por meio das forças de conexão entre células computacionais simples conhecidas como neurônios ou unidades de processamento.
Como pudemos perceber nas definições apresentadas, uma rede neural procura funcionar da mesma forma que o cérebro humano para resoluções de problemas, com base no conhecimento aprendido. Baseiam-se na estrutura de redes neurais biológicas de forma associada ao processamento paralelo de informações do cérebro humano.
Por fim, o neurônio artificial foi criado para se basear na modelagem de sistemas inteligentes que podem realizar várias tarefas, como classificação, reconhecimento e processamento de imagens, dentre outras. A posteriori, foi criado um sistema com diversos neurônios artificiais, o que foi denominado rede neural artificial (RNA).
Os estudos sobre redes neurais iniciaram na década de 1940, mais precisamente em 1943, quando o neurofisiologista Warren McCulloch e o matemático Walter Pitts publicaram um estudo sobre o funcionamento dos neurônios e, então, puderam modelar uma rede neural com base nos conhecimentos em circuitos elétricos. Além disso, em 1949, um outro estudo importante, de Donald Hebb, descreveu que os neurônios são fortalecidos em suas sinapses, à medida que são utilizados diversas vezes, o que é uma base para entender a maneira como os humanos aprendem (DEEP LEARNING, on-line).
Em 1956, um neurobiologista chamado Frank Rosenblatt começou a trabalhar no desenvolvimento de um projeto nomeado por Perceptron, cujo objetivo é calcular uma soma ponderada das entradas informadas, fazer a subtração de um limite e, a partir disso, informar um dos valores como possíveis resultados. Essa pesquisa é resultante da análise comportamental do olho de uma mosca, que, a partir das entradas informadas em seu campo de visão, subtrai algumas entradas e, então, toma a decisão para solucionar seu problema de fuga do ambiente (DEEP LEARNING, on-line).
Nos anos 1960, um projeto importante chamado MADALINE impulsionou os estudos nessa área. Esse foi o primeiro projeto aplicado a um problema real, que visava ao reconhecimento de padrões binários em uma chamada telefônica, em que, ao ler um bit, seria possível prever o próximo. Além disso, foi utilizado um filtro que tinha o intuito de eliminar ecos nas linhas telefônicas. Apesar de ser antigo, esse projeto ainda é utilizado de forma comercial (DEEP LEARNING, on-line).
Após isso, houve um grande hiato nas pesquisas em redes neurais, por vários estudos que provocam a viabilidade das pesquisas e os efeitos negativos associados à área. Somente nos anos 1980 é que houve um crescimento das pesquisas: em 1982, foram criados dispositivos úteis com base na modelagem do cérebro; em 1985, foi criada a reunião anual de RN; em 1987, foi realizada a primeira conferência sobre redes neurais do Institute of Electrical and Electronic Engineers (IEEE); em 1986, foi criado o conceito de redes de Backpropagation, que aprendem de forma mais lenta, porém, têm um resultado mais preciso (DEEP LEARNING, on-line).
Por fim, as redes neurais, a partir desse processo histórico, mais precisamente a partir dos anos 1980, ganhou muitos adeptos e, hoje em dia, são utilizadas em diversas aplicações. A essência por trás do desenvolvimento das redes neurais é que, se uma rede funcionar na natureza, ela tem uma alta probabilidade de funcionar nos computadores. Contudo, o desenvolvimento dessa área é dependente do avanço das pesquisas em hardware específico para uso, para, assim, desenvolverem redes neurais mais rápidas e eficientes.
Para que possamos entender melhor as redes neurais, é necessário entender as partes que compõem um neurônio: os dendritos são as zonas receptivas que têm como função captar as informações do ambiente ou de outras células que serão processadas pelo corpo celular e, posteriormente, distribuídas para outros neurônios ou células do corpo humano pelo axônio (vide Figura 3.11) (ASSIS, 2009):
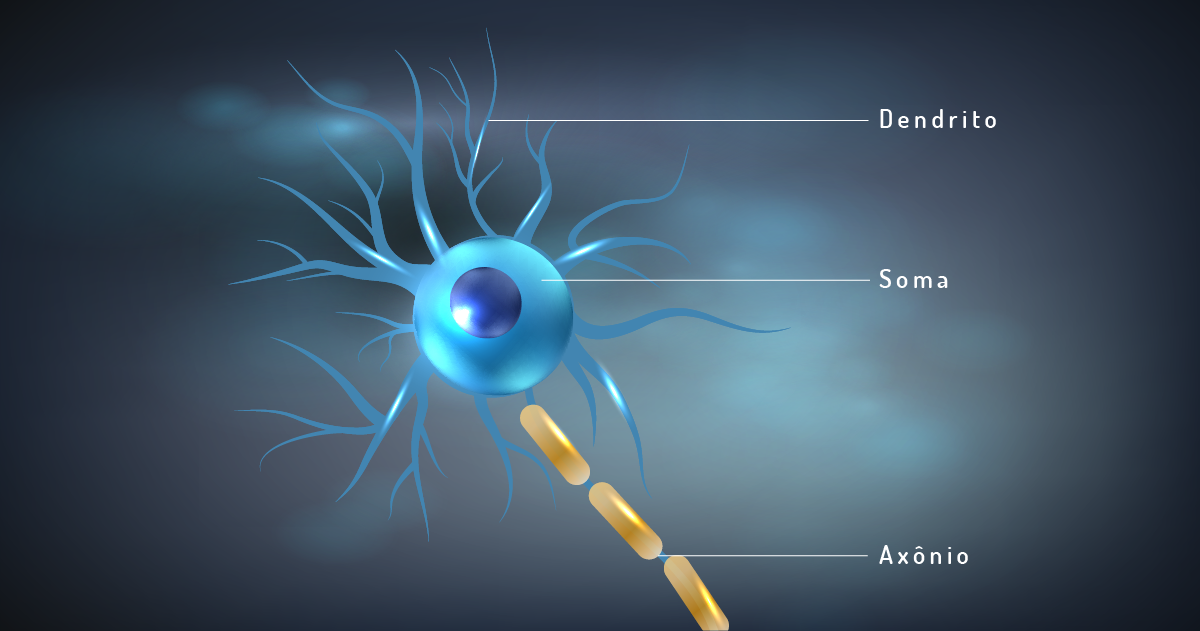
Cabe ressaltar que o cérebro humano tem milhões de neurônios, que, através das sinapses (ligações entre eles), conseguem resolver problemas complexos. Portanto, não são os neurônios isoladamente que possibilitam que os seres humanos realizem as mais variadas tarefas, mas, sim, as ligações estabelecidas por eles (DEEP LEARNING, on-line).
Assim, podemos ver que os neurônios podem ser vistos como pequenas unidades computacionais que realizam o processamento de informações provenientes do seu ambiente e se interligam com outros neurônios para a aprendizagem de um novo conhecimento. Com base nisso, foram produzidos os neurônios artificiais.
Cada neurônio possui dois ou mais receptores, que servem para a entrada de dados e percepção do tipo de sinal recebido; o corpo é formado por processadores que têm um sistema de feedback, que altera sua programação lógica dependendo dos dados de entrada, e a saída binária, que informa uma resposta formatada como “sim” ou “não”, dependendo do resultado que ocorreu no processamento (DEEP LEARNING, on-line).
Haykin (2001) identifica três elementos básicos para um modelo neuronal não linear, conforme apresentado na Figura 3.12 a seguir. Os sinais de entrada correspondem a estímulos provenientes do ambiente ou de sinapses (ligações) com outros neurônios. Cada entrada apresenta um peso sináptico, que será multiplicado pelo sinal entrante e que serão todos somados por meio de uma função de junção aditiva. A função de ativação é responsável pela ativação da saída de um neurônio, restringindo o intervalo permissível da amplitude do sinal de saída, sendo, geralmente, não linear e no formato sigmoidal. Esse modelo também apresenta a inclusão de um bias, que tem o efeito de aumentar ou diminuir a entrada líquida da função de ativação, dependendo se ele é positivo ou negativo.
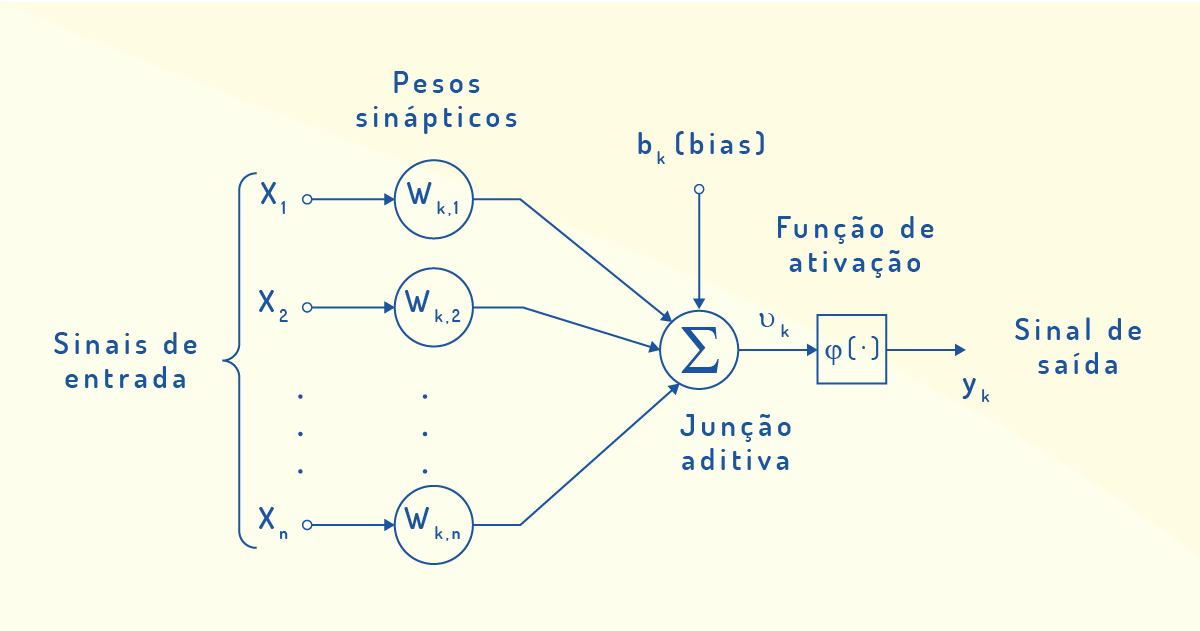
Como um neurônio pode receber várias entradas e tipos de sinais e realizar um único processamento, faz-se necessário conectar vários neurônios que são similares em rede para melhorar o desempenho do processamento de informações e, assim, produzir mais resultados. Tendo em vista essa conexão entre neurônios, arquiteturas de redes neurais são propostas em relação à organização na forma de camadas, como a de camada única e a multicamadas.
Na arquitetura de rede de camada única, temos uma camada de entrada que se projeta sobre uma camada de saída de neurônios (nós computacionais), conforme Figura 3.13, a seguir:
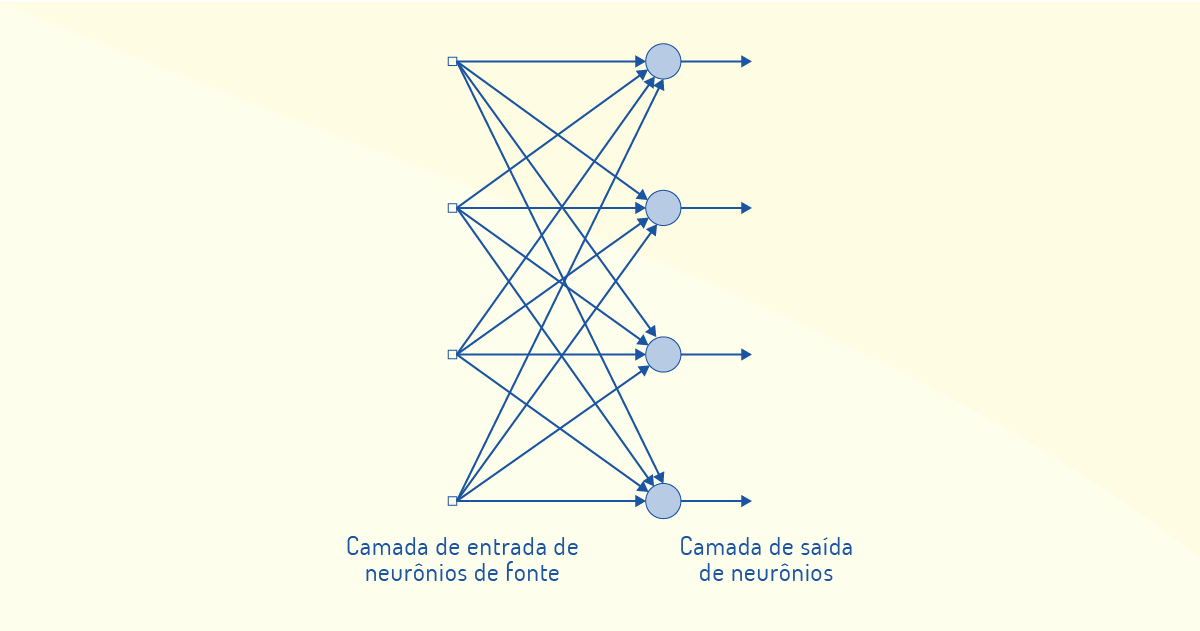
Essa rede se comporta como uma rede alimentada adiante (feed forward) ou acíclica, não permitindo loops na rede, como no caso das redes recorrentes, que apresentam laços de realimentação. As redes alimentadas adiante também são aplicadas na arquitetura de redes multicamadas, em que há camadas intermediárias de neurônios para processamento entre as camadas de entrada e saída. Essas camadas intermediárias são conhecidas de camadas ocultas e ajudam na extração de estatísticas de ordem elevada. Na Figura 3.14, temos uma ilustração de rede multicamada:
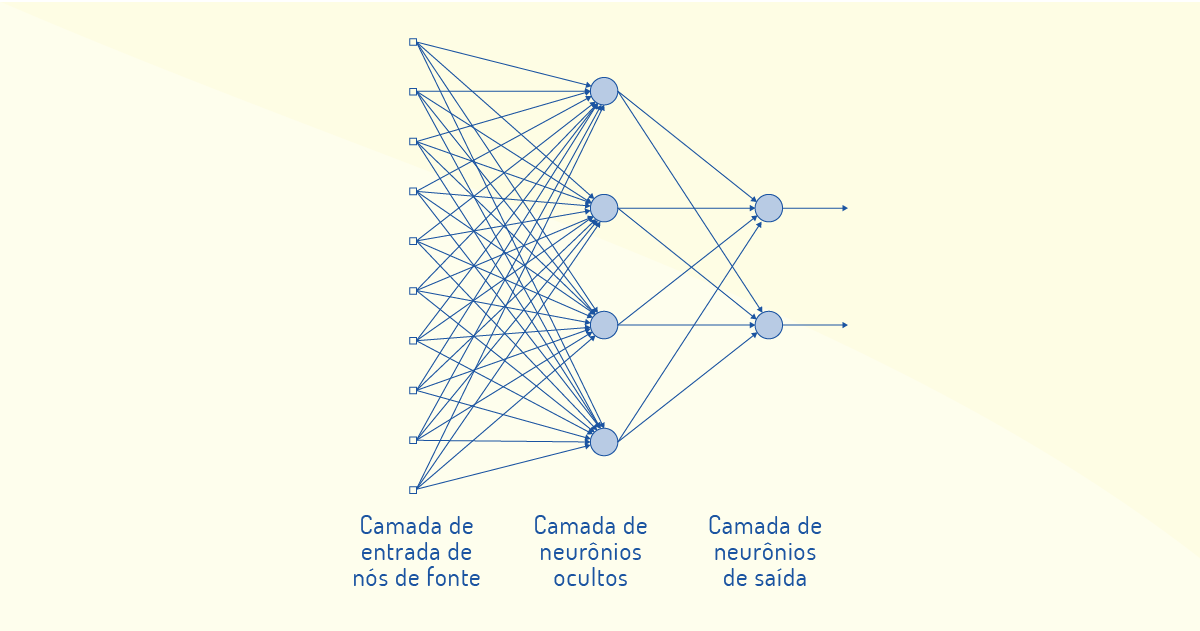
Os elos de comunicação entre os nós (neurônios) de diferentes camadas são chamados de conexões sinápticas e podem ser refletidos em uma rede neural totalmente conectada (todos os nós de uma camada ligados a todos os nós da camada adjacente) ou parcialmente conectada (algumas conexões faltando).
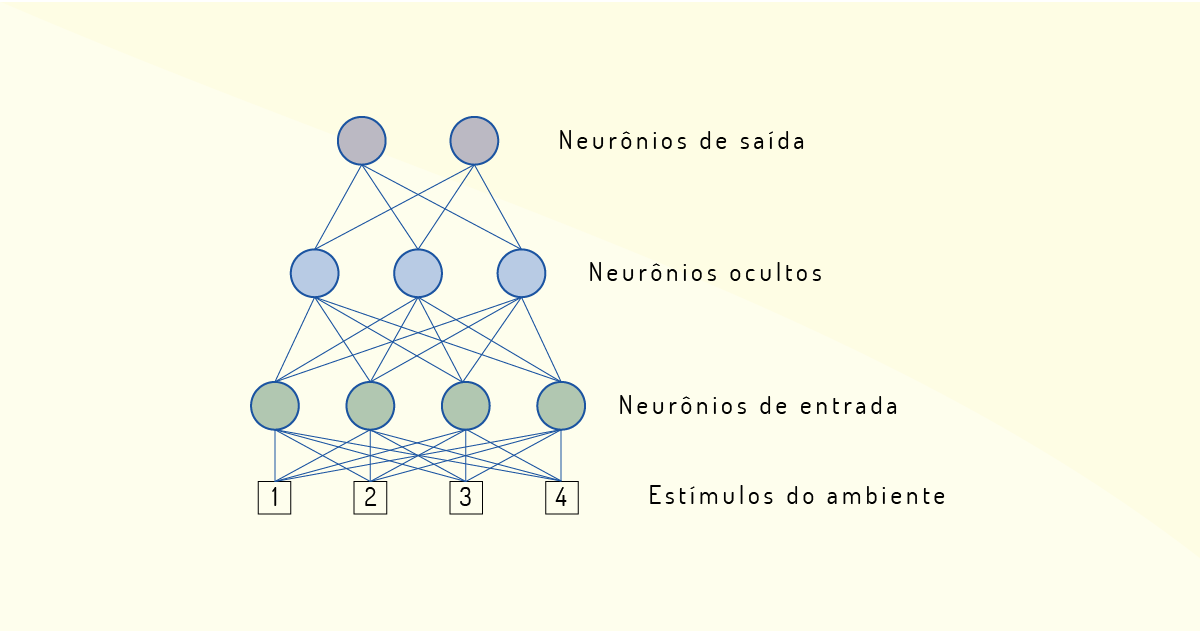
Vamos a um exemplo para entender melhor o funcionamento dos neurônios em uma rede neural: pode ser criado um sistema que visa identificar e diferenciar bananas de maçãs. Sendo assim, os neurônios serão sensíveis à cor e à forma, totalizando quatro: dois farão a identificação das cores amarelo e vermelho e, os outros, farão a percepção da forma (redondo ou comprido). Assim, cada neurônio poderá receber quatro entradas, mas, de acordo com sua configuração, ele só receberá a entrada para a qual foi configurado (ASSIS, 2009).
Por conseguinte, para obter um melhor desempenho desse sistema, é criada uma rede em camadas. Na primeira camada serão adicionados quatro neurônios, que recebem os estímulos do ambiente (cor amarela, vermelha, forma redonda ou comprida). Uma segunda camada (oculta) com três neurônios vai realizar o processamento dessas informações de entrada, enquanto a terceira camada vai informar se é maçã ou banana, por meio de dois neurônios (ASSIS, 2009). Veja a Figura 3.15:
O modelo mais simples de uso de uma rede de camada única ou multicamadas é o perceptron, que consiste em um único neurônio na camada de saída, utilizado para a classificação de padrões ditos linearmente separáveis (HAYKIN, 2001). Na Figura 3.16, temos um exemplo de rede perceptron de múltiplas camadas (também conhecida como MLP - Multi Layer Perceptron).
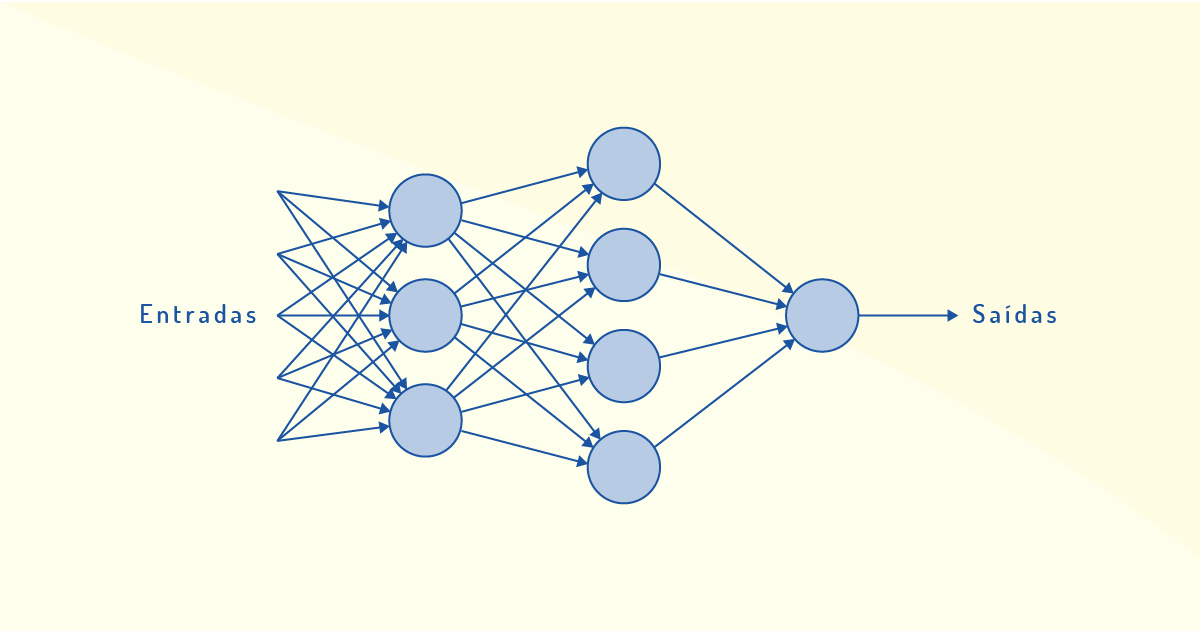
Nesse modelo, a primeira camada toma decisões simples, ponderando as evidências de entradas. Na segunda camada, novas decisões são tomadas, ponderando os resultados da primeira camada, em um nível mais complexo. E a complexidade da decisão aumenta à medida que outras camadas são utilizadas, até que seja atingida a camada de saída. Para tanto, os neurônios fazem uso de filtros adaptativos e algoritmo do mínimo quadrado médio (LMS).
O importante da rede neural é a forma como elas processam as informações; elas não executam programas, mas aprendem. Mas como isso é realizado? A rede neural de entrada testa várias vezes se o valor recebido de entrada é igual ao valor para o qual ela está configurada. Quando ela acerta, ela recebe uma pontuação, e a rede estabelecida entre ela é reforçada como o melhor caminho. Com os erros, os neurônios perdem pontos. Assim, o sistema sempre segue o caminho com maior pontuação e, quanto mais tentativas forem realizadas, mais aprimorado o sistema vai se tornando, passando a executar as tarefas quase sem erro (DEEP LEARNING, on-line).
O processo de aprendizagem é uma etapa fundamental para as redes neurais. Para tanto, podem ser adotadas aprendizagens supervisionadas, não supervisionadas, com ciclos iterativos de ajustes aplicados aos pesos sinápticos e boas para a melhoria do desempenho da rede.
Você pode entender melhor sobre isso no artigo Redes neurais artificiais, de Thomas Walter Rauber, disponível em: http://bit.ly/2TtX6Wc. Acesso em: 19 fev. 2020.
Portanto, uma rede neural funciona de forma diferente da lógica tradicional: ela aprende o que precisa ser realizado e executa essa função. Assim, uma rede capacitada possui os neurônios necessários para realizar uma tarefa de forma muito mais eficiente.
As redes neurais são utilizadas em diversas aplicações e podemos, então, dividir as redes em alguns temas macro, como: processamento de sinais, imagem e visão; categorização e controle de sistemas; identificação e classificação de padrões. Vale ressaltar que tais temas podem se comportar de diferentes formas, dependendo de como a rede neural está aprendendo.
Podemos citar algumas aplicações que utilizam redes neurais, como: reconhecimento de voz, identificação de e-mails como spam, computação em nuvem (cloud computing), mercado financeiro, agricultura, medicina, entre outros. São diversas áreas que realizam o uso de RN (DEEP LEARNING, on-line).
No reconhecimento de voz, por exemplo, a rede neural é utilizada para aprender a conhecer a voz de pessoas específicas; na identificação de e-mails como spams, a rede neural consegue identificar o que é um spam e os apaga, tendo uma boa margem de acertos. Um outro exemplo é a utilização de softwares OCR (Optical Character Recognition), utilizados em scanners que precisam aprender a reconhecer caracteres de imagem e utilizam a rede neural para isso. Algumas redes neurais são utilizadas em robôs para realizar o desarmamento de bombas (REDES..., 2019).
Um termo relacionado às redes neurais ganhou popularidade a partir dos anos 2000: aprendizagem profunda (deep learning), que é um tipo de aprendizado de máquina que é capaz de compreender, reproduzir e até melhorar comportamentos e padrões configurados previamente para aplicar de forma automática a mais dados, criando modelos que funcionam em tempo real e são executados em computadores, formando gigantescas redes neurais artificiais que se assemelham ao cérebro humano (REDES..., 2019).
Algumas empresas vêm utilizando esse algoritmo de aprendizagem profunda, como: a Google, que é capaz de identificar gatos nas fotos armazenadas por seus usuários; o Facebook, que criou o software DeepFace, que objetiva identificar e marcar os usuários de forma automática nas fotos armazenadas na rede social. A aprendizagem profunda (deep learning) é muito utilizada para reconhecimento de imagens, como podemos perceber nos exemplos citados (REDES..., 2019).
Por fim, o crescente processo evolutivo da inteligência artificial corrobora para o crescimento das redes neurais, em especial das classificadas como aprendizagem profunda. Dessa forma, é possível criar redes inteligentes autônomas que podem impactar diversos ramos da sociedade, a partir do uso de modelos matemáticos agregando padrões biológicos em IAs.
A Amazon Alexa, uma assistente virtual inteligente que conversa com o usuário para realizar suas tarefas diárias, e o Amazon Polly, um serviço que realiza a transformação de texto em falas reais, são produzidos pela empresa Amazon, a qual informou que tais serviços já estão realizando a conversão do texto em falas utilizando redes neurais em camadas.
Sobre as redes neurais em camadas, pode-se afirmar que:
a rede em camadas possui somente duas: a de entrada e a de saída. O processamento é realizado por uma IA externa.
Incorreta. O processamento é realizado pelos neurônios de processamento.
na rede em camadas, a primeira etapa é receber os estímulos do ambiente, que só podem ser aqueles que são pré-configurados na rede.
Incorreta. Os estímulos são realizados de forma aleatória.
em uma rede em camadas, a camada de neurônios de saída emite informações vagas e imprecisas.
Incorreta. As saídas são respostas de forma binária.
as camadas de uma rede neural são: neurônios de entrada, processamento e saída, que visam responder o problema de forma binária.
Correta. Em uma rede neural em camadas, as etapas são: entrada, processamento e saída, sendo realizadas por neurônios que serão treinados até atingir a solução correta do problema de forma binária. As respostas ao problema são valores binários.
em uma rede em camadas, a camada de entrada recebe os dados advindos do estímulo de forma padronizada.
Incorreta. Os dados vêm de forma aleatória, e a rede neural de entrada interpreta qual valor ela precisa receber para enviar para a fase de processamento.
Antes de iniciarmos o entendimento sobre esse tipo de sistema, é necessário definir o que é um especialista: é uma pessoa ou organização que detém o conhecimento, experiência e a habilidade de aplicar esse conhecimento para fornecer conselhos e solucionar problemas (LAUDON; LAUDON, 2015).
Partindo disso, podemos definir que um sistema especialista utiliza o conhecimento humano para solucionar problemas que necessitam da presença de um especialista. Esse tipo de sistema é uma categoria dos denominados sistemas baseados em conhecimento, já que a ferramenta principal para esse tipo de sistema é o conhecimento, e eles se propõem a solucionar problemas (O’BRIEN; MARAKAS, 2008).
Outra definição para esse tipo de sistema pode ser entendida como um programa de computador que usa tecnologias de inteligência artificial para simular o julgamento e o comportamento de um ser humano ou de uma organização que possui conhecimento especializado e experiência em um campo específico (LAUDON; LAUDON, 2015).
Normalmente, um sistema especialista incorpora uma base de conhecimento contendo experiência acumulada e um mecanismo de inferência ou regras – um conjunto de regras para aplicar a base de conhecimento a cada situação específica descrita no programa. Os recursos do sistema podem ser aprimorados com acréscimos à base de conhecimento ou ao conjunto de regras. Os sistemas atuais podem incluir recursos de aprendizado de máquina que lhes permitem melhorar seu desempenho com base na experiência, assim como os humanos (O’BRIEN; MARAKAS, 2008).
Em suma, uma base de conhecimento é uma coleção organizada de fatos sobre o domínio do sistema. Um mecanismo de inferência interpreta e avalia os fatos na base de conhecimento para fornecer uma resposta. Tarefas típicas para sistemas especialistas envolvem classificação, diagnóstico, monitoramento, projeto, programação e planejamento para empreendimentos especializados.
Fatos para uma base de conhecimento devem ser adquiridos de especialistas humanos por meio de entrevistas e observações. Esse conhecimento é geralmente representado na forma de regras “se-então” (regras de produção): “Se alguma condição for verdadeira, então a seguinte inferência pode ser feita (ou alguma ação tomada)”.
A base de conhecimento de um grande sistema especialista inclui milhares de regras. Um fator de probabilidade é frequentemente associado à conclusão de cada regra de produção e à recomendação final, porque a conclusão não é uma certeza. Por exemplo, um sistema para o diagnóstico de doenças oculares pode indicar, com base em informações fornecidas a ele, uma probabilidade de 90% de que uma pessoa tenha glaucoma e pode listar conclusões com probabilidades menores. Um sistema especialista pode exibir a sequência de regras por meio das quais chegou à sua conclusão. O rastreamento desse fluxo ajuda o usuário a avaliar a credibilidade de sua recomendação e é útil como uma ferramenta de aprendizado para os alunos (O’BRIEN; MARAKAS, 2008).
Além disso, sistemas especialistas apoiados por humanos frequentemente empregam regras heurísticas, ou “regras práticas”, além de simples regras de produção, como aquelas obtidas de manuais de engenharia. Assim, um gerente de crédito pode saber que um candidato com um histórico de crédito ruim, mas um registro limpo desde a aquisição de um novo emprego, pode, na verdade, ser um bom risco de crédito. Os sistemas especialistas incorporaram essas regras heurísticas e cada vez mais têm a capacidade de aprender com a experiência. Os sistemas especialistas continuam sendo ajudantes – em vez de substitutos – de especialistas humanos (LAUDON; LAUDON, 2015).
Vale ressaltar que o conceito de sistemas especialistas foi desenvolvido pela primeira vez na década de 1970, por Edward Feigenbaum, professor e fundador do Laboratório de Sistemas de Conhecimento da Universidade de Stanford. Feigenbaum explicou que o mundo estava passando do processamento de dados para o "processamento de conhecimento", uma transição que estava sendo possibilitada pela nova tecnologia de processador e pelas arquiteturas de computadores (LAUDON; LAUDON, 2015).
Sistemas especialistas têm desempenhado um papel importante em muitos setores, incluindo serviços financeiros, telecomunicações, saúde, atendimento ao cliente, transporte, videogames, fabricação, aviação e comunicação escrita. Dois sistemas especializados iniciais abriram espaço no setor da saúde para diagnósticos médicos: Dendral, que ajudou químicos a identificar moléculas orgânicas, e MYCIN, que ajudou a identificar bactérias como bacteremia e meningite e a recomendar antibióticos e dosagens.
Um sistema especialista desenvolvido mais recentemente, o ROSS, é um advogado artificialmente inteligente baseado no sistema de computação cognitiva Watson da IBM. O ROSS conta com sistemas de autoaprendizagem que usam mineração de dados, reconhecimento de padrões, aprendizado profundo e processamento de linguagem natural para imitar a maneira como o cérebro humano funciona (ROSS INTELLIGENCE, 2019).
Agora, vejamos a utilidade dos sistemas especialistas (LAUDON; LAUDON, 2015).
Podemos ressaltar, ainda, que os sistemas especialistas atuam em várias aplicações para prover maior agilidade e fornecer soluções produtivas para as empresas. Podemos citar que eles podem atuar em algumas categorias de aplicações das organizações, como no gerenciamento de decisões, monitoração e/ou controle de processos da empresa, diagnóstico e/ou problemas operacionais relacionados a uma tarefa em específico, entre outras.
Além disso, podemos dizer que os sistemas especialistas podem atuar nos sistemas relacionados à contabilidade, utilizados em fluxos de caixa, contas a receber e a pagar, entre outras áreas relacionadas à contabilidade; no planejamento de recursos de capital quando auxilia nas decisões de investimentos da organização; na produção em que as tarefas repetitivas podem ser realizadas por robôs; na gestão financeira em que podem ser utilizados na análise de investimentos, entre outros (O’BRIEN; MARAKAS, 2008).
No entanto, segundo O’Brien e Marakas (2008), algumas limitações dos sistemas especialistas podem ser elencadas, como:
Portanto, podemos dizer que os sistemas especialistas são muito eficazes nas empresas e a sua utilização promove resultados positivos nas organizações. Vale ressaltar que é um tipo de tecnologia que fornece para as empresas maior agilidade, retorno eficaz na gestão, qualidade do serviço, soluções rápidas para os problemas organizacionais, aumento da produtividade, bem como mantém as empresas com competitividade no mercado.
Sistemas especialistas são programas de computadores que utilizam conceitos de Inteligência Artificial utilizado para a solução de problemas complexos da mesma forma que um especialista. Sobre o especialista, é correto afirmar que:
é uma pessoa ou organização que terá a formação de especialista para poder utilizar o sistema especialista.
Incorreta: Para utilizar o sistema especialista, não precisa ser um especialista, já que a IA vai simular o comportamento do especialista, o qual funcionará somente como avaliador do sistema.
é uma pessoa ou organização que detém o conhecimento, experiência e a habilidade de aplicar esse conhecimento para fornecer conselhos e solucionar problemas.
Correta: O especialista é aquele que detém o conhecimento sobre uma área específica e possui a habilidade para fornecer soluções para os problemas expostos dentro dessa área de conhecimento.
é um sistema de informação que utiliza dados e informações processadas para gerar conhecimento.
Incorreta: O especialista já possui os dados e informações que formam o conhecimento para gerar base de conhecimento em sistemas especialistas.
é um sistema ou organização que, apoiado na abordagem da inteligência artificial, gera o conhecimento para que uma pessoa o analise e, assim, gere informação relevante.
Incorreta: O conhecimento é repassado para a IA, que vai analisá-lo e aprender com os conceitos adquiridos, até que possa ser gerado de forma automatizada.
é uma pessoa que detém poucos conhecimentos na área e será especialista após utilizar esse tipo de sistema.
Incorreta: O especialista precisa ser expert na área de conhecimento para a solução do problema, já que funcionará como avaliador do sistema.
Nome do livro: Inteligência Artificial
Autores: Peter Norvig e Stuart Russel
Editora: Elsevier
ISBN: 9788535237016
Comentário: Esse é um livro de referência e foi o primeiro a abordar, de forma didática, os principais conceitos inerentes à Inteligência Artificial. Com ele, você aprenderá sobre o histórico de IA, suas principais aplicações e sua evolução em diferentes áreas de pesquisa.
