Tópicos Especiais em Sistemas de Informação
Caro(a) aluno(a), na primeira unidade da disciplina de Tópicos Especiais em Sistemas de Informação, vamos estudar sobre Big Data. O termo faz referência a grandes massas de dados, em sua maioria, não estruturados, ou seja, dados que se apresentam de diversas formas devido à variedade de fontes que o produzem, por exemplo: redes sociais, sistemas de comércio eletrônico, ferramentas de gestão e até objetos conectados na internet. Não apenas a quantidade destes dados tem aumentado, mas também a velocidade com que esses dados precisam ser processados. Essa demanda surge com a necessidade de tomadas de decisões, praticamente em tempo real. As tomadas de decisões tornaram-se o principal objetivo das ferramentas de Big Data. Empresas têm investido cada vez mais neste recurso para poder ter sucesso em suas áreas de negócio. Essas tomadas de decisões envolvem problemas complexos e, por este motivo, diversos processos foram modelados para que fosse possível criar soluções de forma otimizada, utilizando os diversos recursos existentes.
Nesta disciplina, vamos entender inicialmente as definições que envolvem a origem do Big Data, como dado e informação. Vamos observar em quais áreas estão sendo aplicadas e suas principais características. Em seguida, verificaremos suas formas de aplicação por meio de diversas ferramentas. E, por fim, vamos analisar as aplicações reais em que o uso dos conceitos estudados auxilia a resolução de algum problema do mundo real.
Nós vivemos na era dos dados. A tendência é que a quantidade de dados gerada por cada indivíduo cresça, mas talvez a quantidade de dados gerados por máquinas, como parte da internet das coisas (Internet of Things - IoT), cresça mais significativamente. Logs de máquinas, leitores RFID (Radio Frequency Identification, ou seja, Identificação por Radiofrequência), rede de sensores de obras, vestígios de GPS (Global Positioning System, isto é, Sistema de Posicionamento Global) de veículos e até mesmo transações de varejo contribuem para a crescente montanha de dados.
White (2015) apresenta algumas informações sobre gerações de dados em massa:
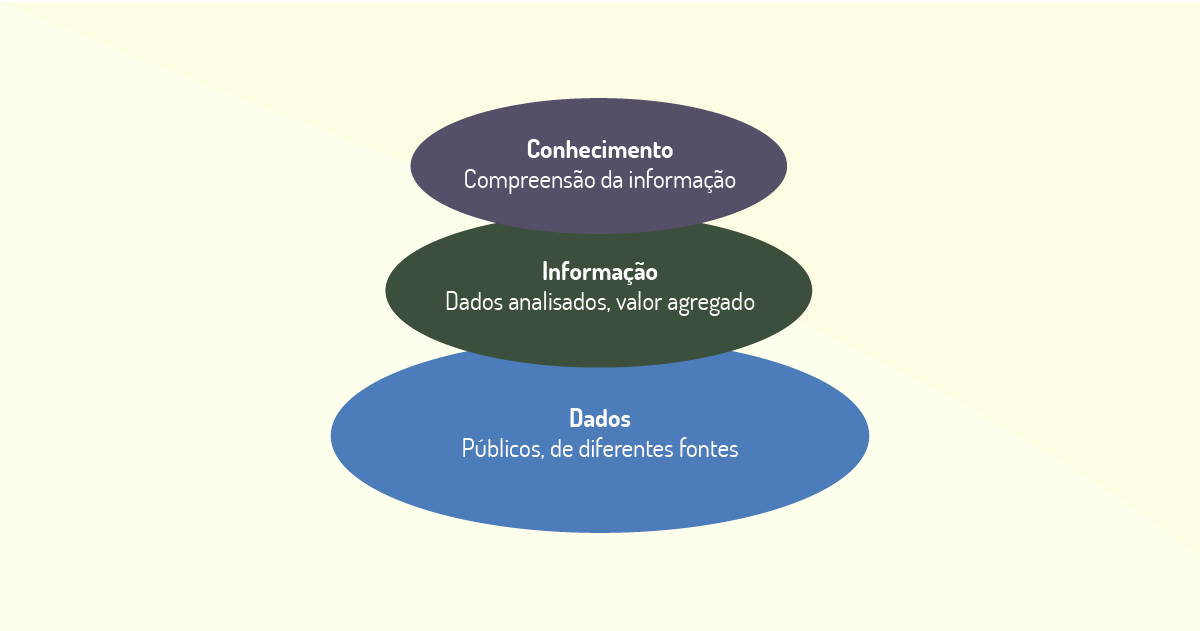
Dado é o elemento que representa fatos ocorridos antes que tenham sido organizados ou arranjados de maneira que as pessoas possam entender e usar (TAURION, 2013). Pode ser considerado qualquer registro que tenha relação a um evento ou uma ligação a uma entidade (AMARAL, 2016). Dados são representações brutas, como números soltos. Quando os dados são cruzados ou organizados, passam a ser informações. Por exemplo, o número 12 pode representar uma série de coisas: pode ser uma dúzia de ovos, a quantidade de produtos em estoque, ou até um dia se for colocado no formato 12/09/2019. Neste caso, o número 12 passa a ser um dado, mas já com algum tipo de informação. Se associado ao nascimento de uma pessoa, transformamos o 12 na sua data de nascimento. Isso é uma informação sobre ela. Dados só terão significados se cruzados e organizados, transformando-se, portanto, em informações. Reforçando a ideia: uma tabela com nomes e notas de alunos pode ser considerada um conjunto de dados.
Para Davenport (1998), os dados são simples observações sobre o estado do mundo e apresentam as seguintes características:
Já a informação pode ser definida como a interpretação de um conjunto de dados. Ela é o resultado da análise realizada a partir de dados apresentados de tal forma que permita a realização dessas interpretações. A informação exige consenso em relação ao significado e requer, necessariamente, a mediação humana (DAVENPORT, 1998).
A informação pode ser vista como a interpretação pessoal para um conjunto de dados, a relação que estabelece com outros dados e o contexto no qual elas estão inseridas. Um mesmo conjunto de dados pode gerar informações diferentes para indivíduos distintos, pois serão analisadas dentro dos próprios contextos. Retomando o exemplo da tabela de notas: as informações geradas a partir das médias dos alunos podem produzir uma série de conclusões acerca da turma avaliada (AMARAL, 2016).
Isso nos direciona a outra definição referente ao uso dos dados: o conhecimento. Segundo Davenport (1998, p. 19): “Conhecimento é a informação valiosa da mente humana, inclui reflexão, síntese e contexto, além disso é de difícil estruturação, transferência e captura em máquinas”. Uma relação dos conceitos pode ser observada na Figura 1.1.
Segundo Taurion (2013), os dados podem ser vistos como recursos naturais da sociedade da informação. Porém, para agregar esse valor é necessário tratá-los e analisá-los para que possam ser usados para tomadas de decisões. Como comentamos anteriormente, não é fácil medir o volume total de dados gerados eletronicamente, uma vez que atualmente coletamos informações para armazenamento de diversas fontes e em tempo real.
Os dados podem ser representados em formato analógico, digital ou impresso, como as bibliotecas, que concentram a maior quantidade de dados impressos no mundo (AMARAL, 2016). Porém, no contexto que estamos estudando, vamos nos fixar apenas no formato dos dados digitais, transmitidos por meio de pacotes de bits (zeros e uns), de forma mais eficiente.
Dados em sua forma digital, objeto do nosso estudo, são produzidos por algum tipo de dispositivo eletrônico e passam a integrar um processo que vai da sua preservação até a extração de informações para diversos usos (AMARAL, 2016). Existem várias formas para se extrair e preservar dados, Amaral (2016) apresenta algumas delas:
O processo de produção de dados até a sua utilização final é denominado ciência de dados (data science). Como todo processo, também possui um ciclo de vida (Figura 1.2).
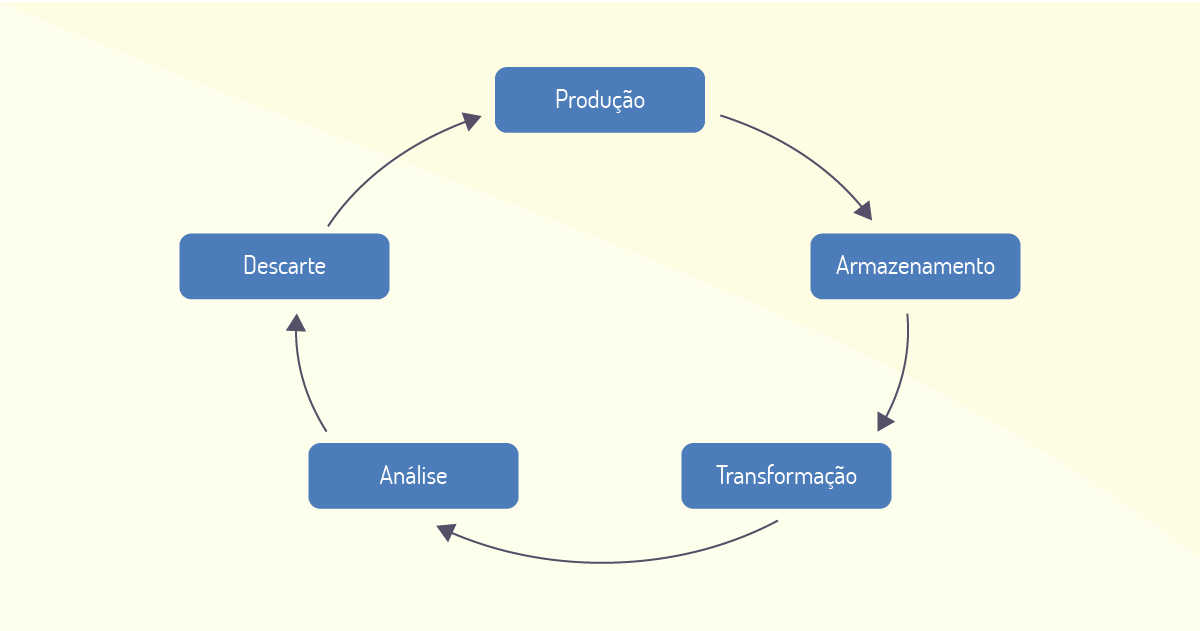
Cada etapa do processo do ciclo de vida demanda diferentes ferramentas que auxiliam as atividades do processo. Esse campo é amplo e tem gerado novas tecnologias que rapidamente são incorporadas para dinamizar os estudos das análises de dados. A Figura 1.3 representa a distribuição de algumas das tecnologias utilizadas em cada etapa do ciclo de vida dos dados.
Para que os dados possam ter o ciclo de vida completo, em algum momento, precisam ser armazenados e analisados, este ponto do processo será o objeto do nosso estudo.
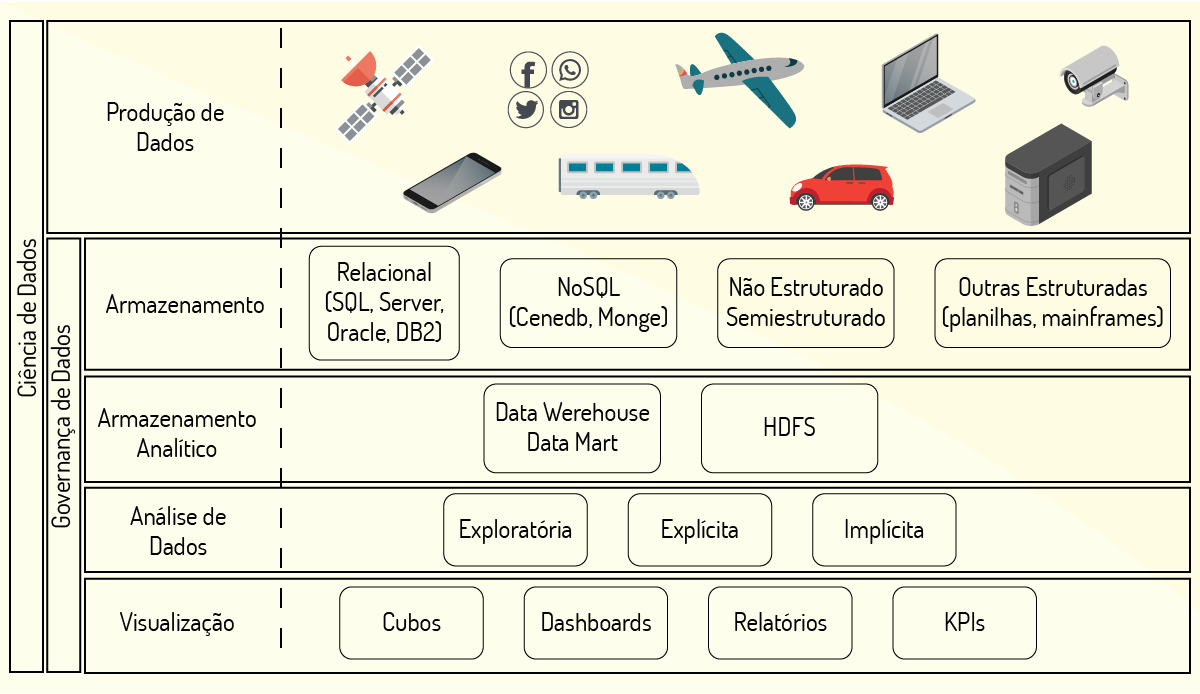
A figura apresenta um esquema para as tecnologias que produzem dados na Web 2.0 por meio das mídias sociais e que são impulsionadas pelo crescimento da IoT. Outras informações apresentadas na imagem são as tecnologias para armazenar, analisar e disponibilizar dados que auxiliam na tomada de decisão.
Como podemos perceber, dados são representações brutas do mundo real. Já as informações são dados processados e transformados em conhecimento, tornando-se úteis para as pessoas. Para que esses dados sejam convertidos em informação, são necessárias técnicas de armazenamento e de processamento. Nos próximos tópicos, vamos conhecer e entender como as ferramentas auxiliam esse processo de transformação dos dados.
Com a necessidade de transformação dos dados surgiu também a demanda por sistemas que armazenam grandes volumes de dados complexos, denominados de Big Data. Eles podem ser definidos como um arranjo de dados que o software tradicional não consegue gerenciar e, portanto, são utilizadas ferramentas específicas para o seu efetivo tratamento, armazenamento e processamento (TAURION, 2013).
Essas ferramentas têm o intuito de analisar dados não estruturados que não apresentam relação entre si e não possuem uma estrutura organizada. Como exemplo podemos citar os arquivos de áudio e vídeo, comentários em redes sociais, geolocalização utilizada em diversos aplicativos, entre outros.
Ferramentas comuns, como o Excel, são utilizadas para tratar dados estruturados, como os preços dos produtos de uma lista de supermercado. Por outro lado, as ferramentas de Big Data analisam dados não estruturados e suportam grandes quantidades, além de realizarem análises em alta velocidade (FAWCETT; PROVOST, 2016).
A criação e a utilização de tecnologias Big Data tem crescido consideravelmente, pois estão sendo empregadas no apoio às atividades relacionadas com mineração de dados. A mineração de dados tem por objetivo explorar massas de dados à procura de padrões que sejam consistentes e que possam gerar novos significados a um subconjunto de dados originais (MOURA, 2018). Esse processo foi desencadeado devido à redução de custos de tecnologias para armazenamento de dados, bem como ao crescimento de dispositivos capazes de produzir esses dados de forma massiva. Recentemente, criou-se a "Computação em Nuvem" e a "Internet das Coisas" (AMARAL, 2016).
A série Black Mirror (produzida pela Netflix) aborda em seus episódios a relação da sociedade com a tecnologia em uma perspectiva futurista e algumas vezes sombria. No primeiro episódio da segunda temporada, intitulado “Be Right Back”, depois de perder o namorado em um acidente e descobrir que estava grávida, a personagem Martha resolve contratar um serviço de tecnologia que, por meio dos dados de e-mail e de redes sociais de seu companheiro, disponibiliza um serviço que promete diminuir a dor do luto. Depois de entregar os dados da conta de e-mail e das redes sociais, o serviço contratado atuava em etapas: inicialmente, simulava a voz e a personalidade do namorado em conversas telefônicas, posteriormente, na etapa final, Martha recebeu uma versão android que se assemelhava fisicamente ao seu namorado. As informações coletadas anteriormente foram projetadas como memórias no robô. Com o passar do tempo, Martha percebeu que faltavam características humanas, uma vez que o robô apenas seguia suas ordens. Ao tentar desfazer seu “erro”, ela pediu para que o robô se jogasse de um penhasco e, para sua surpresa, ele não a obedeceu e implorou por sua “vida”. Por fim, ela atendeu ao pedido, mas o manteve guardado no sótão.
O episódio nos faz refletir sobre quais são as reais aplicações da utilização de dados disponibilizados na rede. Qual sua opinião sobre a atitude de Martha tentar interferir no ciclo natural da vida (como o luto após a morte)? Da forma como foram apresentadas, essas deveriam ser preocupações de quem produz ferramentas para Big Data?

Outro fenômeno que auxiliou no crescimento das ferramentas para Big Data foi o fato de grandes empresas adotarem as tecnologias web para ampliar suas operações. Na Web 1.0, as empresas começaram a estabelecer presença na internet e incorporar suas tecnologias para serviços, como o comércio eletrônico (FAWCETT; PROVOST, 2016). A Figura 1.4 exemplifica um esquema para este novo contexto.
Após marcar presença na web e implantar alguns serviços, as empresas passaram a buscar a melhoria do que já ofertavam, aproveitando as mudanças que chegaram com a Web 2.0, começaram a produzir sistemas mais interativos, conectados às mídias sociais (AMARAL, 2016).
O principal objetivo das ferramentas de Big Data é processar grandes massas de dados. Esse processamento representa um dos grandes desafios tecnológicos da área, uma vez que se faz necessária a utilização de infraestruturas e tecnologias analíticas que suportem tais atividades. Um elemento que pode facilitar esse processo é a Computação em Nuvem. Essa deve ser a maior mudança nos serviços oferecidos pela internet: a consolidação do uso de ferramentas para armazenar e analisar grandes massas de dados (TAURION, 2013). O que alguns autores já definem como Web 3.0.
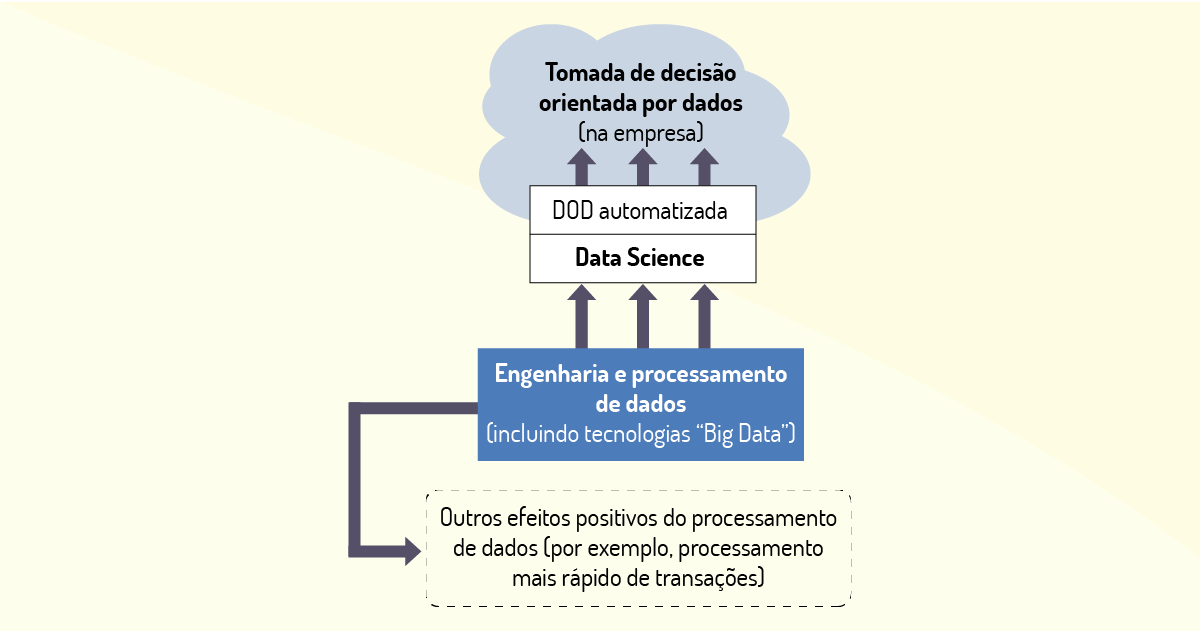
Entendendo Big Data como a produção de ferramentas para produção e armazenamento de dados em grande escala, bem como as tecnologias de extração e análise, precisamos visualizar as mudanças que essas ferramentas trarão para a indústria ao contribuírem com processos produtivos mais eficientes e com menores custos, ampliando o relacionamento das grandes empresas com seus clientes, fornecedores e parceiros comerciais. É a indústria 4.0.
A indústria 4.0 (ou a 4a revolução industrial), como definem alguns autores da área, se constitui de uma massiva utilização de ferramentas e de sistemas conectados, trabalhando com análise de grandes massas de dados em tempo real para ampliar as relações entre produtos, empresas, serviços e clientes. Além disso, tem o objetivo de otimizar e reduzir custos de produção. Para saber mais, seguem alguns links que abordam esse tema sob diferentes pontos de vista: http://bit.ly/2wmbdou e http://bit.ly/2PHnFWM. Acesso em: 14 jan. 2020.

Nesse novo modelo de negócio em que os dados dão suporte às decisões das empresas torna-se mais fácil definir quais abordagens são interessantes para o crescimento do empreendimento. Fawcett e Provost (2016) destacam duas formas nas quais esses modelos de decisão podem ser aplicados: as novas descobertas e as decisões que se repetem com frequência.
Nos próximos tópicos, os demais aspectos relacionados ao Big Data serão detalhados para que se construa uma visão mais abrangente dessa ferramenta e da sua atuação dentro dessa nova era da tecnologia.
Ferramentas de Big Data podem, entre suas diversas atividades, ampliar o relacionamento do consumidor com um determinado produto ou empresa por meio das análises de dados geradas por informações disponibilizadas por seus usuários. Analise as afirmações a seguir e assinale a alternativa que represente as ações que se encaixam em atividades que têm relação com o uso de Big Data.
I. Sugestão de novos artistas - baseada nas preferências musicais do cliente.
II. Realização de cadastro do usuário em sistemas de compras on-line.
III. Gerar descontos específicos - baseados nos hábitos de compras do cliente.
IV. Indicação de produtos relacionados a itens adquiridos em compras anteriores.
V. Proposta de uma rota de trânsito específica para evitar engarrafamentos.
Estão corretas:
I – II – III – V.
Incorreta. Item I correto: sistemas de Big Data utilizam preferências para realizar novas sugestões a seus usuários.
Item II errado: cadastros são atividades dos bancos de dados relacionais, portanto, estão fora do contexto das atribuições do Big Data.
Item III correto: hábitos de compras são utilizados em sistemas de Big Data para gerar novas oportunidades de compra por meio de pontos que podem ser usados em novas aquisições ou descontos efetivos no valor final do produto.
Item V correto: sistemas que sugerem rotas de trânsito coletam dados em tempo real para permitir ao usuário desvios em caso de retenção de fluxo devido a acidentes ou grandes quantidades de automóveis na mesma rota.
I – II – III – IV.
Incorreta. Item I correto: sistemas de Big Data utilizam preferências para realizar novas sugestões a seus usuários.
Item II errado: cadastros são atividades dos bancos de dados relacionais, portanto, estão fora do contexto das atribuições do Big Data.
Item III correto: hábitos de compras são utilizados em sistemas de Big Data para gerar novas oportunidades de compra por meio de pontos que podem ser usados em novas aquisições ou descontos efetivos no valor final do produto.
Item IV correto: sistemas de compras utilizam históricos de compras conjuntas para indicar outras mercadorias aos seus usuários. Exemplo quem comprou o item A, também comprou o item B.
I – III – IV – V.
Correta. Item I correto: sistemas de Big Data utilizam preferências para realizar novas sugestões a seus usuários.
Item III correto: hábitos de compras são utilizados em sistemas de Big Data para gerar novas oportunidades de compra por meio de pontos que podem ser usados em novas aquisições ou descontos efetivos no valor final do produto.
Item IV correto: sistemas de compras utilizam históricos de compras conjuntas para indicar outras mercadorias aos seus usuários. Exemplo quem comprou o item A, também comprou o item B.
Item V correto: sistemas que sugerem rotas de trânsito coletam dados em tempo real para permitir ao usuário desvios em caso de retenção de fluxo devido a acidentes ou grandes quantidades de automóveis na mesma rota.
II – III – IV – V
Incorreta. Item II errado: cadastros são atividades dos bancos de dados relacionais, portanto, estão fora do contexto das atribuições do Big Data.
Item III correto: hábitos de compras são utilizados em sistemas de Big Data para gerar novas oportunidades de compra por meio de pontos que podem ser usados em novas aquisições ou descontos efetivos no valor final do produto.
Item IV correto: sistemas de compras utilizam históricos de compras conjuntas para indicar outras mercadorias aos seus usuários. Exemplo quem comprou o item A, também comprou o item B.
Item V correto: sistemas que sugerem rotas de trânsito coletam dados em tempo real para permitir ao usuário desvios em caso de retenção de fluxo devido a acidentes ou grandes quantidades de automóveis na mesma rota.
Todas as afirmativas estão corretas.
Incorreta. O item II não representa uma atividade relacionada com o uso de Big Data.
Com a complexidade e a quantidade de dados gerados atualmente, as soluções de Big Data precisam ser consistentes. Segundo Taurion (2013), o Big Data apresenta alguns aspectos que comumente chamamos de 5 Vs: volume, velocidade, variedade, veracidade e valor. Essas características indicam que ao utilizar ferramentas de Big Data a empresa obtém respostas com maior completude, já que possui uma grande quantidade de informações disponibilizadas, e com essas respostas pode-se ter maior confiança nos dados, possibilitando uma tomada de decisão mais precisa. Sobreiro (2018) e Taurion (2013) definiram cada um dos 5 elementos e descreveram sua importância para ferramentas de Big Data.
Tente imaginar a quantidade de informações geradas através do envio de e-mails, mensagens, fotos e vídeos nas redes sociais. Parece incalculável. Agora pense em como armazenar essas mesmas informações utilizando recursos de tecnologia. Essa é a função do Big Data: armazenar uma quantidade de dados muito grande utilizando ferramentas tecnológicas, visando melhorar o processamento destes dados.
O aumento na capacidade de processar grandes quantidades de dados é uma das principais relevâncias do Big Data. Essa melhoria gerou novos modelos de análise dos dados. Um exemplo é a integração com outras ferramentas de análise de dados, como tecnologias de Business Inteligence (BI). BI é o termo aplicado para classificar o uso de ferramentas que empregam os conceitos de análise de dados para auxiliar em atividades de tomada de decisão. Tecnologias para Big Data são criadas de forma a ser flexíveis e conseguem exportar dados através de arquivos como Excel, ou elementos que possam ser explorados em outros tipos de sistemas como o JSON (JavaScript Object Notation), ou simplesmente conectar-se a tecnologias que façam análise de dados de forma semelhante como o BI.
A empresa Heikima desenvolve soluções para Big Data e disponibilizou um e-book para iniciantes no assunto apresentando os conceitos, ferramentas e alguns casos de sucesso relacionados a Big Data e Data Analytics. Acesse o link e leia o e-book: https://www.academia.edu/36849026/O_GUIA_DEFINITIVO_DE_BIG_DATA_PARA.
Acesso em: 14 jan. 2020.
Em relação ao volume, as ferramentas de Big Data também criam um desafio para estruturas de armazenamento de dados como sistemas distribuídos. A tendência da produção de dados é aumentar com o tempo, assim, não seria possível impor um limite de dados para esse tipo de ferramenta. Com o passar do tempo, as atualizações de estruturas de armazenamento de dados precisarão lidar com soluções visando a produção de dados em massa.
Com o aumento dos dados, algumas características passaram a ser fundamentais em ferramentas de Big Data e o retorno dos dados processados é uma delas. As aplicações precisam não apenas armazenar, mas também tratar os dados e deixá-los disponíveis de forma rápida, pois outras aplicações dependem dessa agilidade para o andamento de suas atividades.
A velocidade é a característica das ferramentas de análise de dados e se refere à taxa de tempo para que os dados processados fiquem disponíveis. Pode ser definida com o tempo de retorno de um dado desde a sua entrada até a tomada de decisão relativa ao seu processamento. A etapa pode ser definida como processamento complexo de eventos.
O tempo que o sistema leva para gerar esse processo pode colocá-lo em vantagem no mercado, pois as atividades geralmente estão ligadas às informações que precisam ser enviadas rapidamente, como a liberação de descontos para clientes de um serviço de compras, ou dados de localização em tempo real.
Segundo o relato de diversos autores, a variedade está relacionada ao formato dos dados que, juntamente com o volume e a velocidade, formam os 3 Vs principais do Big Data. Os dados podem surgir de diversas formas, podendo servir como base de dados ou simples fonte de informação para outros sistemas.
A variabilidade é a característica do Big Data responsável pelo armazenamento e tratamento de tipos de dados em diversos formatos. Essa característica que denota a flexibilidade do Big Data torna a ferramenta mais atrativa comercialmente e abre portas para o uso eficaz em diversas áreas de atuação. Sobreiro (2018) lista alguns tipos de dados utilizados em ferramentas de Big Data em diferentes tipos de aplicações:
Em ferramentas de análises de dados, deve ser possível a integração desses e outros tipos de dados para diversas finalidades.
É a característica dos dados relativos à sua precisão e correção. Sistemas de todo tipo recebem dados sem um controle do formato. Com as ferramentas de Big Data não seria diferente. Para armazenar dados é preciso ter a certeza de sua qualidade, o Data Warehouse (DW), por exemplo, utiliza uma ferramenta chamada ETL (Extract, Transform and Load). Essa ferramenta realiza sistematicamente o tratamento e a limpeza dos dados para inserção no DW.
Como o Big Data preza pela velocidade e pela variedade dos dados, esses fatores podem influenciar na determinação da veracidade. A velocidade faz com que o tempo disponível não suporte ferramentas com as atribuições do ETL, uma vez que as novas informações recebidas precisam ser processadas e disponibilizadas de forma rápida. A variedade dos tipos de informações recebidas demanda adaptações para que se possa trabalhar com os diversos formatos de arquivos e as formas personalizadas para lidar com cada tipo de dado.
Um grande desafio posto pelo Big Data é determinar a veracidade dos dados disponíveis para a sua empresa de forma que as informações possam servir de guia para um planejamento seguro. Talvez esse seja o aspecto mais relevante, visto que a tomada de decisão baseada em dados incorretos pode ser catastrófica.
A atividade de transformação dos dados é importante para alimentar o DW, entretanto essa atividade gera uma grande carga de trabalho, já que os dados são carregados de fontes diversas e precisam ser selecionados e padronizados para gerar os repositórios do DW de forma que apenas os dados relevantes possam fazer parte desse repositório. Para entender mais sobre esse processo, acesse o link a seguir: http://bit.ly/3aoOwP1. Acesso em: 14 jan. 2020.
Para que as massas de dados, às quais as ferramentas de Big Data têm acesso, possam gerar mais lucros é preciso agregar valor às atividades. O valor é relacionado aos objetivos do uso dos dados. A definição da abordagem que será feita com a massa de dados que está circulando é um dos desafios enfrentados pelas empresas que utilizam Big Data. Ou seja, o valor está relacionado ao quão importantes os dados são para as empresas e quais benefícios podem ser extraídos por meio desses dados.
O valor de um dado está relacionado à descoberta de padrões, em outras palavras, seriam as preferências de usuários que podem acarretar ganhos significativos para quem depende de sua interpretação, por exemplo.
A qualidade também pode ser vista como um critério de valor. Algumas características como a exatidão, a integridade, a consistência e a relevância também podem ser concebidos como critério que imputam valor a um dado (GALDINO, 2016).
Nem todo dado é relevante ou útil para quem o coleta. Outro aspecto que pode gerar valor a um dado é a percepção de quem analisa: é necessário realizar uma triagem por intermédio de questionamentos que possam gerar uma análise acerca de sua abordagem para o uso ou não dos dados que foram previamente coletados (TAURION, 2013).
As ferramentas para Big Data têm a finalidade de auxiliar no processamento e armazenamento da grande massa de dados gerados de diversas formas, pois com a crescente demanda, surge a necessidade de tecnologias que possam suportar as atividades realizadas (GALDINO, 2016). O Hadoop é uma das ferramentas mais utilizada para análise de dados em massa. Sua arquitetura distribuída permite armazenar e processar grandes quantidades de dados de forma rápida. Além do seu poder computacional, outras características que agregam valor na sua utilização são: tolerância a falhas, flexibilidade e escalabilidade. Vamos entender melhor essas características e como essa estrutura funciona no contexto de análises de dados.
O Hadoop é uma das tecnologias que mais se destacam para análise de dados em massa. Foi criado em 2005 em um projeto da empresa Apache e divide as tarefas que serão realizadas em servidores (TAURION, 2013). Entendido como como um conjunto de programas que dão suporte às operações voltadas para armazenamento e análise de dados, as atividades relacionadas ao Hadoop são combinadas em dois projetos: o Hadoop MapReduce (HMR) e o Hadoop Distributed File System (HDFS). Sua natureza flexível permite a adaptação dos componentes de seu sistema de acordo com as necessidades específicas da empresa que o utiliza (SOBREIRO, 2018).
O Hadoop MapReduce teve origem a partir de uma ferramenta que o Google empregava para acelerar o resultado das pesquisas, o MapReduce. Esse componente é baseado em um modelo de programação mais simples que permite o aumento da estrutura, sem necessariamente aumentar os custos (escalabilidade), por meio do uso de servidores de forma paralela (TAURION, 2013). Sua execução consiste em duas atividades: a) o mapeamento dos conjuntos de dados, transformando-os em uma relação chave/valor (ou tupla), chamado de Map; e b) o processamento dos dados para extração dos resultados, chamado de Reduce (SOBREIRO, 2018).
O Hadoop Distributed File System é o componente responsável pelo armazenamento dos dados dentro do Hadoop. Esse armazenamento é realizado através de blocos distribuídos em diversos servidores. Essa distribuição permite que a pesquisa pelos dados armazenados seja realizada de forma paralela, acelerando o processo (TAURION, 2013). Essa característica permite o armazenamento de uma grande quantidade de dados com alta performance e recuperação automática a falhas, tornando a ferramenta confiável. A forma de armazenamento de dados em diversos servidores torna a ferramenta escalável, aumentando os recursos de acordo com a necessidade (SOBREIRO, 2018).
O funcionamento do Hadoop é baseado em servidores e discos locais, em razão de considerar essa prática menos custosa. Isso implica, como já citado, em um tempo curto de recuperação em casos de falhas, porque cada bloco é copiado em mais dois servidores, assim, em caso de falha de um ou dois servidores, o terceiro servidor é capaz de suprir as demandas de pesquisas realizadas (TAURION, 2013).
O Hadoop foi projetado para manipular uma massa de dados grande, assim como um bloco com tamanho grande pode trabalhar com um número razoável de dados processados simultaneamente.
Para realizar o mapeamento dos dados, o Hadoop utiliza um servidor chamado NameNode. O mapeamento realizado é armazenado na memória e existe apenas um NameNode, que deve ter alta disponibilidade e um processo de backup eficiente. Por haver apenas um ponto de falha, essa situação deixa o sistema vulnerável.
A distribuição de seus componentes torna o Hadoop uma ferramenta que permite ao Big Data processar grandes massas de dados de forma rápida. O Hadoop é a ferramenta mais utilizada para Big Data visto que os dados são tratados em tempo real em diversos servidores, garantido um processamento mais eficiente e gerando economia de dinheiro e tempo (WHITE, 2015).
Um exemplo de melhoria pode ser observado no caso da Caesars Entertainment, uma empresa de cassinos americana. Essa empresa implantou um novo sistema Hadoop para análise de dados com o intuito de auxiliar nas atividades de criação de campanhas específicas de marketing, alcançando os numerosos tipos de clientes. Com a utilização do novo sistema, a empresa estima uma redução no tempo de processamento de 6 horas para 45 minutos, além de visualizar resultados mais precisos nas sugestões de experiências para os usuários e uma maior segurança em suas transações financeiras. Segundo informações da empresa, após a mudança no sistema de análise de dados, o número de registros processados chegou a ultrapassar o valor de 3 milhões por hora.
Leia mais em: https://cio.com.br/sete-casos-de-uso-do-hadoop-em-aplicacoes-de-big-data/. Acesso em: 14 jan. 2020.
Big Data pode ser definido como um grande volume de dados que trafega pela internet. Devido ao avanço da tecnologia, os serviços geram cada vez mais dados. As análises desses dados produzem informações de forma instantânea, ajudando na tomada de decisão em tempo real. O Big Data apresenta alguns aspectos que comumente chamamos de 5 Vs: volume, velocidade, variedade, veracidade e valor. Considerando essas características do Big Data, assinale a alternativa correta.
A variedade está relacionada com a quantidade extensa de dados armazenada e analisada.
Incorreta. A variedade está relacionada com dados advindos de vários tipos de mídias.
O volume está relacionado com a importância dos dados para a empresa.
Incorreta. O volume está relacionado com a quantidade extensa de dados analisada.
A veracidade está relacionada com a alta transmissão de dados recebidos e transmitidos.
Incorreta. A veracidade está relacionada com a confiabilidade dos dados.
O valor está relacionado com a importância dos dados para empresa.
Correta. O valor de um dado está relacionado com a importância desse dado para as regras de negócio da empresa.
A velocidade está relacionada com a confiabilidade dos dados coletados.
Incorreta. A velocidade está relacionada com a alta transmissão de dados recebidos e transmitidos.
Para realizar o processamento da grande quantidade de dados, bem como para trabalhar com objetivos específicos, algumas tecnologias envolvidas serão apresentadas neste item. Iremos observar o tipo de banco de dados criado para armazenar os diversos tipos de dados gerados na Web 2.0 e também as ferramentas aplicadas nas análises de dados que auxiliam nas tomadas de decisões. Por fim, apresentaremos as novas formas de trabalhar o armazenamento de dados, que podem ser consideradas uma tendência para as ferramentas de Big Data.
Com o aumento da quantidade de massas de dados geradas no advento da Web 2.0, foi necessário modificar a forma de armazenamento. Os bancos de dados existentes, manipulados de forma relacional, não comportavam mais esses tipos de dados, que passaram a ser modelados de diversas formas (MATOS, 2019). Esses bancos de dados relacionais modelavam os dados de forma que eles chegavam aos usuários no formato de tabelas e estabeleciam uma relação. Geralmente utilizavam o conceito de entidades, registro e colunas, além de representação por chaves (DIANA; GEROSA, 2010). Nesse contexto surgiram os bancos de dados não relacionais.
Banco de dados não relacionais, ou banco de dados NoSQL (do inglês, Not Only SQL), foram criados para solucionar a nova forma de armazenamento de dados provenientes da Web 2.0 e também para propor os novos paradigmas de armazenamento de dados em massa como o Big Data. Esse tipo de banco é distribuído e não relacional, ou seja, permite receber dados que não estão estruturados e precisam passar por um processo de tratamento para utilização nas ferramentas que tem a finalidade analisá-los (MATOS, 2019). Possuem também uma arquitetura que permite a escalabilidade. Como já vimos, a escalabilidade é uma característica importante nos conceitos relacionados ao Big Data, visto que não é possível medir a quantidade de dados que pode ser armazenada (TAURION, 2013).
Diana e Gerosa (2010) descrevem de forma detalhada os itens que levaram ao surgimento das tecnologias para o armazenamento e o processamento desse tipo de dado:
Desta sorte, podemos afirmar que as tecnologias dos bancos de dados não relacionais cresceram e que algumas ferramentas que se baseiam nesse paradigma foram desenvolvidas para atender as demandas de mercado. Um levantamento realizado em 2018 pelo pesquisador Matos (2019) apresenta as ferramentas mais utilizadas:
Business Intelligence (BI) é um sistema de apoio à decisão integrado a outros sistemas de uma empresa, como um Data Warehouse. O seu objetivo é produzir uma análise dos dados e das operações de uma empresa de forma interativa e relacionar essas atividades com outras fontes de informação (FAWCETT; PROVOST, 2016). De forma simplificada, pode ser entendido como uma análise de dados de bases combinadas diferentes (SOBREIRO, 2018).
O BI atua convertendo dados brutos em visão de novos negócios, auxiliando gestores em processos de tomada de decisão. Atua a partir de elementos como dashboards, visualizações de informações e relatórios, que são modelados a partir de conjuntos de dados estruturados (MATOS, 2015).
Uma ferramenta de BI combina, basicamente, dados internos coletados de diversas formas (organizações, colaboradores, outros sistemas e stakeholders em geral) com ferramentas para transformação e análise dos dados coletados como:
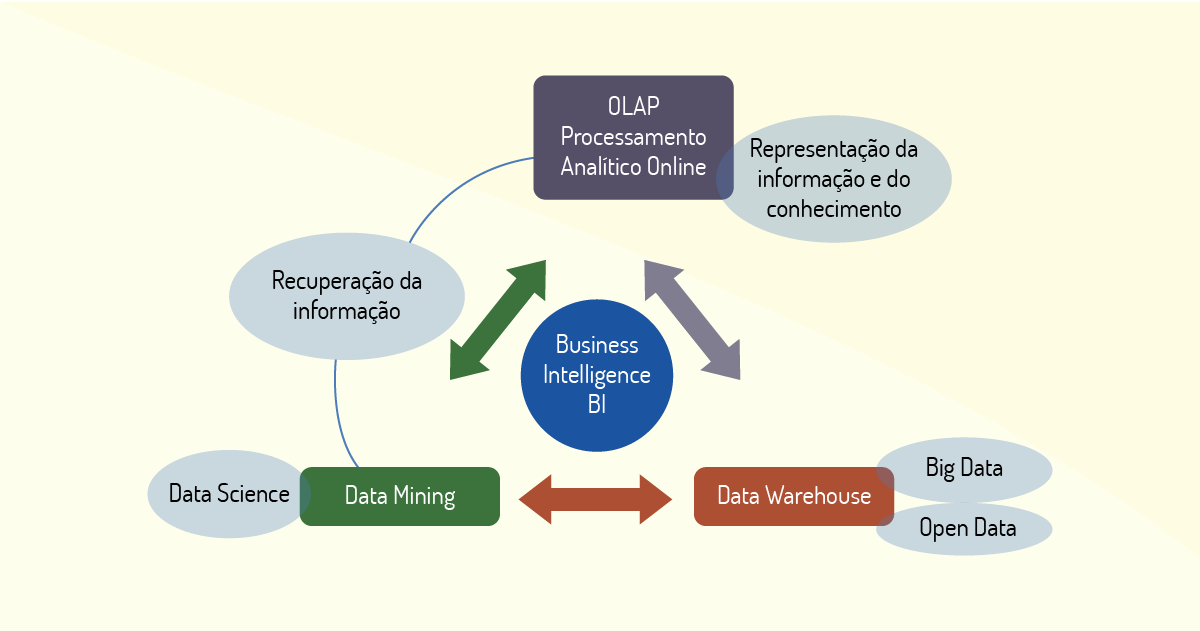
Uma ferramenta de BI também auxilia na verificação da qualidade de processos operacionais relacionados à estratégia da empresa por meio de indicadores de desempenho. Mediante recursos de análise e ferramentas de interatividade (como dashboards), permite a análise dos dados, em tempo real, admitindo a realização da tarefa de forma eficiente e prática (CALDAS; SILVA, 2016).
Existem diversas ferramentas de análises de dados e armazenamento em massa que podem ser compreendidas como componentes de um BI. Veremos alguns exemplos a seguir.
Data Warehouse (DW) é um sistema de análise de dados utilizado por empresas de diversos seguimentos para auxiliar no processo de tomada de decisão. Com a grande massa de dados gerados atualmente, por diversos contextos, como já vimos, se faz necessário uma tecnologia que permita a realização das análises de forma eficiente e que possibilite, por meio do processamento realizado, gerar tomadas de decisões que auxiliem no crescimento dessas empresas (TAURION, 2013).
Uma ferramenta de DW possui duas atividades que podem ser descritas como a inserção e a consulta dos dados, através dos elementos que os constituem. O processo é realizado mediante a transformação dos dados em informações (como visto anteriormente, as informações são significados extraídos dos dados). É esse processo que dá suporte às atividades dos gestores, pois cria um ambiente confiável para tomadas de decisões (CALDAS; SILVA, 2016).
O trabalho de uma ferramenta de DW é bem eficiente, visto que ao reunir informações de diversas fontes (bancos de dados), as análises tornam-se mais eficientes. Desta maneira, aproveita-se ao máximo as informações geradas, permitindo que nenhum dado fique inacessível ou não seja utilizado (TAURION, 2013).
Os autores Bispo e Cazarini (1998) descrevem os componentes de um Data Warehouse:
Os autores ainda descrevem como um DW utiliza essas ferramentas em um processo de análise de dados, da coleta até a construção de relatórios. Após a busca nas bases de dados operacionais, os dados são formatados para o modelo do DW. Os dados podem ser formatados de diversas maneiras: correções, fusões, desmembramentos, atividades que visam auxiliar em pesquisas futuras. Ainda no processo de extração, os metadados (informações sobre a origem e as alterações) são armazenados para dar consistência aos dados. Em seguida, a replicação dos dados é feita. Esse processo dá agilidade às análises, pois acelera os resultados das consultas realizadas.
As ferramentas voltadas para a construção dos relatórios consultam os dados presentes no DW (após todo processo inicial) e elaboram os relatórios em inúmeras formas de visualização e em vários níveis de complexidade. Por exemplo: essas informações podem ser apresentadas de forma sintética (condensando informações), ou analítica (ampliando o campo de visão sobre os dados), ou em outras formas de visualização, como os gráficos. Após a construção dos relatórios, através das ferramentas visuais (OLAP), é possível realizar a análise por meio de comparações (número de vendas de dois produtos), projeções (o que aconteceria com as vendas se juros fossem alterados), informações históricas (dentro de um determinado período qual produto vendeu mais). Essa ferramenta permite a melhor padronização para realização dessas atividades. A Figura 1.6, apresenta um esquema de um DW, representando as etapas e as ferramentas descritas anteriormente.
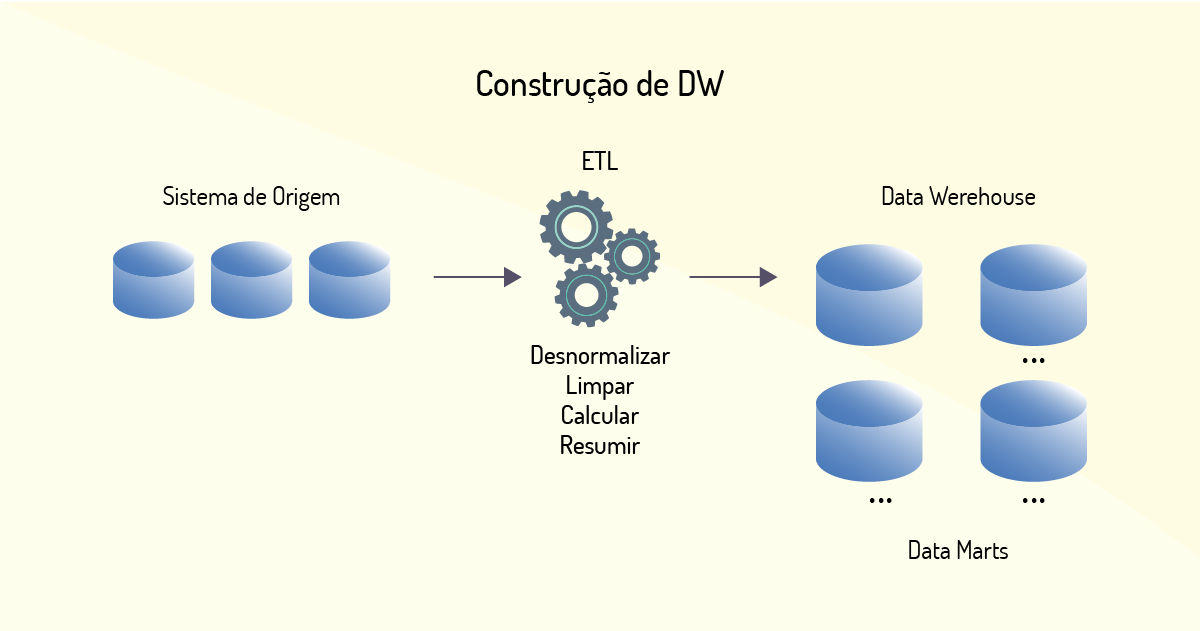
Os dados gerados partir do processo do DW podem servir de suporte para outras ferramentas de Big Data, como veremos a seguir.
Data Mart (DM) pode ser visto como subconjuntos do DW, mas separado por assuntos específicos, por exemplo, os departamentos de uma empresa - neles teríamos os DM do setor comercial, do administrativo, do financeiro. Cada um representando um DM específico e todos como parte de um DW maior (ELIAS, 2014).
Apesar das semelhanças entre o DM e o DW, que podem causar uma certa confusão acerca das definições, devemos ressaltar que existem algumas diferenças. Na parte estrutural, por exemplo, a modelagem de um DM é dimensional (ideal para bancos que se relacionam com um DW). As informações podem se relacionar como um cubo: podendo aprofundar os detalhes de cada dimensão (eixo) ao se visualizar o cubo em fatias, extraindo mais detalhes do que ocorre dentro de cada parte da organização (CALDAS; SILVA, 2016).
Como já vimos, um DW pode receber dados de diversos DM. Depois dessa etapa, o processo inverso passa ser realizado, ou seja, um DW passa a alimentar os DM individualmente. A partir de então, temos duas maneiras de criar um DM, pelas abordagens Top-down e Bottom-up (CALDAS; SILVA, 2016).
A abordagem Top-Down se apresenta a partir da criação de um DM pela subdivisão de um DW em pequenas áreas, ou bancos de dados menores, representando determinados assuntos (por exemplo, os departamentos da empresa) (ELIAS, 2014).
A abordagem Bottom-up surge a partir da junção de bancos ou DM menores, essas junções resultam na criação de um DW, visando atender alguma estratégia empresarial, é o modo inverso da abordagem Top-down (CALDAS; SILVA, 2016). A Figura 1.7 apresenta um esquema que representa a criação usando as duas abordagens. Sobre as abordagens, Elias (2014) explica que a abordagem Top-down possui uma visão mais abrangente, uma vez que parte do nível mais geral (alto) e vai para o mais detalhado (baixo).
O modelo Top-down pode ser complexo, pois essa abordagem necessita ter uma visão maior de toda a solução (DW) e será a partir dela que os DM serão construídos. Todo o contexto precisa ser bem definido e compreendido, assim, a implementação não corre riscos de não atingir seus objetivos (CALDAS; SILVA, 2016).
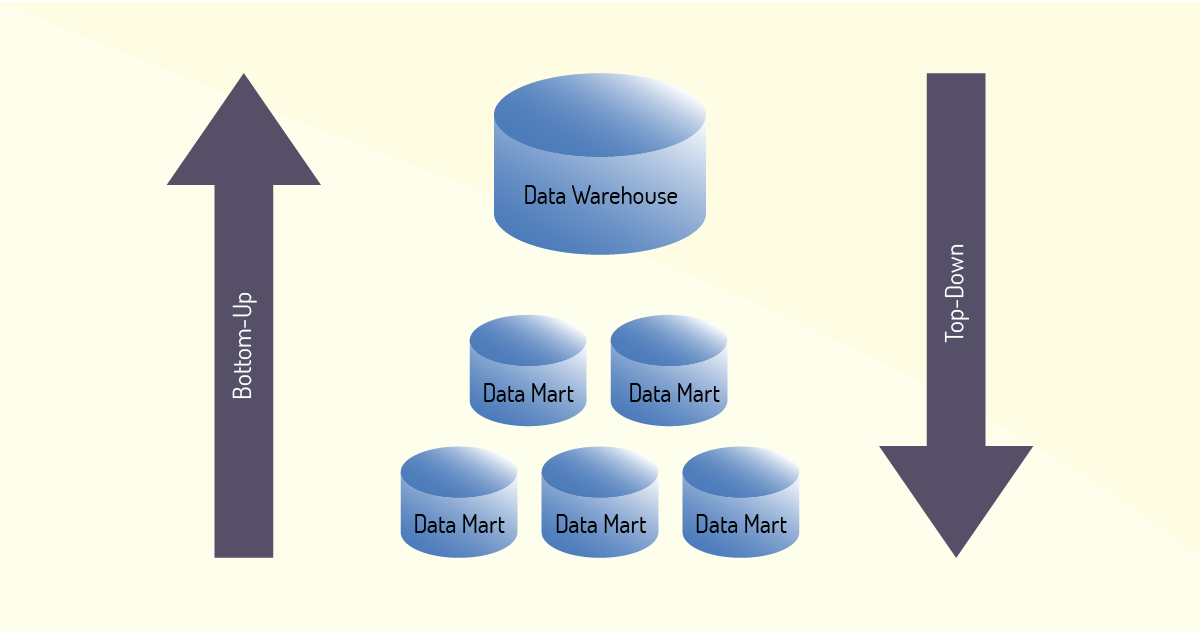
Já a abordagem Bottom-up se baseia no conceito de dividir para conquistar, bem difundido na área de Tecnologia da Informação. Nessa concepção o problema maior é dividido, gerando problemas menores. O objetivo é criar uma solução final a partir das soluções das etapas menores. Inicialmente são implementados os DM menores para, posteriormente, construir o DW (maior). Essa abordagem apresenta menos riscos de falhas, já que aponta uma forma de evolução desenvolvida (do menor para o maior) (ELIAS, 2014).
A principal vantagem para o uso de DM é a velocidade na realização das transações, como já vimos, essa é uma das necessidades de quem utiliza esse tipo de ferramenta. Essa característica permite a participação efetiva do usuário final. Imagine que uma grande empresa que comporta alguns departamentos construa uma estrutura para análise de dados que coleta de seus usuários e que faz essa investigação de forma segmentada. A abordagem Top-Down pode ser implementada neste caso, uma vez que os dados podem ser todos concentrados em um grande DW e, a partir dele, vários DM podem ser criados visando ao armazenamento dos dados para os respectivos departamentos (comercial, financeiro, marketing) e cada DM vai armazenar os dados pertinentes aos seus interesses para análises mais detalhadas.
Data Mining (DN), ou mineração de dados, é um processo de análise de dados em grandes quantidades, normalmente relacionado às áreas de negócio ou às áreas das ciências (TAURION, 2013). A partir da busca de padrões que sejam consistentes ou sistemáticos, realiza um processo de validação para, em seguida, aplicar esses padrões nos conjuntos de dados encontrados (CALDAS; SILVA, 2016).
Com a grande massa de dados existentes (e aumentado cada vez mais) e a demanda de informações relevantes para as diversas áreas de aplicação a partir desses dados, o DN vem sendo tratado como descoberta de conhecimento (mineração) em bases de dados (GALDINO, 2016).
Para transformar essa mineração em conhecimento foi criado um processo denominado de Descoberta de Conhecimento em Bancos de Dados (Knowledge Discovery in Databases – KDD). Em outras palavras, o KDD é um processo que, a partir da mineração de dados, tem por finalidade a descoberta de conhecimento (MOURA, 2018).
O KDD possui várias etapas que visam criar padrões para a utilização na análise de dados. Esses padrões devem ser relevantes e de fácil compreensão, por isso esse processo pode ser considerado complexo (CALDAS; SILVA, 2016). A Figura 1.8, apresenta as etapas envolvidas no KDD.

O processo KDD prevê atividades realizadas em sequência e com resultados relacionados entre as etapas, criando uma dependência entre as etapas. Moura (2018) descreve o que é realizado em cada uma dessas etapas do processo.
Após a definição do problema, dos dados utilizados e das ferramentas de análise, a pesquisa é feita pelo DN de forma automática, dentro da massa de dados, buscando por anomalias e relações, deparando-se com problemas não identificados pelos usuários.
Esse tipo de análise pode ser utilizado para extrair informações que a priori não apresentavam uma relação visível. Por exemplo: relações de compras de produtos distintos baseando-se na faixa etária ou sexo do cliente. Os resultados desse tipo de análise podem ser utilizados para realizar sugestões de compras de novos produtos para um público específico.
Para explorar massas de dados e permitir novas descobertas dentro de um DN é possível utilizar estatística, inteligência artificial, reconhecimento de padrões, algoritmos para aprendizagem e classificação baseada em redes neurais. Nas próximas unidades deste livro, vamos aprofundar os nossos conhecimentos sobre como funciona a Inteligência Artificial (IA) e a Machine Learning (ou Aprendizagem de Máquina).
Um Data Lake pode ser descrito como um repositório que armazena uma abundante e diversificada massa de dados, estruturados ou não. É um importante elemento no universo Big Data (TAURION, 2013). O paradigma do Data Lake baseia-se na ideia de apenas um repositório de dados para todo o ambiente corporativo. Nele são armazenados todos os dados brutos da empresa, ficando disponíveis para quem precisar realizar uma análise sobre esses dados (MATOS, 2015).
Não obstante seja um conceito recente, o Data Lake surge como uma evolução nas tecnologias de armazenamento de dados em massa. Visto como fundamental, ele tem como objetivo atuar como ferramenta complementar para os demais repositórios existentes nas empresas, pois utiliza tipos de dados variados e integra tecnologias como o Hadoop (a principal tecnologia que oferece suporte ao Big Data) (PIRES, 2017).
Segundo Matos (2015), os Data Lake são construídos para funcionar de forma que outros repositórios possam consumir seus dados sem a necessidade de uma preparação prévia. Qualquer esquema que precise ser feito pode ser implementado a partir do momento que os dados estiverem passando por análises. Na Figura 1.9, podemos observar como o referido autor apresenta um esquema de comparação entre as formas de consumo de dados de um DW e de um Data Lake:
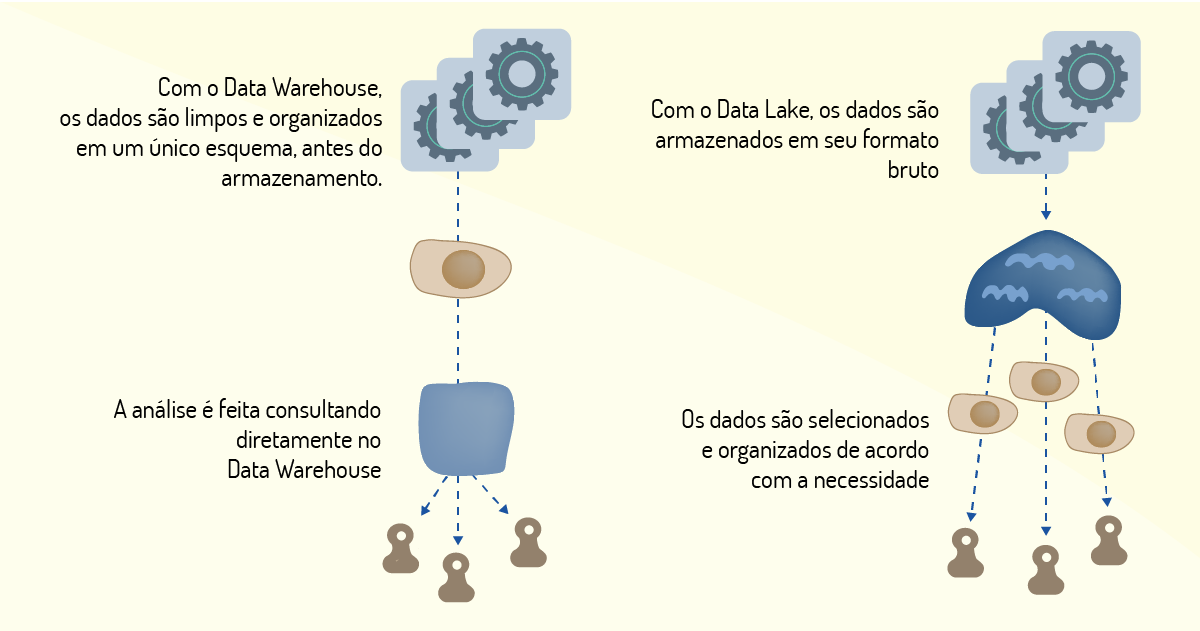
Pires (2017) lista as principais características de um Data Lake:
A vantagem do uso dos Data Lake está no fato deles auxiliarem nas reanálises a partir de novas investigações sobre dados existentes. O Data Lake não visa substituir ferramentas de análises existentes, mas complementá-las. O processo seria otimizado, visto que os dados poderiam ser importados para um repositório com objetivos específicos e, assim, serem analisados de forma isolada (MATOS, 2015).
Atualmente, as empresas utilizam Data Lake como ferramenta complementar aos processos existentes para gerir e analisar dados em massa. A partir de novas análises, os dados existentes podem criar um novo significado. Por ser capaz de receber todos os tipos de dados, torna-se flexível e escalável (características importantes para ferramentas de Big Data), permitindo bom custo benefício em relação às demais ferramentas existentes (PIRES, 2017).
O termo Cloud Computing, ou Computação em Nuvem, faz referência ao armazenamento de dados em uma grande estrutura de servidores que podem ser virtuais ou físicos (TAURION, 2013). É um ambiente computacional que permite o compartilhamento de recursos e uma alta capacidade de armazenamento, admitindo que outros serviços possam ser disponibilizados através de sua estrutura (GALDINO, 2016). Dentre as suas principais características estão a possibilidade de solicitar recursos de forma antecipada (sob demanda), elasticidade no uso de seus recursos e a disponibilidade de recursos de forma expansível, a depender da necessidade do usuário.
A Computação em Nuvem funciona através de data centers que disponibilizam recursos de hardware para que empresas possam armazenar e processar dados associados aos seus negócios (TAURION, 2013). Essa forma de trabalho é conhecida como software as service (software como serviço) e que permite que uma empresa ou usuário pague para utilizar recursos computacionais de outra empresa, via internet.
Existem alguns modelos de implantação de serviços em nuvens, são eles:
Em ambientes distribuídos, a Computação em Nuvem pode agregar valor ao processo de análise de dados em massa se for utilizada como alternativa para sistemas de distribuição com armazenamento local. Esses ambientes oferecem mais flexibilidade aos sistemas de armazenamento. Além disso, lembramos que a elasticidade é uma característica importante para sistemas que não podem definir a quantidade de dados que irão armazenar. O crescimento e a popularização dos serviços de Nuvem fizeram com que o custo ficasse bem mais acessível, permitindo que empresas de menor porte pudessem investir neste tipo de solução (GALDINO, 2016).
Empresas que já dispõem de serviços que utilizam recurso de ambiente em nuvem podem desenvolver aplicações para utilizar essa infraestrutura existente sem demandar muito custo adicional. Pequenas empresas que ainda não possuem grandes cifras para investimento em infraestrutura podem adquirir pequenos pacotes de serviços, aumentá-los, caso necessário, e, em seguida, reduzir sua utilização, baixando novamente os custos (TAURION, 2013).
Alguns autores descrevem as vantagens de utilizar ambientes em nuvem para realizar análise de dados. Caldas e Silva (2016) relatam que em um sistema distribuído híbrido, composto por serviços privados e usado para implantar sistemas de análise de dados pode ser mais econômico que manter uma estrutura física em um centro de tecnologia de grande ou médio porte. Esse sistema pode ser ampliado com o uso sob demanda de nuvens públicas para armazenamento ou projetos de curta duração.
Outra aplicação relatada pelos autores seria a divisão de fontes (internas e externas). Algumas empresas preferem manter seus dados sob sigilo, por questões de privacidade. Porém, para reduzir custos e manter um sistema desse porte, serviços de nuvens (públicas ou privadas) podem ser contratados para a realização das análises dos dados.
Galdino (2016) alerta que além dos altos custos gerados para implantar e realizar a manutenção em sistemas distribuídos de grande porte (mainframes), em alguns casos, a sua capacidade não é totalmente explorada, gerando desperdício de recursos. Os sistemas em nuvem possuem características que podem ser úteis para sistemas de Big Data, como configurações por demanda de usuários (número de acessos, por exemplo). Essas configurações podem ser variar de acordo com situações específicas ou necessidade de um desempenho maior devido a processamento de uma massa de dados em quantidade além do normal. Datas comemorativas ou épocas de vendas elevadas causadas por períodos de grandes descontos, como Black Friday, podem gerar situações em que o número de cadastros, visitas a sites de lojas e liberação de promoções precisem ser processados em quantidade e velocidade diferentes ao do fluxo normal.
Outra forma de utilização indireta para Big Data é contratar empresas que realizam o trabalho de processar dados sob demanda utilizando nuvens, conhecidas como Serviços de Análise (ou Analysis as a Service, AaaS). As organizações que dispõem desse tipo de serviço utilizam sistemas híbridos de nuvem pública e privada para manter os riscos sob controle e, quando for demandado, aumentar a capacidade de processamento e armazenamento dos sistemas. Na próxima seção, vamos conhecer alguns sistemas que utilizam essas estruturas tecnológicas para realizar armazenamento e análise de dados de forma massiva.
Com o aumento da quantidade de massas de dados geradas no advento da Web 2.0 foi necessário modificar a forma de armazenamento. Os bancos de dados existentes não comportavam mais esses tipos de dados que passaram a ser modelados de diversas formas (MATOS, 2019). Considerando esse contexto, assinale a alternativa que contém a modelagem de dados utilizada em ferramentas de Big Data.
SQL (Structured Query Language).
Incorreta. O SQL é uma modelagem para banco de dados relacional, Big Data utiliza modelagem de dados não relacional.
NoSQL (Not Only SQL).
Correta. NoSQL é uma tecnologia para modelagens de dados não relacionais. Como o Big Data armazena diversos tipos de dados, essa modelagem é adequada às ferramentas de armazenamento em massa.
ETL (Extract, Transforming and Loading).
Incorreta. ETL refere-se à ferramenta utilizada para combinar dados de diversas fontes, essencial na criação de ferramentas de Big Data.
OLAP (On-line Analytical Process).
Incorreta. OLAP é capacidade para manipular e analisar um grande volume de dados sob múltiplas perspectivas.
KDD (Knowledge Discovery in Databases).
Incorreta. É um processo que tem por finalidade a descoberta de conhecimento a partir da mineração de dados.
As aplicações para as ferramentas de Big Data ocorrem em diversas áreas de atuação e visam auxiliar os processos organizacionais que dão suporte às tomadas de decisões. Essas aplicações podem, ainda, criar novas atividades: como realizar previsões sobre tendências no mercado (SOBREIRO, 2018). De acordo com Taurion (2013), algumas aplicações práticas com as soluções de Big Data são:
Vale ressaltar que o Big Data obteve maior espaço nesses últimos anos com o advento da IoT. Por meio de vários dispositivos e/ou objetos conectados à internet produz uma massa de dados que reúne padrões sobre o uso de determinado produto pelo cliente, bem como o desempenho que esse produto ofereceu ao usuário (TAURION, 2013).
Galdino (2016), por sua vez, apresenta outras áreas de aplicação para ferramentas de Big Data:
Moura (2018) apresenta alguns casos relacionados à construção de soluções utilizando ferramentas de Big Data. As soluções atendem às mais variadas necessidades e empregam múltiplos recursos, como veremos a seguir. Os casos apresentados pela autora são resultados de entrevistas realizadas com profissionais responsáveis por criar soluções que tinham como suporte as tecnologias para Big Data.
O caso relatado por Moura (2018, p. 42) apresenta o desenvolvimento de uma ferramenta para análise de dados (relatórios) por meio do uso de algoritmos e utilizando como suporte a linguagem de programação R. A empresa solicitante trabalha com a produção de modelos para análise de dados que atendam às necessidades de seus clientes, dentre as quais se apresentam: controles de estoque, identificação de anomalias, previsão de vendas, identificação do perfil do consumidor.
A Figura 1.10 apresenta as etapas da solução desenvolvida no caso 1. Depois de uma entrevista inicial, em que foi possível identificar as necessidades do cliente, foi feita uma modelagem para acesso aos dados. Para tanto, foi necessário ter acesso à base de dados completa do cliente e, por fim, criar uma modelagem para implementação da solução.
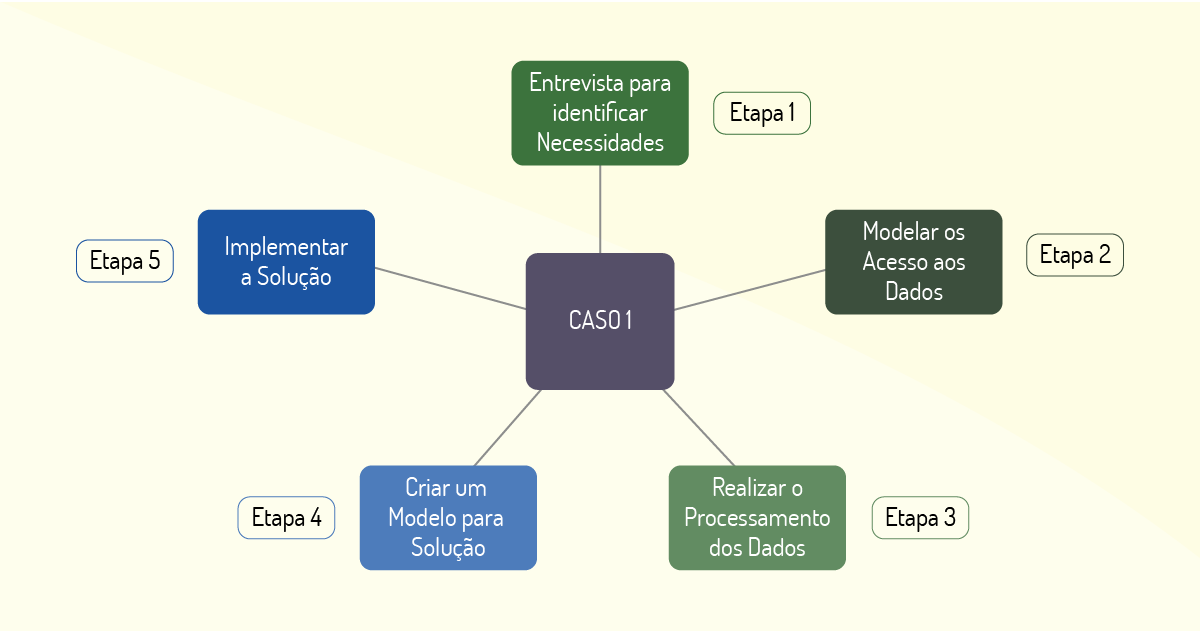
A solução usa modelos matemáticos e estatísticos, sempre verificando qual a melhor estratégia que será empregada (modelos determinísticos ou probabilísticos). Também foram aplicados algoritmos de machine learning para realizar descobertas utilizando as bases de dados existentes e já remodeladas. Após a implementação, uma validação é feita para a verificação por parte dos clientes. Nela analisam-se cenários já conhecidos antes da solução e outros que surgiram durante o processo. Segundo a autora, o profissional responsável afirmou em seu relato que a maior dificuldade encontrada foi a modelagem da solução, uma vez que o modelo desenvolvido deveria atender à grande quantidade de dados e com objetivos distintos.
O Caso 2 debatido por Moura (2018, p. 45) apresenta um projeto cujo objetivo era o de transformar a cultura de uma empresa em uma cultura de data driven (cultura orientada pela análise de dados). Ou seja, as decisões e modelagens de novos processos precisariam ser orientadas pela análise dos dados coletados pela empresa. Para realizar tal mudança foi proposta uma solução com a participação ativa dos membros da empresa. O resultado não apresentou apenas a utilização de uma ferramenta, mas sim uma mudança de cultura de trabalho, o que demandou um tempo maior de execução.
A solução se inicia com a realização de uma hackhaton (eventos de curta duração para construção de soluções de problemas específicos, utilizando programação): os profissionais da empresa e os clientes formaram times para criar projetos de análise de dados. Durante o evento, os times exploraram diversas formas de tomada de decisão. Outros pontos também são analisados: as fontes de onde as informações são coletadas e as formas de armazenamento dessas informações. Essa etapa auxiliou na escolha da modelagem dos dados coletados. A Figura 1.11 apresenta o esquema da solução realizada.

Depois da hackaton, foi realizada uma análise dos dados coletados em uma modelagem para que os dados pudessem ser apresentados de forma passível de análise pelo cliente. Desta maneira, as análises de dados passam a ser efetuadas de forma constante, como uma atividade cotidiana da empresa. Em seguida, foram criados modelos de soluções que atendessem às necessidades da empresa. As modelagens foram validadas com os gestores de negócio do cliente, que indicaram as mudanças necessárias nas modelagens apresentadas. A implementação tinha como guia atender os pilares do novo projeto de Data Driven da empresa: negócio, ciência e tecnologia. Foram disponibilizados também: análises, relatórios, dashboards e treinamentos. Na composição da solução foram utilizadas as linguagens de programação R e Python, que dão suporte à implementação de ferramentas de machine learning (utilizada em soluções de Big Data) e a ferramenta Excel (para apresentação dos dados estatísticos).
O profissional entrevistado afirmou que o maior desafio foi o treinamento dos clientes para a cultura de analisar e processar dados, pois este tipo de atividade demandou expertises específicas que levaram um tempo para serem desenvolvidas, como a capacidade analítica dos indivíduos.
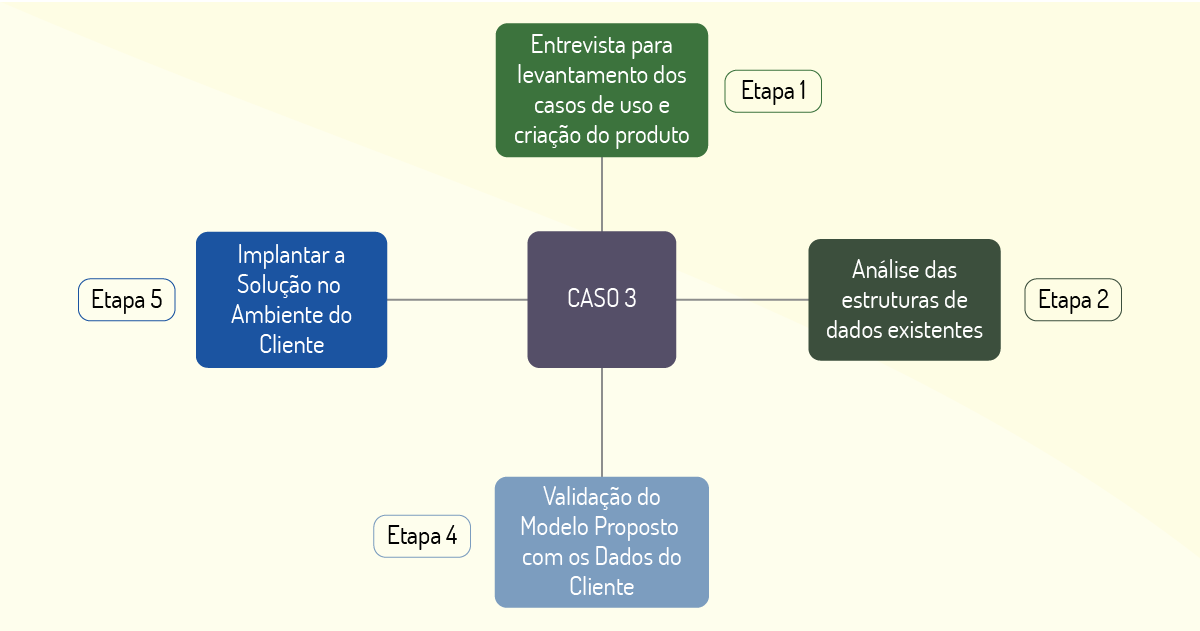
O caso 3, apresentado por Moura (2018, p. 46), trata de um projeto para construção de um software para análise de dados e tomada de decisão. O cliente utiliza os resultados das análises de dados para áreas de marketing; para pesquisar perfil e satisfação; para recursos humanos; para avaliação 360 e pesquisa de clima; para qualidade; para auditorias e análise de outliers; para inteligência, ouvidoria e SAQ (Safety Attitude Questionnaire, indicador de qualidade).
Inicialmente, após as reuniões de entendimento com o cliente, foram criados protótipos para que o cliente pudesse ter uma aproximação com o projeto que seria desenvolvido. Foram realizadas algumas reuniões para demonstrar as produções desses protótipos, para que tudo que estava sendo desenvolvido fosse validado e para apresentar diagramas de caso de uso (utilizados para auxiliar no entendimento do problema).
Terminada a etapa de definição da solução, foi analisada a forma como os dados do cliente estavam estruturados. Essa análise foi feita para verificar se os dados estavam no formato ideal para o novo produto que estava em desenvolvimento. Depois que se analisaram as estruturas utilizadas para o armazenamento da massa de dados, foi a vez dos dados serem de fato analisados para validar os modelos propostos na solução. Por fim, entregou-se a solução que foi proposta inicialmente. A Figura 1.12 apresenta as etapas do processo da composição da solução encontrada.
Como solução final, observamos um módulo de relatórios que tinha como objetivo auxiliar as análises de dados e as tomadas de decisão. Esse módulo foi adicionado ao software existente do cliente. Para a implementação da ferramenta foram empregadas as linguagens de programação PHP, Java, Python e R.
A maior dificuldade encontrada nos relatos dos especialistas envolvidos no projeto foi desenvolver a parte responsável por mostrar os resultados da análise de forma visual, usando gráficos e tabelas, pois elas precisariam ser rápidas e precisas.
De acordo com os estudos feitos por Moura (2018, p. 49), o caso 4 comporta a entrega de relatórios e dashboards baseados em análise de dados, além da realização de uma consultoria cultural que visava auxiliar o cliente nas previsões voltadas para análise de novos negócios, marketing e gerenciamento de crises. Inicialmente, em uma conversa com o cliente foi possível identificar os dados necessários para realização das atividades e o nível de maturidade da empresa nas atividades relacionadas a esse tipo de funcionamento.
Após a primeira etapa, foi feita uma análise dos dados utilizados pela empresa. Em seguida, houve uma preparação para que se adequassem as modelagens utilizadas nas soluções entregues. Posteriormente, foi realizado um mapeamento dos tipos de análise que poderiam compor a solução do problema encontrado. Finalmente, foi implementada uma solução para ser entregue à empresa, como mostra a Figura 1.13.
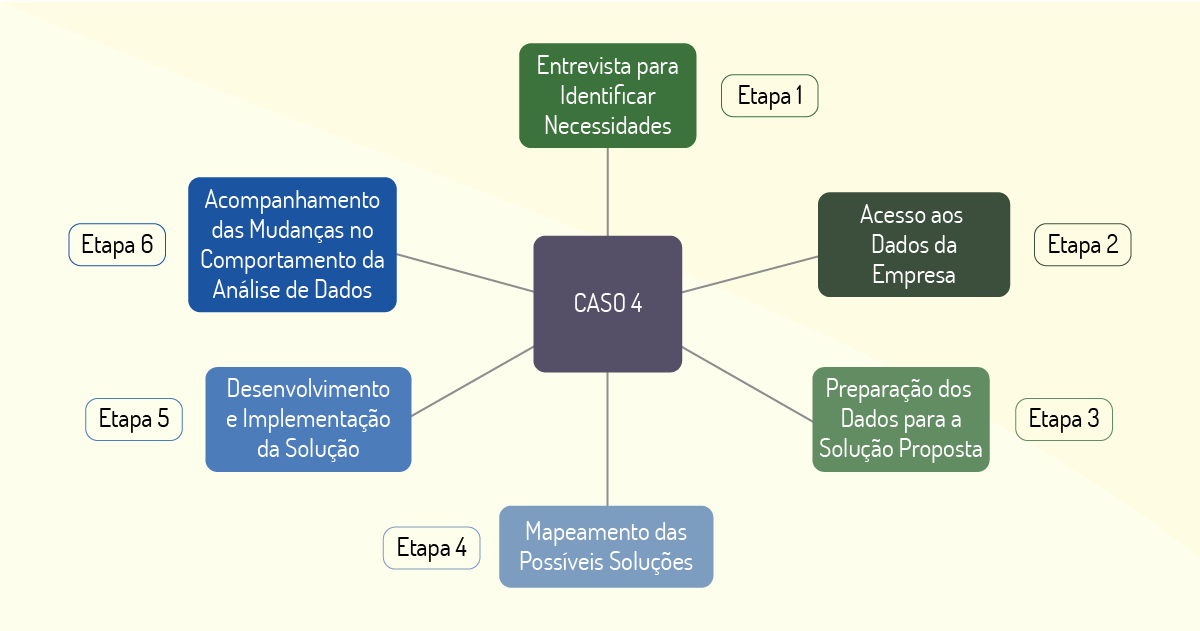
A solução entregue foi composta de relatórios, dashboards baseados nos dados analisados do cliente e de um relatório de consultoria que visava mudar a cultura da empresa. A empresa passou por uma etapa de acompanhamento para verificar as mudanças em relação às análises de dados praticadas pela empresa. Para a solução foram utilizadas as linguagens de programação R e Python e as ferramentas Qlick Sense (para os dashboards), Excel e SAS (Statistical Analysis System). As maiores dificuldades encontradas foram realizar a mudança de cultura, explicar os contextos relacionados às análises de dados e tomar decisões baseadas nesses princípios.
O caso 5, explorado por Moura (2018, p. 52), apresenta uma solução conjunta para uma empresa que utiliza análise de dados em massa para otimizar a distribuição de estoque, previsão e sugestão de vendas de novos produtos e análise de sentimento.
A primeira etapa realizada foi um diagnóstico feito durante as visitas ao cliente. Essa etapa visou responder a dois questionamentos iniciais: a) como estava organizada a base de dados; b) quais atividades (análises) eram realizadas com os dados existentes. Após essa etapa seria possível delinear possíveis soluções para os problemas encontrados. Um diagnóstico foi feito, e as validações das soluções foram apresentadas ao cliente.
Posteriormente, realizou-se uma atividade de acesso aos dados, explorando e fazendo uma análise histórica dos dados. Buscou-se, ainda, padronizar os dados para as próximas etapas: a modelagem, o desenvolvimento e a implantação da solução. A Figura 1.14 nos mostra esse processo:
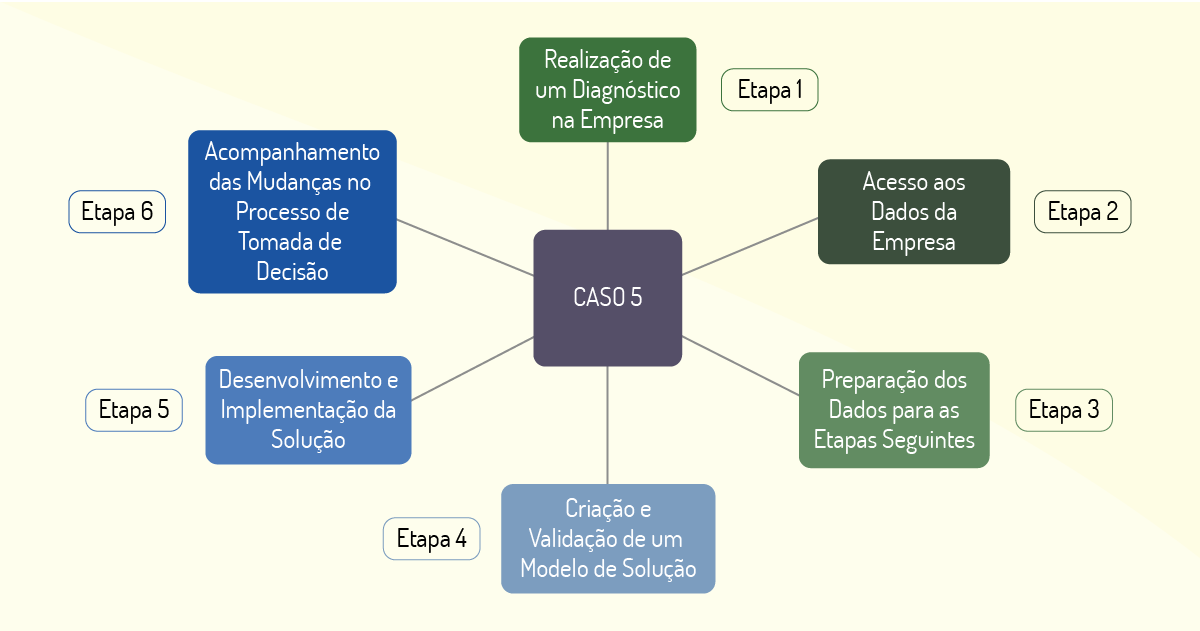
A solução apresentada, além de contemplar os relatórios, dashboards, softwares baseados nos algoritmos utilizados para análise dos dados, também ofereceu um treinamento para auxiliar a empresa a implementar o processo de data driven (cultura orientada a análise de dados). Após a implementação da solução, foi oferecido um acompanhamento para diluir as dúvidas encontradas em relação a adaptação dos processos referentes às novas políticas de análise de dados e tomada de decisão. Para o desenvolvimento das soluções foram utilizadas as linguagens de programação R e Python e as ferramentas Excel, Hadoop e Spark.
E com esses exemplos finalizamos o nosso estudo sobre Big Data. Nessa primeira unidade vimos as definições, as características, as ferramentas utilizadas e as diversas aplicações para esta área.
Segundo previsões, a internet das coisas (Internet of Things - IoT) será uma das maiores responsáveis pela geração dos dados processados em ferramentas de Big Data. Dentre as alternativas a seguir, assinale a que se refere a uma aplicação de IoT e que utiliza ferramentas de Big Data.
Envio de informações sobre batimentos cardíacos realizado em uma atividade física encaminhado por meio de uma smart band.
Correta. Esse tipo de atividade é realizada por meio de sensores que, conectados à internet, enviam as informações para uma ferramenta de análises de dados, aplicando os conceitos de IoT.
Recomendações de novas conexões de uma rede social, baseado no ciclo de amizade atual.
Incorreta. Esse tipo de atividade é realizado por sistemas que fazem o cruzamento de dados ou ferramentas de machine learning.
Descontos gerados para um cliente imediatamente após atingir um valor total de compras no mês.
Incorreta. Essa tarefa é realizada por ferramentas de BI que analisam dados de compra do cliente.
Recomendações de novos vídeos de um artista no Youtube, baseado em um vídeo assistido e utilizando ferramentas de machine learning.
Incorreta. Essas atividades são realizadas por meio de ferramentas de machine learning, analisando possíveis escolhas do usuário, não estão relacionadas com IoT.
Sugestão de compra de um produto, baseado em compras conjuntas realizadas por outros clientes.
Incorreta. Essas atividades são realizadas por ferramentas de análise de dados que relacionam compras feitas, criando uma relação entre os itens comprados, ou ferramentas de machine learning que analisam as escolhas de outros usuários.
Nome do Livro: Big Data: O futuro dos dados e aplicações
Autor: Felipe Nery Rodrigues Machado
Editora: Érica
ISBN: 9788536527000
Esse livro se propõe a apresentar os principais fundamentos de Big Data, seu histórico e sua utilização. Apresenta as diferenças entre as ferramentas que utilizam Big Data. Mostra, ainda, as tecnologias empregadas e as aplicações reais dessas ferramentas e tecnologias.
