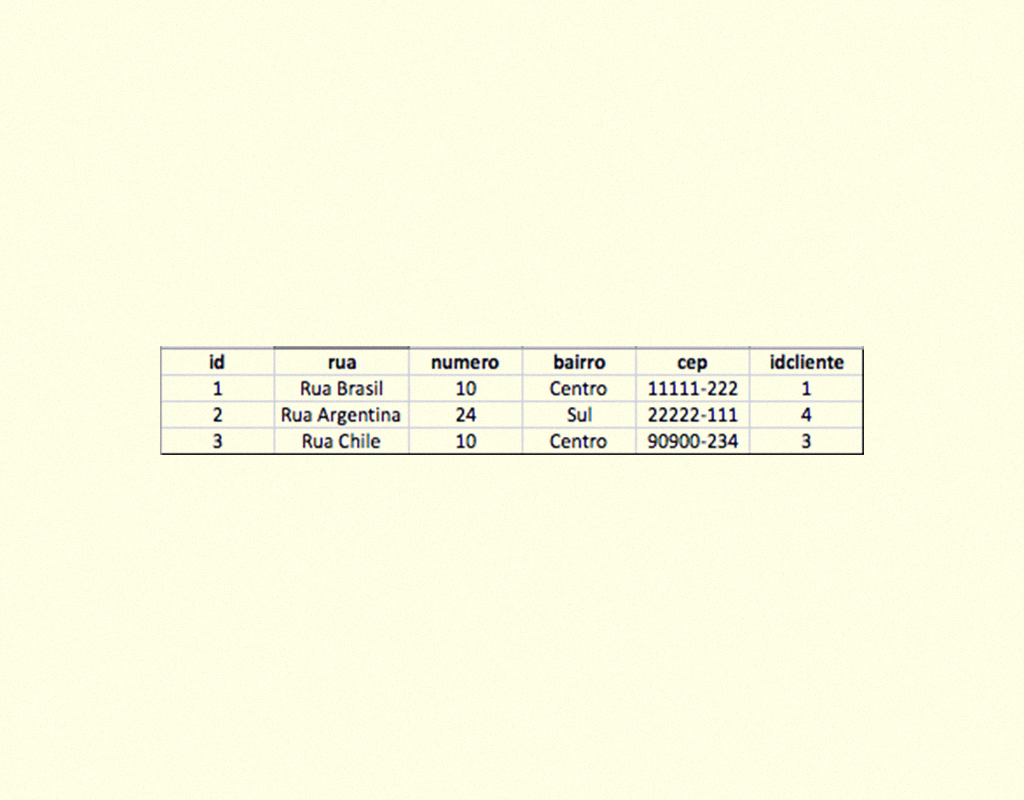
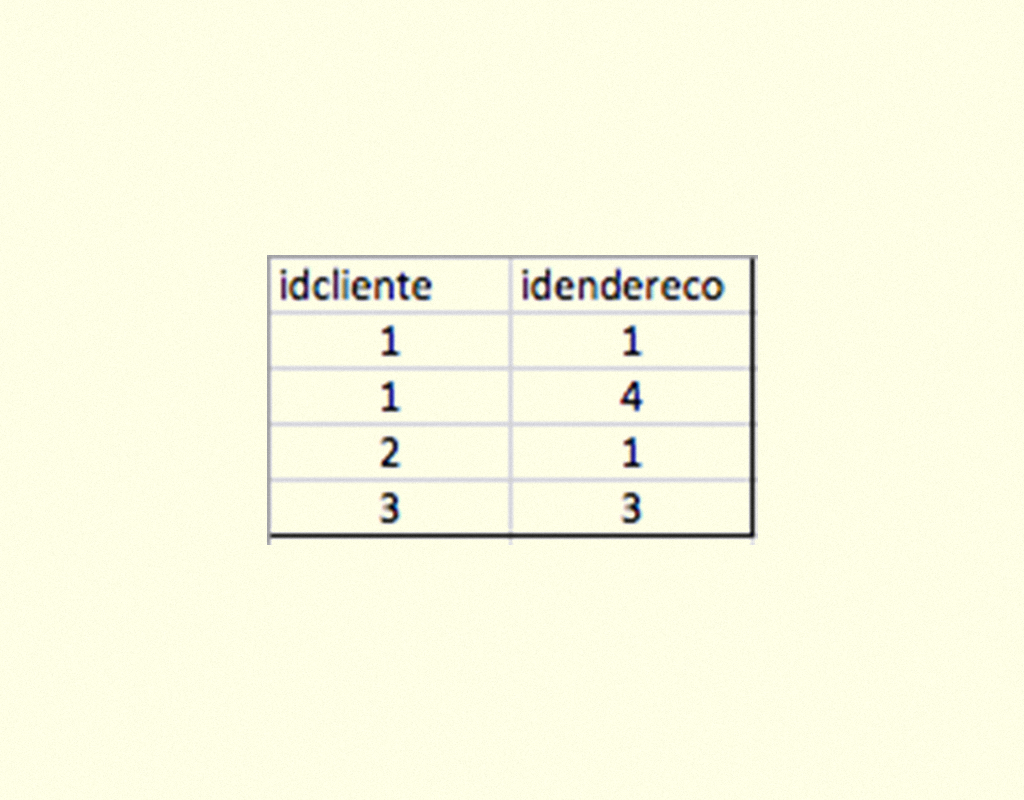
Pacotes, classes, métodos e suas propriedades
Os objetos são escritos por meio de classes, que descrevem a estrutura, projetando o objeto com seus atributos e métodos (BATES, 2005). Os métodos especificam o comportamento desse objeto, como ele se relacionará com outros objetos, e os atributos especificam as características do objeto.
Nesta seção, veremos como uma classe é estruturada dentro de pacotes, com seu(s) construtor(es), métodos e métodos acessores.
Pacotes
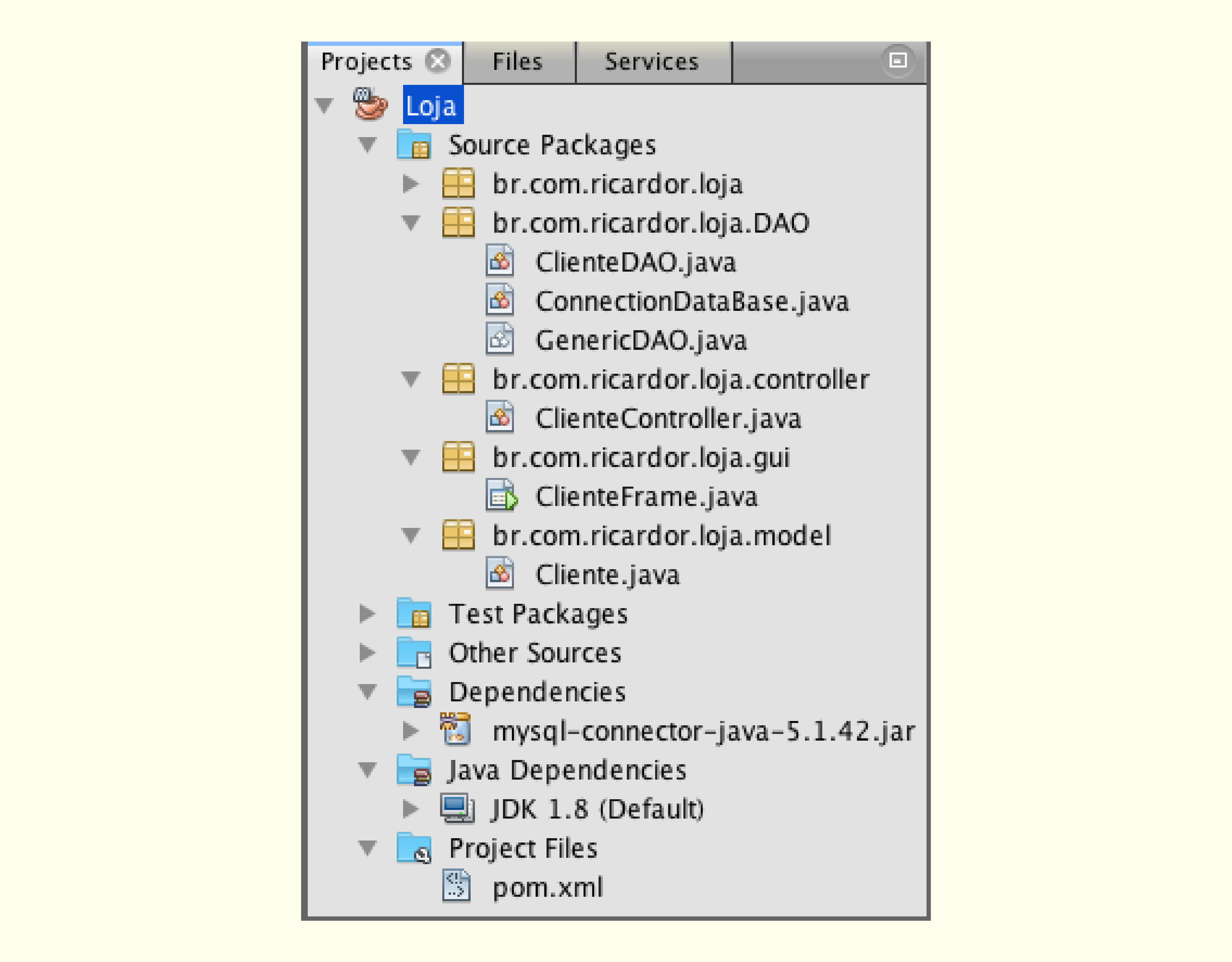
Como citado na seção 2.2 da Unidade I, toda classe Java faz parte de um pacote. O objetivo principal de um pacote é manter o código organizado, separando as classes por pacotes com alguma característica em comum. O pacote também pode especificar qual entidade é a “dona” do código mediante a nomenclatura reversa do domínio.
A utilização do domínio completo para nomear um pacote deve-se ao fato de um domínio ser único, ou seja, ele só pode ter um único dono e o nome do domínio não pode ser repetido em outro domínio, isto é, o domínio abc.com.br será único e diferente do domínio abc.com. O uso do domínio completo garante que não haverá outros nomes coincidindo com os nomes do seu projeto. Por outro lado, se a utilização fosse somente o nome simples do domínio (somente abc) e a ABC dos Estados Unidos utilizasse ABC nos seus projetos, os nomes iriam coincidir, podendo causar problemas, por isso é convencionado o nome do domínio reverso (br.com.abc) para o prefixo dos nomes dos pacotes.
Outro objetivo do pacote é evitar colisões de nomes de classes diferentes, ou seja, supõe-se que exista a classe Pessoa criada pela organização ABC e outra classe, com mesmo nome, criada pela organização DEF, porém com códigos e finalidades diferentes que podem ser utilizados por um desenvolvedor que não está vinculado a nenhuma, mas que utilizará bibliotecas de terceiro em seu projeto. Caso as classes não estivessem especificadas com o domínio, haveria duas classes Pessoa com funcionalidades diferentes (STAFUSA, 2015).
A possibilidade de ter diversos projetos no mesmo domínio implica na utilização do nome do domínio reverso, sendo especificado o nome do projeto após o domínio, por exemplo, br.com.abc.projeto1 e br.com.abc.projeto2, tornando mais fácil de identificar quais são os projetos e para quais domínios eles pertencem; assim os projetos ficam equivalentes à hierarquia de pastas (no explorador de arquivos do sistema operacional em uso, as pastas físicas do projeto ficariam br/com/abc/projeto1, caso não fosse utilizada a nomenclatura reversa do domínio, as pastas ficariam projeto1/abc/com/br, podendo ocorrer colisão de nomes e gerar diversos problemas) (STAFUSA, 2015).
Dentro de um projeto, cada classe é criada dentro de pacotes com funcionalidades similares, por exemplo, as classes responsáveis pela interface gráfica de um projeto serão alocadas no pacote br.com.abc.projeto.GUI (GUI - Graphic User Interface - Interface Gráfica de Usuário), enquanto isso, as classes responsáveis por realizar acessos a dados do banco de dados poderão ser alocadas no pacote br.com.abc.projeto.DAO, melhorando a organização dos códigos-fonte do projeto.
Construtores
Os construtores são métodos que são invocados quando é criada uma nova instância da classe na memória. Segundo Barnes (2004, p. 49), “os construtores permitem que cada objeto seja configurado adequadamente quando ele é criado”.
Um construtor é muito parecido com um método, porém não é definido especificamente como um método. Os métodos são executados por meio de uma instância já existente de um objeto, em contrapartida o construtor é executado no momento de criar um novo objeto (BATES, 2005).
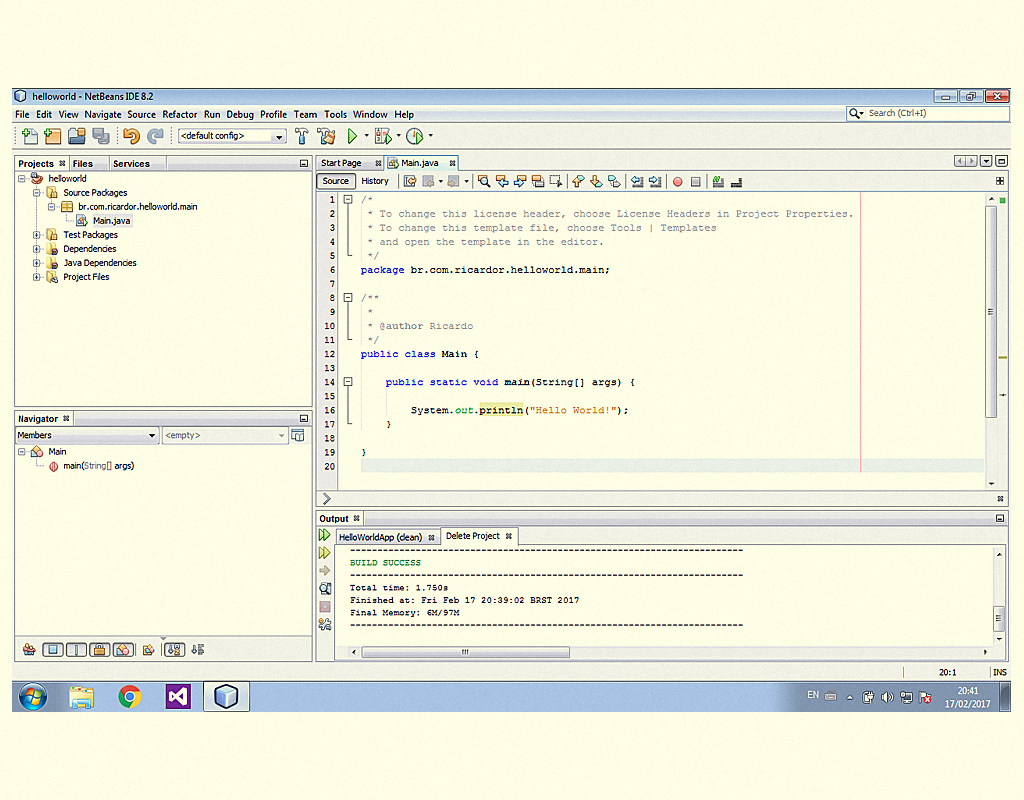
O construtor é chamado pela palavra reservada new e, em seguida, o nome da classe. No construtor, contém o código que será executado quando o objeto for instanciado. Um construtor tem o mesmo nome da classe em que ele está alocado, sem ter definido nenhum tipo de retorno, e poderá ter quantos parâmetros forem necessários. A Figura 2.1 mostra a sintaxe de um construtor simples, sem parâmetros, para observar a diferença entre construtores e métodos.
2123 Construtor e método Fonte: NetBeans IDE
Na classe Pessoa, há o construtor Pessoa(), que não tem nenhum retorno, e o método int pessoa(), que retorna um inteiro. Esse método foi criado apenas para exemplificar a diferença entre um método e um construtor, pois o método não está em uma nomenclatura clara, já que o nome do método deve ser autoexplicativo.
O construtor é executado antes de o objeto ser atribuído a uma referência de memória, ou seja, a função do construtor é fazer as operações necessárias para deixar o objeto pronto para uso, seja inicializar atributos do objeto com valores passados por parâmetro do construtor, ou, até mesmo, instanciar outros objetos que serão utilizados dentro dessa classe que está sendo criada (BATES, 2005).
Uma classe pode ter quantos construtores forem necessários, porém a assinatura de cada construtor deve ser diferente uma da outra, isto é, não é possível ter dois construtores que tenham um parâmetro do mesmo tipo; exemplificando: se a classe Pessoa tiver o construtor public Pessoa(int idade) definido, ela não poderá ter um outro construtor public Pessoa(int codigo), pois ambos recebem um parâmetro do tipo int. Se a classe não tiver nenhum construtor definido, o compilador criará automaticamente um construtor sem argumentos, apenas para instanciar o objeto. Contudo, se a classe tiver ao menos um construtor com argumentos, mas não tiver o construtor sem argumentos, o compilador não criará esse construtor. É possível definir um construtor sem argumentos e um construtor (ou vários) com argumentos, para alguma situação em que não seja conhecido qual o argumento a ser utilizado na instanciação do objeto (BATES, 2005).
Variáveis
O objeto apresenta valores que definem seus estados (atributos), que são as variáveis de instância desse objeto, e os métodos, que definem comportamentos para esse objeto. As variáveis de instância são as declaradas fora dos métodos e são específicas desse objeto; quando essas variáveis têm seus valores alterados, dizemos que o objeto teve seu estado alterado (BATES, 2005). As variáveis de instância estão ligadas ao objeto que foi instanciado por meio do new, ou seja, cada objeto instanciado será diferente um do outro e as variáveis serão específicas para cada objeto.
Além das variáveis de instância, as classes têm as variáveis locais, as quais foram declaradas dentro de um método, e elas podem ser utilizadas no escopo desse método. Fora dele, não é possível acessá-las.
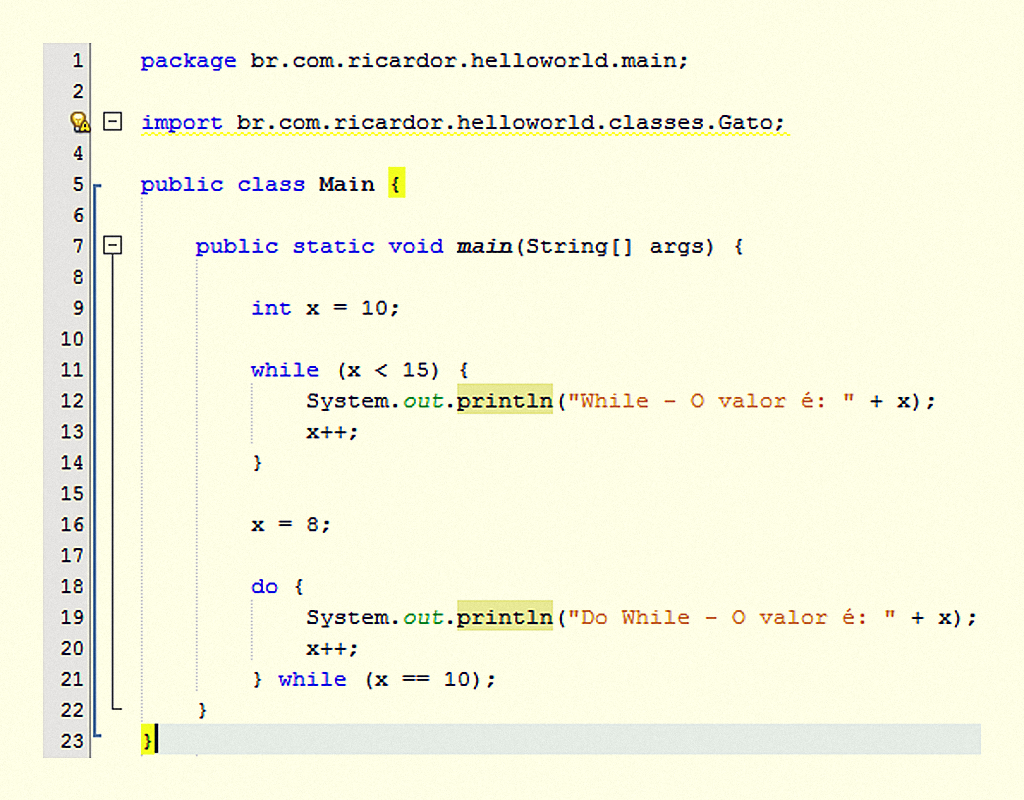
Tanto as variáveis de instância quanto as locais podem ser declaradas como tipos primitivos, que são variáveis que guardam valores em si. Esses tipos primitivos podem ser byte, char, short, int, long, float, double e boolean. A Figura 2.2 mostra a quantidade de bits e os valores que os tipos primitivos suportam.
Ao acessar uma variável que foi declarada como tipo primitivo, é acessado diretamente o valor que foi atribuído a essa variável, tanto na inicialização quanto na codificação do sistema.
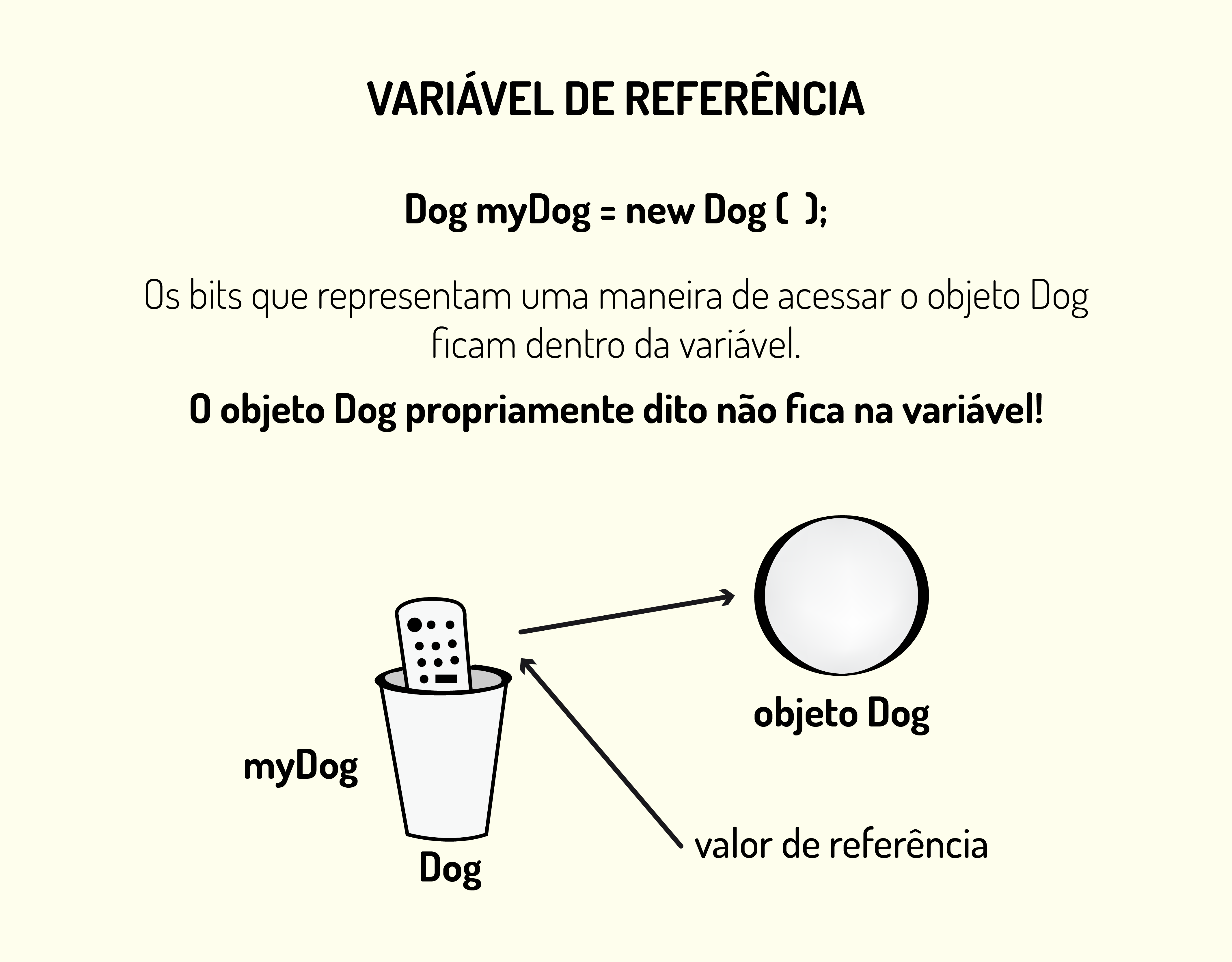
As variáveis locais e de instância podem ser declaradas também como variáveis de referência. Ao contrário do tipo primitivo, essas variáveis não guardam valores, mas sim referência para um local de memória em que está armazenado um objeto. Esse objeto pode ser qualquer um que foi criado durante a execução do sistema.
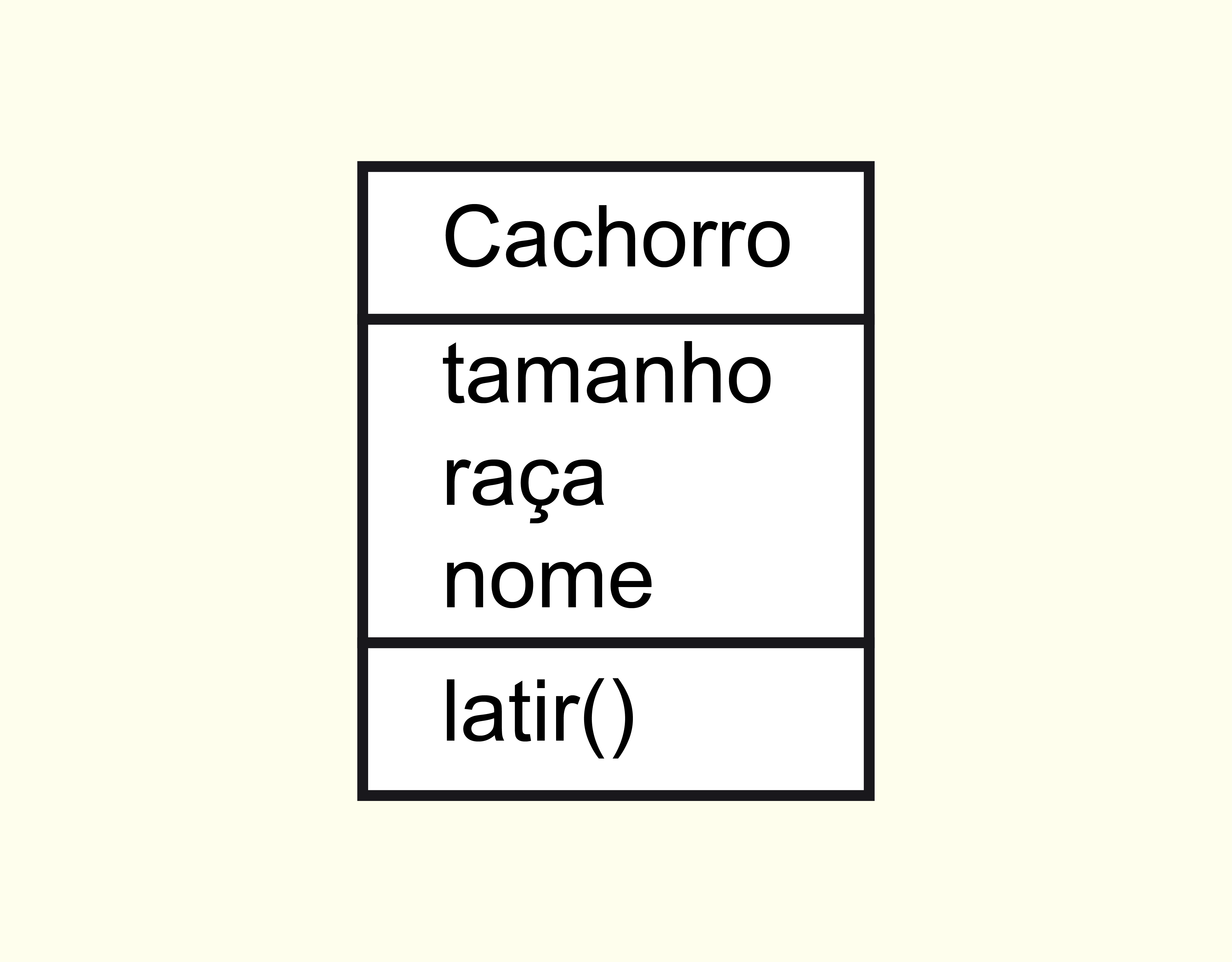
A Figura 2.3 representa como é realizada a referência para um objeto. A variável myDog, que é declarada como o tipo complexo Dog, aponta para o local da memória em que o objeto dog está armazenado, ou seja, a variável myDog guardará os bits do endereço da memória.
2223 Tipos primitivos e seus valores Fonte: Bates (2005, p. 37).
2323 Variável de referência Fonte: Bates (2005, p. 40).
Argumentos
Os argumentos (parâmetros) são valores que são passados aos métodos para serem utilizados dentro de seu bloco de comando. Os argumentos, ou parâmetros, são variáveis locais (que atuarão dentro do escopo do método) com valores (BATES, 2005).
Os parâmetros, que são utilizados tanto em métodos quanto em construtores, como citado na seção anterior, são passados sempre por valor. Nos parâmetros por valor, é feita uma cópia do valor que está fora do método e utilizada dentro do método, o valor da variável que é parâmetro pode ser alterado dentro do método, mas fora essa variável terá o mesmo valor de quando o método foi invocado.
O principal motivo para a passagem de parâmetros no Java ser feita somente por valor é reduzir erros de referência a uma variável nula. Caso uma variável fosse passada por referência para um método e, nesse método, ela fosse “destruída” (deixando a sua referência na memória como nula), após a execução do método, caso a variável fosse utilizada, resultaria em um erro de apontamento a um endereço nulo (NullPointerException).
Quando um objeto p é passado pelo parâmetro pt em um método, é realizada uma cópia da referência do objeto p para a variável pt e utilizada dentro do método. Portanto, os atributos que forem modificados no objeto serão alterados no objeto que foi passado no parâmetro do método, pois a cópia da referência dentro desse método foi alterada, alterando, assim, o valor original da referência. Contudo, isso não acontece com variáveis de tipos primitivos que são passadas por parâmetro, pois é feita uma cópia do seu valor para uma variável local (do método).
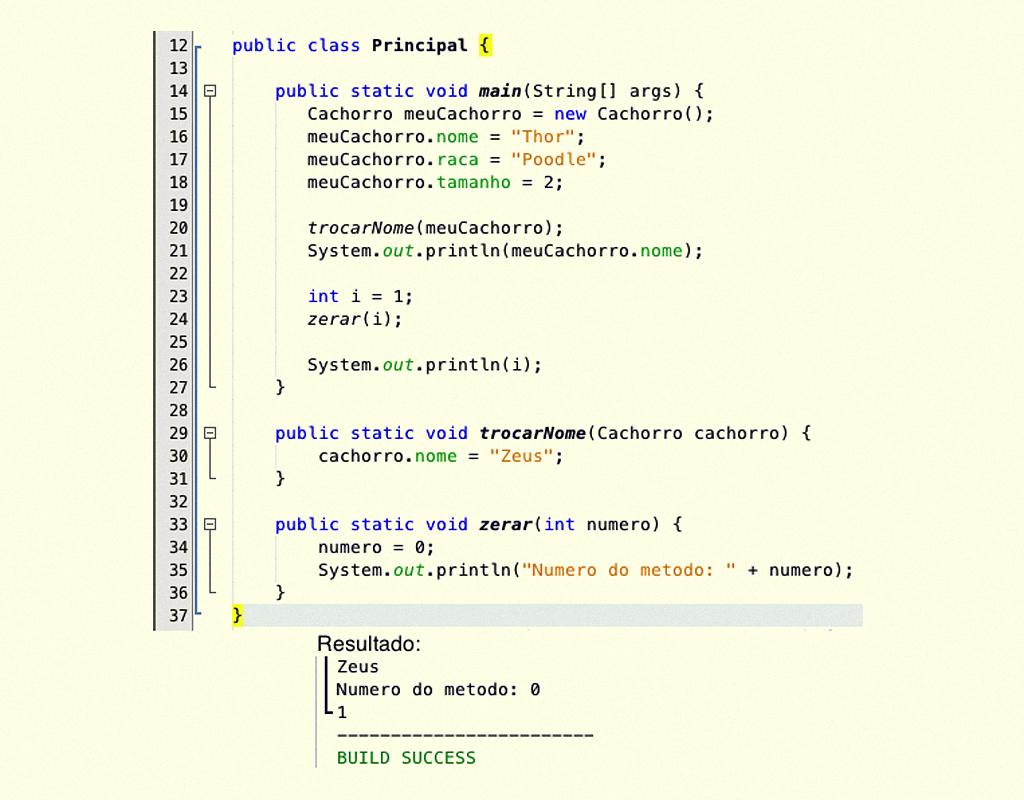
A Figura 2.4 mostra o comportamento da passagem de parâmetros das variáveis de referência e primitivas. As linhas 15 - 18 declaram e atribuem os valores da variável meuCachorro, que é um objeto do tipo Cachorro. Na linha 20, esse objeto é passado por parâmetro para o método trocarNome (definido na linha 29), que atribui um outro valor para a variável de instância nome do objeto meuCachorro. O resultado exibido na linha 21 é o valor atribuído dentro do método. Já as variáveis de tipos primitivos se comportam inversamente, como é demonstrado nas linhas 23-26 e 33-35. Nas linhas 23-26, é declarado e atribuído o valor 1 para uma variável int, invocado um método para zerar seu valor e, então, é impresso o valor. Nas linhas 33-35, o método imprime o valor que foi atribuído para a variável local. As saídas são exibidas abaixo do código, verificando que o valor da variável não é alterado quando a execução do método termina.
2423 Passagem de parâmetro de variáveis Fonte: NetBeans IDE.
Sobrecarga
A sobrecarga de um método é, simplesmente, dois ou mais métodos com mesmo nome na mesma classe, ou em classes com relacionamentos por meio da herança, mas com a lista de argumentos diferentes. A sobrecarga permite criar várias versões de um método com listas de argumentos diferentes (BATES, 2005).
O ponto forte de sobrecarregar um método é a flexibilidade que pode ser dada ao utilizador mediante métodos que realizam a mesma tarefa, ou tarefas semelhantes, com tipos ou números diferentes de argumentos (BATES, 2005). A Figura 2.5 mostra um exemplo de sobrecarga de métodos, no qual o método somar tem a primeira declaração com argumentos do tipo int, e uma sobrecarga com argumentos double. Nesse caso, a sobrecarga é interessante, pois, caso o código tenha duas variáveis do tipo double, não é necessário convertê-las para int, e sim invocar o método que tem argumentos do tipo double, como é exibido nas linhas 15, 16 e 18. O método somar é invocado com as variáveis do tipo double.
2523 Exemplo de sobrecarga de métodos Fonte: NetBeans IDE.
A ordem dos argumentos do método conta como sendo métodos diferentes, ou seja, somarValor(int i, double j) é diferente de somarValor(double j, int i), lembrando de que o nome dos argumentos não influencia na sobrecarga, e sim os tipos dos argumentos. O retorno do método poderá ser alterado apenas se a lista dos argumentos for diferente de outra já declarada, pois o retorno não é considerado para a assinatura do método, somente o nome e os argumentos.
A Figura 2.6 representa alguns casos de sobrecarga de métodos que são válidos e alguns inválidos. Os métodos das linhas 22 e 26 são sobrecargas válidas, pois têm o mesmo nome e argumentos com tipos diferentes (o primeiro método tem argumentos do tipo int, e o segundo método, argumentos do tipo double); já o método da linha 30, que não é válido, apresenta como retorno um int e seus argumentos do tipo double, mas como o retorno não é considerado para verificar a validade de sobrecargas, esse método tem a mesma assinatura que o método da linha 26. O mesmo acontece para o método da linha 34, que tem argumentos do tipo int, que é a mesma assinatura do método da linha 22.
2623 Casos de sobrecarga de métodos Fonte: NetBeans IDE.
Encapsulamento
Até o momento, utilizamos somente o modificador de acesso public, mas, agora, usaremos o modificador private.Como o próprio nome diz, o modificador de acesso public fornece acesso público à variável a que ele está vinculado, ou seja, qualquer pessoa que utilizar o objeto terá acesso a essa variável. O modificador private é totalmente o contrário, somente métodos dentro da própria classe terão acesso à variável, como é exibido na Figura 2.7.
O acesso às variáveis de instância podem ser alterados pelos modificadores de acesso, que são public, protected, default ou private. O modificador public é o menos restritivo, habilitando o acesso a qualquer lugar. O modificador protected restringe a visibilidade apenas para a própria classe ou para classes derivadas (por meio de herança), assim como classes do mesmo pacote. O modificador default especifica a visibilidade padrão, a mesma visibilidade, caso não fosse declarado explicitamente o modificador, torna os atributos, os métodos e as classes visíveis para todos os membros do mesmo pacote, enquanto o modificador private restringe a visibilidade para somente a própria classe que define objetos, atributos e métodos (RICARTE, 2007).
Podemos utilizar o modificador final para uma classe indicando que ela não poderá ser estendida, ou seja, nenhuma outra classe poderá herdar seus atributos e métodos. Caso uma classe tente estender uma classe final, ocorrerá um erro de compilação (RICARTE, 2007).
O modificador final não fica restrito apenas a classes, ele pode ser utilizado em métodos e em atributos. Um método final não pode ser redefinido em uma subclasse, e um atributo final não pode ter seu valor alterado, ou seja, é definida uma constante com o valor definido no momento da sua declaração ou no construtor da classe (RICARTE, 2007).
Os métodos podem ter argumentos definidos como final, sinalizando que esses não podem ser modificados.
2723 Modificador de acesso private e métodos acessores Fonte: NetBeans IDE.
Segundo David (2009, on-line), o encapsulamento tem a seguinte funcionalidade:
O Encapsulamento serve para controlar o acesso aos atributos e métodos de uma classe. É uma forma eficiente de proteger os dados manipulados dentro da classe, além de determinar onde esta classe poderá ser manipulada.
Além de somente ocultar os dados e fornecer a possibilidade de validação, Bates (2005, p. 58) cita que outro objetivo do encapsulamento tem envolvimento direto com a Engenharia de Software, já que pode evitar um possível retrabalho em todos os códigos que utilizam determinada classe em que não foi utilizado o encapsulamento. Supomos que as variáveis de instância são declaradas como modificadores de acesso public e são acessadas diretamente, sem passarem por nenhum método acessor, e diversos códigos utilizam essa classe. Após um tempo, é necessário modificar o projeto e incluir uma validação para que os dados de determinada variável não sejam negativos, isso influenciará todo o código que utiliza a classe, pois terá que ser escrita uma validação antes de atribuir o valor à variável de instância; contudo, se o encapsulamento fosse utilizado, seria incluída somente a validação dentro do método acessor, sem travar nenhum outro código que utilizasse a classe, gerando menos retrabalho.
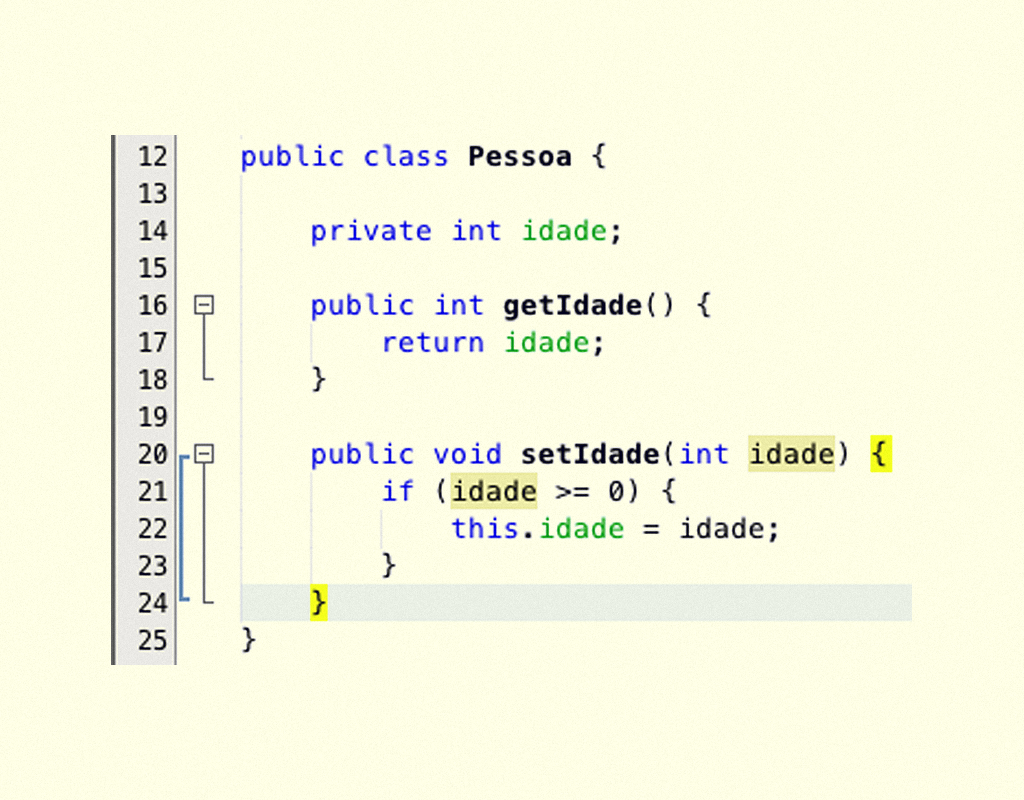
A solução para a exposição dos dados das classes são os métodos acessores (ou métodos de configuração), que utilizam o conceito de encapsulamento para serem definidos. Os métodos acessores são métodos que, como seu nome define, fornecem meios para acessar os atributos das classes. Assim como os métodos normais de uma classe, os métodos acessores definem comportamento - o de realizar o acesso, seja ele para recuperar ou para atribuir um valor a um determinado atributo. Por padrão, a nomenclatura para um método acessor de recuperação de atributo é getNomeDoAtributo() e o método para atribuir um valor ao atributo é setNomeDoAtributo(valorDoAtributo), no qual o valorDoAtributo deve ser do mesmo tipo do atributo declarado, como é exibido na Figura 2.7, linhas 16 e 20, respectivamente.
Para o funcionamento correto do encapsulamento, além dos métodos acessores, são utilizados outros tipos de modificadores de acesso nas variáveis.
A variável de instância idade (linha 14, Figura 2.7) poderá ser acessada somente dentro da classe Pessoa, pois está com seu acesso restrito pelo private. Entretanto os métodos acessores getIdade() e setIdade(int idade) estão marcados como public, podendo ser acessados de fora dessa classe.
A Figura 2.7 mostra, também, a utilização do encapsulamento por meio dos métodos get e set. Por padrão, o Java utiliza a seguinte nomenclatura para métodos acessores que setarão variáveis: setNomeDaVariável, recebendo por parâmetro o valor que será atribuído à variável. Já o método que retorna o valor da variável de instância é getNomeDaVariável, apresentando o retorno do mesmo tipo que a variável é definida. Os métodos acessores podem trabalhar tanto com tipos primitivos quanto com objetos.
No método setIdade, foi realizada uma validação para conferir se o valor do parâmetro idade é maior que zero, para, então, atribuí-lo à variável de instância idade. Como temos duas variáveis com o mesmo nome (a variável de instância idade e o argumento do método), é utilizada a palavra reservada this (linha 22, Figura 2.7), para fazer referência à variável de instância. O exemplo definido no método é simples e é realizada a atribuição apenas se a idade é maior que zero; poderíamos, porém, lançar uma exceção, alertando acerca do possível problema, mas as exceções serão estudadas na seção 4. No método getIdade(),a variável de instância foi utilizada sem o this, pois, nesse método, não há nenhuma variável com o mesmo nome, então, o compilador sabe que a referência é feita para a variável de instância.
A Figura 2.8 mostra a utilização dos métodos acessores da classe Pessoa (Figura 2.7), sendo que, na linha 18, é atribuído um valor para o método setIdade e, na linha 20, o valor da idade é atribuído a uma variável local do método. É possível ver que, na linha 16 da Figura 2.8, o compilador está exibindo um erro, pois estamos tentando acessar diretamente a variável idade, porém ela está marcada como private, portanto, não é possível acessá-la fora da classe de origem. O acesso ao valor da variável de instância idade é feito pelo método acessor getIdade() na linha 20. Se removermos a linha 16, o texto que será exibido na linha 21 é 10, pois é o valor que foi setado na linha 18.
2823 Utilização encapsulamento Fonte: NetBeans IDE.
Atividades
A respeito das classes em orientação a objeto, assinale a alternativa correta.
- Construtor é o método responsável por inicializar o objeto no momento em que é criada uma nova referência a esse objeto.
No momento em que é instanciado um novo objeto por meio da palavra-chave new, o construtor é o primeiro método a ser invocado para inicializar o objeto, mesmo que esse construtor não seja declarado explicitamente.
- No Java, não há uma maneira padrão para divisão dos pacotes e, muitas vezes, não é necessário utilizá-los.
Os pacotes servem para organizar o código a respeito da funcionalidade do código escrito, e é respeitado o formato de domínio para sua nomenclatura.
- Uma classe sempre deve ter um construtor declarado, caso contrário, não será criada corretamente no momento de criar uma nova instância.
Caso uma classe não tenha um construtor definido, ela utilizará o construtor padrão do Java, que é derivado da classe Object, ou seja, o objeto será criado normalmente, mesmo que um construtor não seja definido.
- Um método pode ser sobrecarregado de qualquer forma, trocando seus argumentos, trocando seu retorno ou trocando seu nome.
A sobrecarga de métodos ocorre quando dois ou mais métodos têm o mesmo nome, porém com lista de argumentos diferentes. O retorno não influencia na sobrecarga de métodos.
- O encapsulamento não é uma boa prática de programação, pois devem ser escritos mais códigos ao invés de setar os valores diretamente nas variáveis de instância.
O encapsulamento é de extrema importância na programação OO, pois não deixa qualquer objeto acessar as variáveis de instância e pode colocar validações para as variáveis não receberem valores incorretos.
Herança
Um dos conceitos da Orientação a Objetos é diminuir a repetição de códigos o máximo possível, com isso, são evitados o retrabalho e os possíveis erros que foram tratados em um local, mas em outro não. A herança é uma forma de reutilização de códigos em que novas classes são criadas a partir de classes já existentes, utilizando características já implementadas que são compartilhadas com a nova classe (DEITEL, 2010).
A herança é muito utilizada na Orientação a Objetos, pois promove a reutilização e o reaproveitamento do código existente. As subclasses, criadas a partir de uma classe base que é mais genérica, são mais especializadas e herdam todas as características da superclasse (DAVID, 2009).
No Java, uma subclasse estende a superclasse, herdando todas as suas variáveis de instância e métodos, mas a subclasse poderá adicionar novos métodos e variáveis de instâncias que serão exclusivos da subclasse (BATES, 2005).
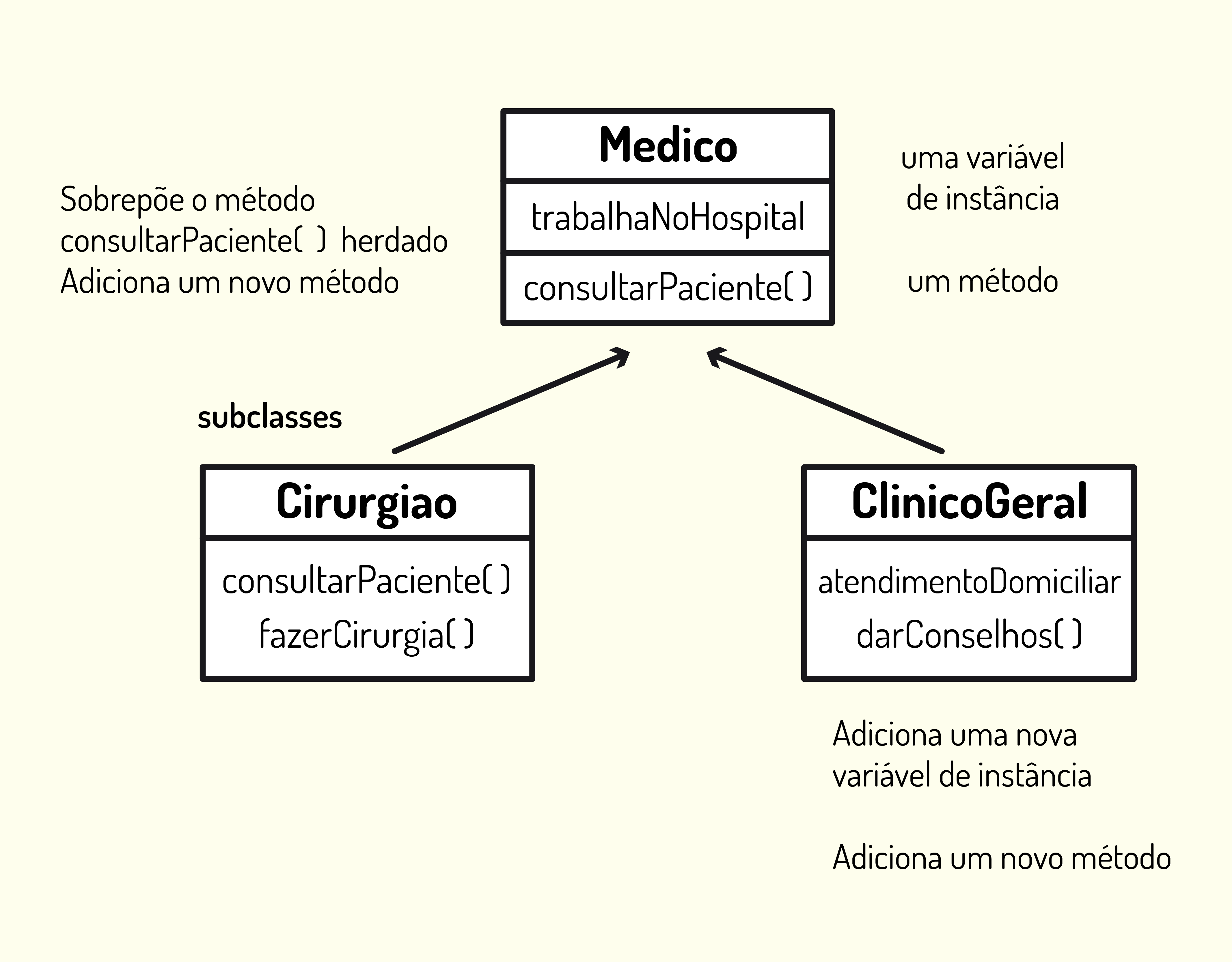
A Figura 2.9 mostra um exemplo de um projeto com herança, no qual a superclasse é Medico e suas subclasses são Cirurgiao e ClinicoGeral.
2923 Exemplo de herança Fonte: Bates (2005, p. 136).
A superclasse Medico tem uma variável de instância trabalhaNoHospital e um método consultarPaciente(); como Cirurgiao e ClinicoGeral são tipos específicos de um Medico, eles herdam as características do Medico e ambos adicionam um novo método em cada. A classe Cirurgiao adiciona o método fazerCirurgia(), que é específico de um cirurgião, e não é, necessariamente, específico a todos os tipos de médicos. Já o ClinicoGeral tem uma nova variável de instância (atendimentoDomicialiar), que não é uma característica do Cirurgiao, e também adiciona um novo método darConselhos(). A classe Cirurgiao sobrepõe o método consultarPaciente(), ou seja, o método será reescrito com característica própria do Cirurgiao.
A herança é implementada por meio da palavra reservada extends na declaração da classe. A Figura 2.10 mostra a implementação da classe Cirurgiao, que estende a superclasse Medico.
21023 Implementação da classe Cirurgiao Fonte: Bates (2005, p. 136).
Reflita
Quando o objeto Cirurgiao é instanciado e é invocado o método consultarPaciente(), qual implementação será executada? A implementação da superclasse Medico, ou a implementação específica da classe Cirurgiao?
E se a classe instanciada fosse a classe ClinicoGeral, qual implementação do método consultarPaciente() seria executada?
Herança Múltipla
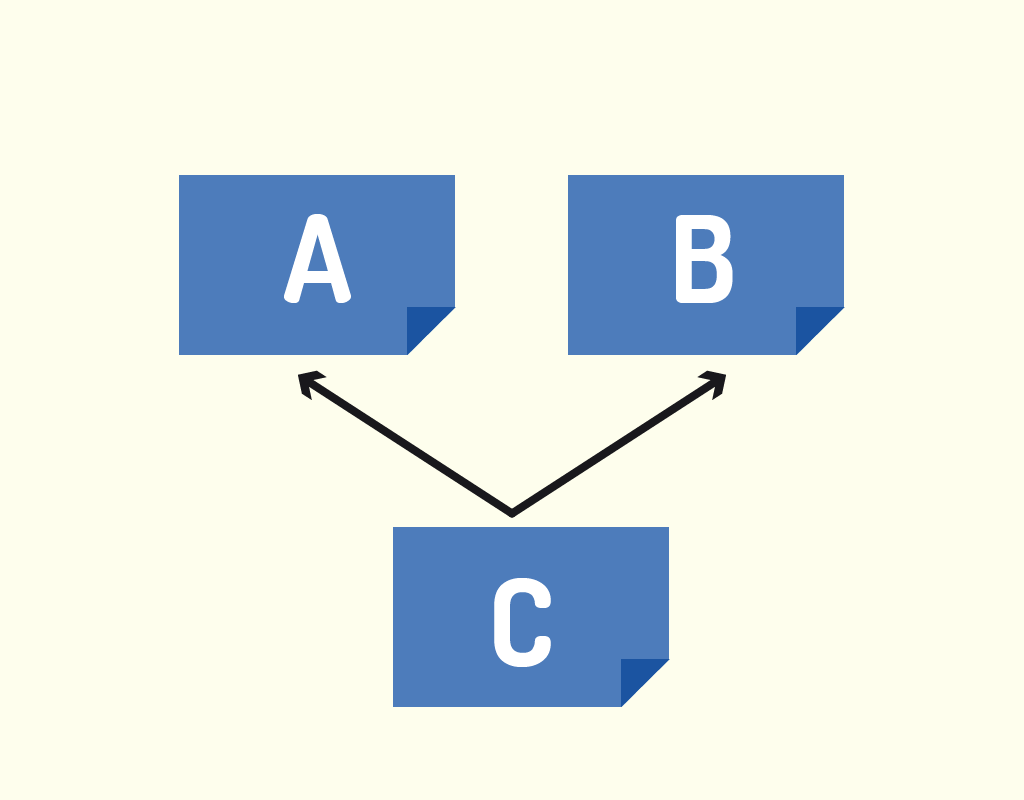
A herança múltipla permite que uma classe tenha mais que uma superclasse, ou seja, uma classe terá duas ou mais origens. Com isso, uma classe C, que é filha da classe A, pode ser filha, também, da classe B. A Figura 2.11 mostra como seria a herança múltipla de uma classe C com suas superclasses A e B.
21123 Exemplo herança múltipla Fonte: Elaborada pelo autor.
A vantagem da herança múltipla é que ela permite uma maior capacidade de especificação entre as classes. Contudo, um dos problemas da herança é um método com assinatura igual ser implementado de uma forma na classe A e de outra forma na classe B. Caso a classe C realize uma chamada desse método de sua superclasse, de qual superclasse o método seria executado? Da superclasse A ou da superclasse B?
Nas linguagens que aceitam herança múltipla, isso pode ser definido de acordo com a especificação da linguagem, por exemplo, poderá utilizar o método da primeira classe que foi declarada como superclasse.
As linguagens mais utilizadas atualmente não aceitam herança múltipla, um dos motivos é o aumento significativo da complexidade de utilização da linguagem. Algumas linguagens foram criadas para serem de fácil utilização, portanto, a incorporação de uma funcionalidade poderosa, mas complexa poderia desincentivar a utilização dessa linguagem, como também estaria saindo do escopo em que foi criada.
É-um e Tem-um
A herança cria uma relação entre duas classes em que uma estende a outra, ou seja, a subclasse complementa a superclasse. Para a utilização correta da herança, o ideal é aplicar o teste É-Um (Is-a, em inglês). A herança deve ser utilizada apenas nos casos em que o teste É-Um é verdadeiro, caso contrário, será utilizada a herança em subclasses que não são derivadas da superclasse, podendo gerar futuras inconsistências no código (BATES, 2005).
A seguir, estão exemplos do teste É-Um que estão corretos:
- O triângulo É-UMA forma.
- O cirurgião É-UM médico.
- O gato É-UM animal.
Ou seja, esses casos podem ser utilizados em uma derivação com herança e funcionarão. Se a classe B estende a classe A, a classe B É-UMA classe A(BATES, 2005).
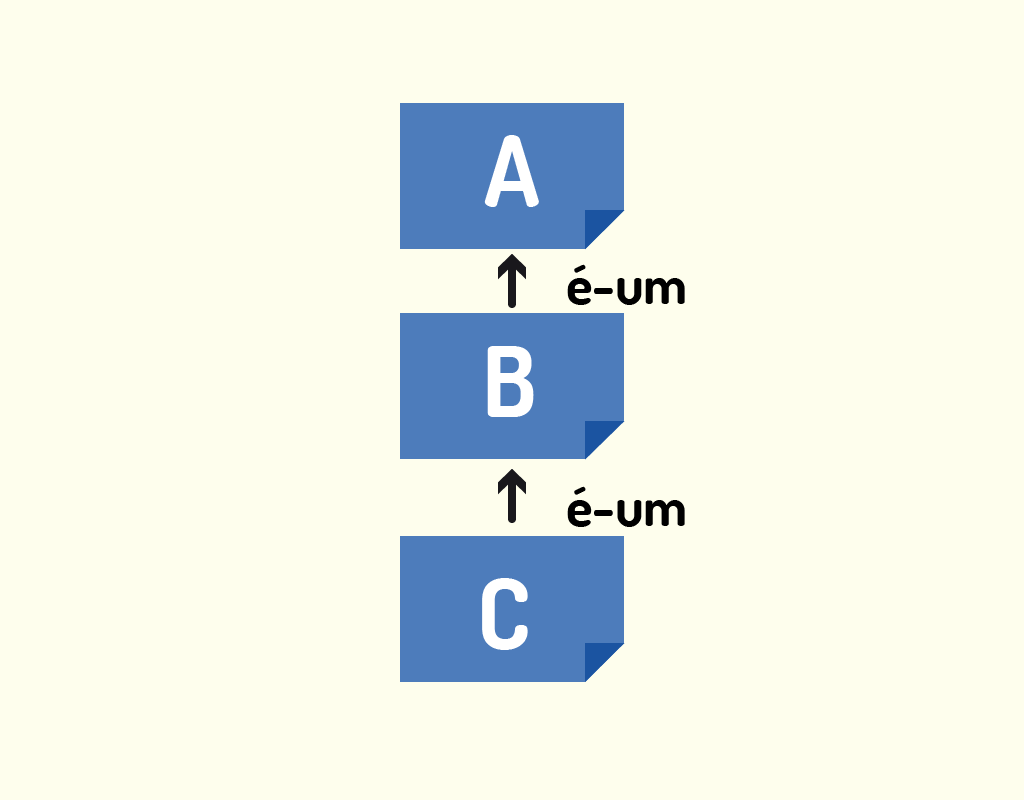
O teste É-UM deve funcionar em qualquer lugar da árvore de herança, se a herança foi bem projetada. Caso a classe C estenda a classe B, e a classe B estenda a classe A, a classe C passará no teste É-UM tanto para a classe B quanto para a classe A (BATES, 2005).
A Figura 2.12 mostra o teste é-um explicado anteriormente, no qual a classe A é a superclasse, a classe B herda de A e a classe C herda de B, então, B é-um A, C é-um B e C é-um A.
21223 Teste é-um Fonte: Elaborada pelo autor.
Um detalhe importante é que o teste É-UM é unidirecional, ou seja, se a classe B É-UMA classe A, não é correto afirmar que a classe A É-UMA classe B.
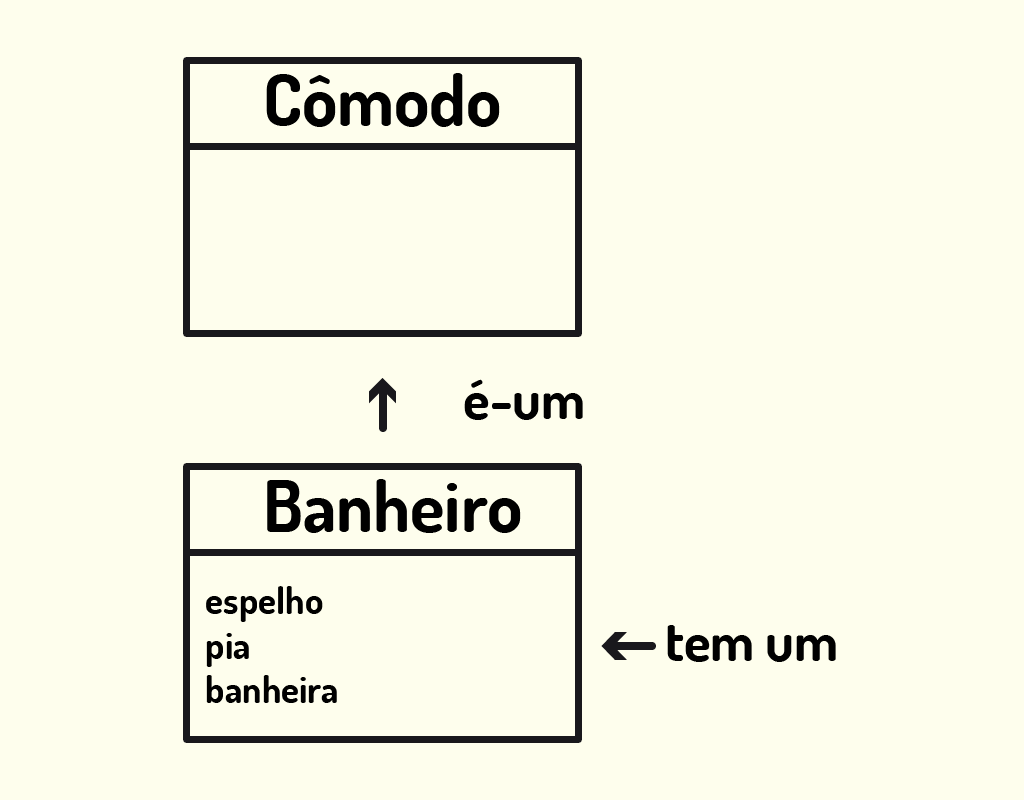
Muitas vezes, quando o teste É-UM não está correto, ele pode ser visto como Tem-um (Has-a, em inglês), por exemplo, um banheiro TEM-UMA banheira, mas um banheiro não É-UMA banheira, muito menos o inverso, uma banheira não É-UM banheiro (BATES, 2005).
Normalmente, a aplicação do TEM-UM é utilizada para verificar quais variáveis de instância (atributos) uma classe poderá ter. Utilizando o exemplo do banheiro, ele TEM-UM espelho, TEM-UMA pia, contudo ele É-UM cômodo de uma casa (dependendo de como é o projeto da aplicação dessa casa), como exibido na Figura 2.13.
21323 Tem-um Fonte: Elaborada pelo autor.
Classes abstratas
Uma classe abstrata é uma classe que não pode ser instanciada, ou seja, não é possível criar uma nova referência na memória para um objeto por meio do comando new para uma classe abstrata (CAELUM, on-line).
Se uma classe não pode ser instanciada, qual seria a vantagem de ter uma classe abstrata? A classe abstrata idealiza um tipo, ou seja, é um rascunho de como suas subclasses deverão ser ou se comportar.
Uma classe torna-se abstrata quando é utilizado o modificador abstract na declaração da classe. Se o programador tentar instanciar uma classe abstrata, o compilador gerará um erro e não será possível compilar o código.
As classes abstratas são úteis nos casos em que uma determinada classe não pode ser instanciada, pois poderia gerar inconsistência no projeto, como no exemplo de herança em que há a classe Medico e dela derivam duas classes que são Cirurgiao e ClinicoGeral. Nesse caso, estaríamos trabalhando apenas com esses dois tipos de médicos, portanto, não faria sentido ter um objeto do tipo Medico instanciado, já que ele é genérico e não tem uma implementação específica para seus métodos; porém, em outros projetos, pode ser que seja útil instanciar um objeto do tipo Medico, por isso, seu uso deve ser específico para cada tipo de projeto.
As classes abstratas podem ter implementação de algum método que é geral para suas subclasses (que poderão se comportar do mesmo modo, ou reescrever o método), mas, também, pode apenas definir métodos que deverão ser implementados pelas suas subclasses. Esses últimos são os métodos abstratos.
Um método abstrato é um método sem implementação, porém com a palavra abstract na sua assinatura. Com isso, todas as classes que são herdadas da classe abstrata deverão implementar esse método, caso não implementem, será gerado erro de compilação, e uma classe poderá ter um método abstrato somente se ela for abstrata (CAELUM, on-line).
A seguir, está a declaração de um método abstrato.
21423 Classe abstrata Fonte: NetBeans IDE.
O método abstrato não tem os sinais de início e término de códigos ({ e }), termina com ponto e vírgula (;) e pode ter argumentos definidos, ou não ter argumentos, como no exemplo anterior.
Atividades
A herança é uma funcionalidade muito importante na Orientação a Objetos, facilitando a especificação do mundo real. Acerca da herança, assinale a alternativa correta.
- Uma subclasse herda apenas as variáveis de instância, sendo necessário redefinir todos os métodos.
Na herança, tanto os métodos quanto as variáveis de instâncias são herdadas, porém podem ser criados novos métodos na subclasse que não existiam na superclasse.
- Uma classe só poderá ser estendida se ela satisfizer o teste É-UM, que indica que a subclasse complementa a superclasse.
O teste É-UM é essencial para verificar a relação de herança, pois, se um objeto não passar no teste, ele não será um subtipo daquela classe.
- O teste TEM-UM é similar ao teste É-UM e pode ser usado para representar herança.
O teste TEM-UM verifica se o item testado faz parte da classe, mas não é uma derivação da classe, ou seja, se um item é verdadeiro no teste TEM-UM, ele será um atributo do objeto, como variável de instância, ou, até mesmo, vetores, como ArrayLists, dentre outros.
- As classes abstratas têm relação com a herança, pois uma classe abstrata pode ser herdada por outras classes e, quando é instanciada, pode invocar métodos da sua subclasse.
Uma classe é abstrata quando não pode ser instanciada, porém pode ter implementação. As classes que herdam as classes abstratas devem implementar os métodos que estão declarados na classe abstrata, mas não estão implementados.
- Uma classe abstrata não pode ter implementação em nenhum método, o que faz com que as classes que são herdadas dessa classe abstrata implementem esses métodos.
As classes abstratas podem ter métodos sem implementação, porém podem ter métodos implementados também. A exigência é que uma classe abstrata não seja instanciada e as classes que são filhas dela implementem os métodos que não são implementados.
Polimorfismo
Polimorfimo pode ser definido como:
Um princípio a partir do qual as classes derivadas de uma única classe base são capazes de invocar os método que, embora apresentem a mesma assinatura, comportam-se de maneira diferente [...]. (BALBO, 2010, on-line, grifos do autor).
Segundo Horstmann (2004, p. 356), “o termo polimorfismo vem do grego e significa muitas formas”. Ou seja, uma classe base pode ter funcionalidades (atributos e objetos) que serão utilizadas em objetos distintos, mas implementadas diferentemente em cada objeto.
O polimorfismo pode ser aplicado com os exemplos citados anteriormente na seção a respeito da Herança. Um Cirurgiao é-um Médico, assim como o ClinicoGeral também, ou seja, o Médico pode ter várias formas, como Cirurgião e/ou Clínico Geral. O polimorfismo faz com que um objeto tenha a capacidade de ser referenciado de diversas formas (porém somente de um tipo).
O exemplo mais geral de polimorfismo, no Java, é que todas as classes são do tipo Objeto, ou seja, a classe Cirurgião, além de ser um Médico, também é um Objeto, portanto, se tivermos um método que receba um Objeto por parâmetro, poderemos passar um Objeto do tipo Cirurgião (como Cirurgião descende de Objeto, o compilador não acusará erro no código, porém poderá ocorrer erro durante a execução do programa, já que o código pode não estar preparado para receber determinado tipo de Objeto).
Voltando ao nosso exemplo dos Médicos, se alterarmos a classe ClinicoGeral e inserirmos o método consultarPaciente(), implementado de forma específica para o Clínico Geral, como é exibido na Figura 2.15, nas linhas 12-25 da classe ClinicoGeral, e fossem executadas as linhas 16-19 da classe Principal, a implementação do método consultarPaciente() seria executada por meio da classe Cirurgião. Isso se deve ao fato de que foi criada uma referência para um objeto Cirurgiao, e, como a classe Medico é a superclasse do Cirurgiao, a atribuição da linha 18 da classe Principal da Figura 2.15 é executada corretamente, caracterizando o polimorfismo.
Reflita
Com base na Figura 2.15, se fosse declarado e instanciado um objeto do tipo ClinicoGeral, seria possível atribuir esse objeto ao objeto Cirurgiao (declarado na linha 16)?
21523 Polimorfismo Fonte: NetBeans IDE.
Caso a classe Principal da Figura 2.15 fosse alterada para a da Figura 2.16, o código funcionaria normalmente, pois o objeto referenciado será do tipo Cirurgiao, por mais que seja declarado como Medico, pois Medico é a superclasse de Cirurgiao. Contudo, na linha 19, não é possível invocar o método fazerCirurgia(), que está declarado e definido na classe Cirurgiao, pois o objeto que está invocando o método é do tipo Medico. Mesmo que o objeto medico esteja recebendo um objeto referenciado como Cirurgiao, o compilador entende que o objeto medico é do tipo Medico, e, na classe Medico, não existe o método fazerCirurgia(), tanto que o compilador emite mensagem de erro de compilação que o método não existe.
21623 Polimorfismo Fonte: NetBeans IDE.
Se em algum método da aplicação for necessário receber um Medico por argumento, esse medico poderá ser qualquer objeto referenciado como Medico, Cirurgiao ou ClinicoGeral, pois, mesmo Cirurgiao e ClinicoGeral sendo classes mais específicas, elas se encaixam como Medicos; por exemplo, um paciente está doente e foi para um plantão de um hospital, ele poderá ser atendido por qualquer tipo de médico que esteja atendendo no plantão, porém, se precisar de uma cirurgia, somente o cirurgião poderá realizar.
Sobreposição de métodos
A sobreposição de métodos (override), ou reescrita de métodos, permite reescrever nas subclasses os métodos criados na superclasse. Ao contrário da sobrecarga de métodos, o método que será sobreposto deverá ter a assinatura idêntica, ou seja, mesmo nome, tipo de retorno e tipos e quantidades de parâmetros (ALVES, on-line).
Os métodos podem ser sobrepostos em classe concreta ou abstrata. Como um construtor é um método, ele também pode ser sobreposto. No método sobreposto, podem ser utilizadas algumas palavras-chave para fazer menção à superclasse ou a atributos utilizados diretamente na classe. A palavra-chave super é utilizada para informar ao programa que será utilizado o construtor da superclasse.
A principal funcionalidade de um método sobreposto é alterar a forma como o método será executado, principalmente se a subclasse tem características específicas e se comporta de uma forma diferente da superclasse.
No exemplo dos médicos citado na seção do Polimorfismo, o método consultarPaciente() é um método sobreposto por ambas as classes que derivam de Medico. Quando um método é sobreposto, o NetBeans pede para indicar o método com a anotação @Override acima do método, como mostra a Figura 2.17.
21723 Sobreposição de métodos Fonte: adaptada de Bates (2005, p. 126).
Utilizando o exemplo da seção de Polimorfismo, quando for referenciado um objeto Cirurgiao (podendo ser declarado do tipo Cirurgiao ou Medico por causa do polimorfismo) e invocado o método consultarPaciente(), será executada a implementação da classe Cirurgiao, imprimindo o texto da linha 16. Caso essa classe não tivesse o método sobreposto, seria executada a implementação da classe Medico, pois é sua superclasse e nela há uma implementação para esse método.
Interfaces
Uma interface nada mais é que uma classe com todos seus métodos abstratos, ou seja, sem nenhuma implementação, somente com a especificação da funcionalidade que uma classe deve conter (RICARTE, 2007).
Ricarte (2007, p. 28) define interface Java como:
uma classe abstrata para a qual todos os métodos são implicitamente abstract e public e, todos os atributos são implicitamente static e final. [...] uma interface implementa uma classe abstrata pura.
Qual seria a diferença de uma interface para uma classe abstrata? A interface não tem nenhum corpo, apenas declaração, já uma classe abstrata deverá ter, pelo menos, um método abstrato, porém pode ter definição (implementação) de outros métodos e atributos (RICARTE, 2007). O corpo de uma interface define apenas assinaturas de métodos e constantes, sem nenhuma implementação e não pode ter atributos.
Uma classe abstrata é estendida (como visto na seção de Herança) por classes derivadas, enquanto uma interface é implementada, mediante a palavra-chave implements, por outras classes (RICARTE, 2007). A interface estabelece um contrato com as classes que irão implementá-la, pois, quando uma classe implementa uma interface, ela deve implementar todos os métodos declarados na interface, ou seja, todas as funcionalidades especificadas na interface serão oferecidas pela classe (RICARTE, 2007).
Ao contrário da herança, na qual uma classe pode herdar todas as características (atributos, métodos, constantes, dentre outras) apenas de uma superclasse, uma classe pode implementar diversas interfaces, desde que respeite o contrato e implemente todos os métodos declarados em todas as interfaces.
A Figura 2.18 mostra a declaração de uma interface Doutor com dois métodos que deverão ser implementados por uma classe concreta. Lembrando de que, na implementação dos métodos pela classe, esses métodos serão sobrepostos, portanto, deve-se marcá-los com a anotação @Override.
21823 Interface Doutor Fonte: NetBeans IDE.
Bates (2005, p. 165) mostra algumas dicas interessantes para decidir quando criar uma classe, uma subclasse, uma classe abstrata ou uma interface:
- caso a classe não passe no teste É-UM com nenhum outro tipo, crie uma nova classe que não estenda nada.
- caso uma classe necessite ser mais específica que uma outra classe já existente e necessite sobrepor/adicionar novos comportamentos, estenda uma classe (crie uma subclasse utilizando herança).
- utilize uma classe abstrata para definir um modelo para as subclasses, se tiver que implementar algo na superclasse. Como ela não pode ser instanciada, não há a possibilidade de ter um objeto da classe abstrata.
- utilize uma interface para definir funções que as outras classes devem realizar.
Atividades
A respeito das características do Polimorfismo, assinale a alternativa correta.
- O Polimorfismo é a característica da orientação a objetos que permite que um objeto estenda outro, fazendo com que suas características sejam compartilhadas.
Essa definição, que é uma característica da OO, faz menção à herança, e não ao polimorfismo.
- Assim como na herança, uma classe que implementa uma interface pode implementar apenas uma interface.
Na herança, é permitido uma classe herdar as características de apenas uma superclasse, porém uma classe pode implementar diversas interfaces.
- Um objeto declarado do tipo X pode ser instanciado para a classe Y, desde que Y seja subclasse de X. Com isso, qualquer método definido em Y pode ser invocado.
Por mais que Y seja subclasse de X, a classe Y pode ter métodos que não estão na classe X, portanto, o objeto só poderá invocar métodos que são do tipo que ele é declarado, e não do tipo que é instanciado.
- A única diferença de uma classe abstrata para uma interface é a forma como é declarada, pois ambas não podem ter implementação.
A interface não pode ter nenhum tipo de implementação, enquanto a classe abstrata deve ter métodos sem implementação, mas pode ter métodos implementados (concretos).
- Um método recebe como argumento um objeto do tipo X, e esse objeto X é uma superclasse de Y, portanto, é possível passar um objeto do tipo Y por parâmetro.
Como a classe Y é derivada da classe X, ela pode ser passada por parâmetro no lugar de X, pois a classe X pode ter a forma de Y.
Tratamento de exceções
Para Deitel (2010, p. 336), “uma exceção é uma indicação de um problema que ocorre durante a execução de um programa. O nome exceção indica que é algo que não ocorre frequentemente”.
Uma exceção pode ocorrer de diversas maneiras, principalmente em pontos que não foram tratados pelo programador em situações específicas, por exemplo, tentar utilizar métodos de um objeto que está nulo e não foi ainda referenciado. Nesse caso, a exceção ocorrerá e a execução do programa será abortada.
O tratamento de exceções em Java permite que essa exceção seja contornada e o programa continue sua execução em um estado satisfatório, com nenhum dado corrompido ou incorreto.
O exemplo citado anteriormente, de um objeto não referenciado, gera uma exceção NullPointerException, pois é utilizada uma referência nula quando se espera um objeto.
O tratamento de exceções remove a linha de execução da linha principal e a desvia para o bloco de código para realizar o tratamento desse erro. A escolha da exceção a ser tratada pode ser feita pelo programador, desde todas as exceções em geral, até as exceções de um certo tipo ou as exceções de um grupo de tipos relacionados (exceções que têm relação por meio de uma superclasse em sua hierarquia) (DEITEL, 2010).
Classes de exceção
As exceções podem ser de dois tipos (VINICIUS, 2013, on-line):
- Checkedexceptions (exceções verificadas): são erros que acontecem fora do controle do programa, mas devem ser tratadas pelo desenvolvedor.
- Unchecked exceptions (exceções não verificadas): também chamadas de Runtime Exceptions, pois são, normalmente, em tempo de execução, podem ser evitadas se forem tratadas e analisadas pelo desenvolvedor. Caso não haja um tratamento, o programa irá parar em tempo de execução.
Além das exceções, temos os Errors, que diz respeito a um tipo específico de exceção que não pode ser tratado pela aplicação, impossibilitando-a de continuar executando.
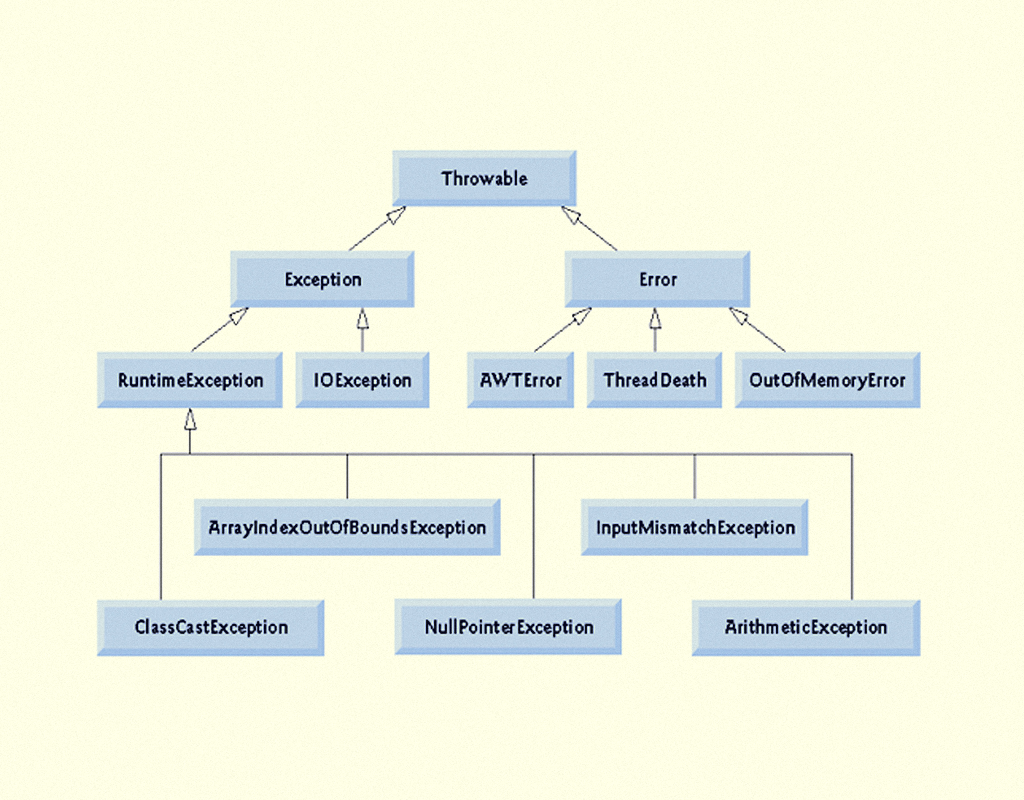
Como todo outro objeto em Java, uma exceção é uma instância de uma classe em uma hierarquia de classes. As exceções sempre serão subclasses da classe Exception, que, juntamente com a classe Error, são herdadas da superclasse Throwable (Figura 2.19).
A diferença entre Erro e Exceção é que o primeiro não poderá ser tratado, enquanto todas as subclasses de Exception são exceções e devem ser tratadas, exceto a classe RunTimeException, que é um erro e não precisa de tratamento, sendo utilizados os blocos try/catch e/ou throw/throws (VINICIUS, 2013, on-line).
21923 Hierarquia das classes de exceções Fonte: Vinicius (2013, on-line).
Identificar se as exceções serão verificadas ou não verificadas não é algo exato, porém os seguintes conselhos podem ser considerados (BARNES, 2004):
- utilizar exceções não verificadas em situações que devem levar à falha do programa, provavelmente proveniente de um erro lógico que evitará que o programa prossiga; enquanto as exceções verificadas devem ser utilizadas nos momentos em que um problema surgiu, mas que pode ser tratado para sua recuperação.
- utilizar exceções não verificadas em situações que deveriam ser evitadas, como um índice inválido em um array, resultando na exceção IndexOutOfBoundsException, que poderia ser evitada com mais atenção do desenvolvedor, deduzindo-se que as exceções verificadas são utilizadas para verificar situações que estão fora do controle do desenvolvedor, como um disco cheio ao realizar a gravação de um arquivo.
Lançando/propagando exceções
As exceções podem ser capturadas (como será visto na próxima seção) e então tratadas para verificar qual erro e o que pode ser feito com elas, ou pode ser propagada para ser tratada em um outro método, porque, por algum motivo, não pôde ser tratada no método que gerou a exceção (VINICIUS, 2013, on-line).
Os métodos que são executados são colocados em uma pilha; à medida que o fluxo de execução termina determinado método, ele é removido da pilha, e o fluxo vai para o próximo método. A propagação de exceções faz com que a exceção não seja tratada nesse método e seja propagada para um nível acima da pilha (VINICIUS, 2013, on-line).
A propagação é definida pela cláusula throws na declaração de um método. Ou seja, a cláusula throws declara quais exceções podem ser lançadas pelo método, auxiliando outros desenvolvedores que poderão utilizar o código, deixando explícito qual erro pode acontecer. A cláusula throws é exibida na Figura 2.20.
22023 Cláusula throws Fonte: Vinicius (2013, on-line).
Ao contrário da cláusula throws, que é declarada no cabeçalho do método e propaga a exceção que pode ocorrer no método para outro método, a cláusula throw lança uma nova exceção, caso ocorra algum erro dentro do método, para essa nova exceção ser tratada em outro método. A Figura 2.21 mostra a utilização do throw.
22123 Cláusula throw Fonte: Vinicius (2013, on-line).
A diferença entre as duas cláusulas é que a throw cria uma nova exceção, na Figura 2.21 foi criada a exceção IllegalArgumentException(), que poderia ser criada com uma string no seu construtor, informando qual erro aconteceu. O exemplo foi somente uma demonstração de criação de uma exceção, por isso a exceção foi lançada em um teste com um valor aleatório. A exceção poderia ser lançada diretamente, sem ser atribuída a nenhuma variável, por exemplo:
throw new IllegalArgumentException(“Valor solicitado maior que o saldo disponível”);
Essa exceção foi criada com uma mensagem de erro no construtor de exceção, portanto, o método que captura a exceção poderá ver qual erro ocorreu.
Capturando exceções
Quando um método contém um código que pode ser perigoso de executar, ou seja, pode ocorrer uma exceção que será lançada/propagada por meio do throw/throws, ele deverá saber como lidar com o possível erro (BARNES, 2004).
A utilização da cláusula try indica que o bloco de código seguinte (dentro da cláusula) estará realizando algo arriscado, e a cláusula catch serve para tratar a exceção lançada dentro do bloco try. Contudo, se a exceção não for capturada dentro do bloco catch, ou seja, se a exceção não for a esperada pelo bloco catch, o sistema terá sua execução interrompida (VINICIUS, 2013, on-line).
Uma utilização frequente do bloco try/catch ocorre em operações com banco de dados; nas transações de Rollback, caso ocorra uma exceção, as alterações não são persistidas no banco de dados, executando um Rollback e impedindo que o banco de dados possa ter dados inconsistentes (VINICIUS, 2013, on-line).
Dentro do bloco do try, no momento em que um método é chamado e lança uma exceção, a execução da instrução é interrompida naquele método e é desviada para a cláusula catch correspondente (caso a cláusula trate a exceção que ocorreu). Caso não ocorra exceção durante a execução do código que está na cláusula try, a cláusula catch não será executada e o fluxo de instruções seguirá normalmente pelo código (BARNES, 2004).
O bloco try/catch pode ter uma terceira cláusula, que é chamada de finally, que sempre é executada, finalizando a sequência de comandos, independente de ter ocorrido algum erro no sistema. O bloco finally é opcional, ao contrário do try/catch (se for utilizado o try, o catch deve vir obrigatoriamente após o try e será executado somente se acontecer um erro na execução), não sendo necessário aparecer, porém, quando aparecer, deve vir sempre após o bloco do catch (VINICIUS, 2013, on-line).
Normalmente, um bloco finally é utilizado para encerrar a sequência de comandos que vieram anteriormente, como finalizar uma conexão com um banco de dados, fechar algum arquivo em edição, dentre outros.
A Figura 2.22 mostra a utilização dos blocos try/catch/finally em uma operação de divisão, a qual não pode ter um denominador igual a zero e não pode receber letras para a operação.
22223 Exemplo try/catch/finally Fonte: Vinicius (2013, on-line).
O exemplo solicita ao usuário informar dois números (numerador e denominador) para realizar a divisão entre eles. Na linha 25, é realizado um laço do - while, que continuará executando até o momento em que a variável continua receba o valor false, que ocorre na linha 36, quando a divisão foi realizada com sucesso, caso contrário, o laço será executado até o momento que não ocorra nenhum erro.
A chamada ao método calculaQuociente é realizada dentro do bloco try, pois o método lança uma exceção ArithmeticException, que é declarada na assinatura do método (linha 17). O tratamento das exceções ocorre nas linhas 38, tratando a exceção InputMismatchException, a qual verifica se houve algum problema com os dados inseridos, como no exemplo que espera um inteiro e, se for inserida uma letra, o Java automaticamente lançará a exceção. Na linha 41, é tratada uma exceção do tipo ArithmeticException, que ocorre quando houve algum erro aritmético, como uma divisão por 0.
Caso o tratamento da exceção da linha 38 fosse retirado, o sistema iria interromper sua execução, pois, se fosse informada uma letra, aconteceria um erro que não foi tratado e que não era esperado que acontecesse.
Nas linhas 38 e 41, são tratadas múltiplas exceções em um bloco try/catch, não sendo necessário tratar apenas uma exceção, mas podendo tratar várias exceções que podem acontecer, da mais específica para a mais geral. Como todas as exceções são derivadas da classe Exception, uma única cláusula catch com essa classe iria capturar a exceção, porém teria menos detalhes, não foi capturada com uma classe de instância mais específica (BARNES, 2004).
Verificação dos erros
Dentro de uma exceção, é possível verificar algumas mensagens do erro que ocorreu. Foi mencionado anteriormente que era possível lançar uma nova exceção informando uma mensagem de erro no seu construtor, agora, veremos alguns métodos que são nativos das exceções que mostram algumas informações sobre o erro.
Esses métodos são da classe Throwable, que é a superclasse de todos os erros e as exceções, e são gerados para sua subclasses.
Os principais métodos de captura de erros são (VINICIUS, 2013, on-line):
- printStackTrace: imprime a pilha de erro encontrada na execução, exibindo onde foi que ocorreu o erro;
- getStackTrace: recupera as informações que são impressas pelo método acima;
- getMessage: método que retorna a mensagem que contém a lista dos erros armazenados na exceção no formato String.
O método getMessage() é constantemente utilizado, pois informa a mensagem completa do erro que ocorreu, sendo mais fácil a identificação do erro e, também, personalizando a mensagem de erro, para que não chegue ao usuário final as mensagens de erro padrão do Java, o que pode assustar o usuário.
Criação de classes de exceção
Podem existir casos em que as classes de exceção padrão não tenham clareza e detalhamento suficiente para informarem ao usuário qual a natureza do problema. Nesses casos, é interessante ter uma classe mais específica que pode ser definida utilizando herança (BARNES, 2004).
As novas classes de exceções podem ser subclasses de Exception, tornando-se novas classes de exceções verificadas, enquanto as que são herdadas de RuntimeException seriam exceções não verificadas (BARNES, 2004).
As classes de exceção suportam a passagem de um argumento String para o construtor, que seria a mensagem de diagnóstico para essa exceção. O principal motivo de construir classes específicas de exceção é informar mais detalhes acerca do erro que aconteceu em determinada parte do sistema. Um exemplo citado por Barnes (2004, p. 301) é a busca de um dado, por meio de uma chave, em uma lista de endereço. Quando a busca falha, a classe de exceção personalizada informa qual erro aconteceu e qual índice (chave) foi utilizado para realizar a busca, que, em determinada situação da aplicação, pode ser útil para solucionar o problema.
O exemplo da classe de exceção criada por Barnes (2004) está exibido na Figura 2.23. A classe NoMatchingDetailsIException é herdada da classe Exception e tem um construtor recebendo uma String, que é a chave que foi utilizada como parâmetro para detalhar mais a mensagem de erro. Foi criado um método getKey() para retornar a chave, por meio do encapsulamento, para não acessar diretamente um atributo da classe, e um método toString(), que é o método de diagnóstico que retorna a mensagem de erro personalizada para essa classe. Como essa classe é herdada da classe Exception, além da utilização dos métodos criados especificamente para essa nova exceção, podem ser utilizados métodos padrões das exceções, como printStackTrace() e getMessage().
22323 Classe de exceção personalizada Fonte: Barnes (2004, p. 301).
Atividades
Exceções são erros que podem ocorrer nos programas por diversos motivos, muitas vezes, levando até a interrupção do programa. Acerca das exceções, assinale a alternativa correta.
- A exceção ocorre somente por causa dos dados que o usuário insere no programa, não ocorrendo de outra forma.
A exceção pode ocorrer por dados inseridos pelo usuário, como tipos diferentes (o programa espera um número, mas é informada uma letra), e não é tratada pelo desenvolvedor, mas pode ocorrer por erros de programação, como acessar um índice inexistente em um ArrayList.
- As exceções são exclusivamente do método e da classe em que ocorreram, não sendo possível tratá-las em outro lugar.
As exceções podem ocorrer em um método, porém serem tratadas em outro método da pilha de execução, assim como podem ser lançadas para serem tratadas em outra classe.
- Os blocos try/catch servem para capturar exceções e tratá-las, porém podem capturar apenas as exceções genéricas (classe Exception) e não podem ser utilizados em exceções específicas.
Os blocos try/catch capturam qualquer tipo de expressão, desde a mais genérica até a mais específica, porém a ordem em que as exceções são capturadas influenciará no detalhamento do erro.
- As exceções de tempo de execução (Runtime Exception) são classificadas como não verificadas e, caso não forem tratadas, podem ocasionar falha de execução do programa.
As Runtime Exceptions são exceções que acontecem enquanto o programa está executando, por algum acesso incorreto, uma operação errada etc. e levam à interrupção do programa.
- As informações geradas pelas exceções são somente as informações genéricas do Java, não sendo possível especificar os detalhes do erro.
As exceções podem devolver diversas mensagens de erro, como as informações da pilha de execução quando ocorreu o erro, os erros que aconteceram, ou é possível o desenvolvedor personalizar a mensagem de erro para apresentar para o usuário uma informação mais polida e menos técnica.
Indicação de leitura
Nome do livro:: Programação Orientada a Objetos com Java. Uma introdução prática usando o BlueJ
Editora:: Pearson - Prentice Hall
Autor:: David J. Barnes e Michael Kölling
ISBN:: 857605012-9
Comentário: O livro apresenta muitos exemplos práticos acerca de diversos temas do Java, principalmente em relação ao Tratamento de Exceções, que pode ser um assunto complexo, referente às hierarquias e a como realizar o tratamento em um sistema que será utilizado por um usuário final.