Conceitos Iniciais sobre Linguagem de programação C
Em nosso cotidiano, utilizamos diversos softwares e aplicativos para nos auxiliar em nossas atividades, sendo eles programas de gestão empresarial conhecidos como ERP (Enterprise Resource Planning ou, na tradução literal, Planejamento dos Recursos da Empresa), sistemas bancários, aplicativos de celular, entre diversos outros. Esses softwares ou programas (como alguns os conhecem) são desenvolvidos através de linguagens de programação.
1159 Linguagem de Programação C Fonte: SCANDINAVIANSTOCK, 123RF.
Podemos definir que as linguagens de programação são instruções, sendo elas um conjunto de palavras, compostas por comandos e regras que dão origem ao código fonte do programa. Após a construção do código fonte, ele é interpretado e executado pelo processador do computador ou do celular.
Encontramos hoje à disposição diversas linguagens de programação como JAVA, Python, PHP, Visual Basic, Delphi, C#, entre outras, o que define qual a melhor linguagem a se utilizar é qual aplicação ou programa será efetuado. Muitas dessas linguagens têm suas instruções iguais ou parecidas, através da linguagem de programação C, podemos compreender como são os códigos fontes de um programa de uma forma simples e prática.
O que é a linguagem de programação C
A linguagem de programação C teve seu início na década de 70, e Dennis Ritchie foi o responsável por inventá-la e implementá-la nos laboratórios Bell da companhia AT & T. A linguagem C teve influência direta da linguagem chamada B, inventada por Ken Thompson, destinada inicialmente apenas para sistemas operacionais UNIX até ganhar espaço entre os desenvolvedores e sistemas.
Com a popularidade dos microcomputadores, um grande número de implementações de C foi criado. Quase por milagre, os códigos-fontes aceitos por essas implementações eram altamente compatíveis. (Isto é, um programa escrito com um deles poderia normalmente ser compilado com sucesso usando-se um outro) (SHILDT, 1997, p.3).
A linguagem C se utiliza de uma sintaxe muito simples e compacta, parte de sua popularidade se dá também pelas combinações de diferentes funções, além de não estar vinculada a qualquer tipo de sistema ou hardware específico, por isso, pode ser compilada com sucesso por vários sistemas e também ser executada por qualquer computador que tenha suporte à linguagem.
Essa linguagem é classificada como nível médio, mas isso não significa que ela não é poderosa, Shildt (1986, p.1) afirma que “Uma linguagem de nível médio fornece aos programadores um conjunto mínimo de declarações de controle e manipulação de dados, que eles poderão utilizar para definir construções de alto nível”. A linguagem C serve como apoio para diversas linguagens de alto nível, como PASCAL ou BASIC, podendo também ser facilmente convertida para algum tipo de linguagem de alto nível.
Fique por dentro
Linguagens de Baixo, Médio e Alto Nível
- Linguagens de baixo nível são códigos executados diretamente pelo computador, conhecidas também por linguagem binária, pois é composta por 0 e 1.
- Linguagens de médio nível são utilizadas para escrever programas com base em sua linguagem, podem ser procedimental ou não procedimental.
- Linguagens de alto nível são linguagens que se aproximam da linguagem humana.
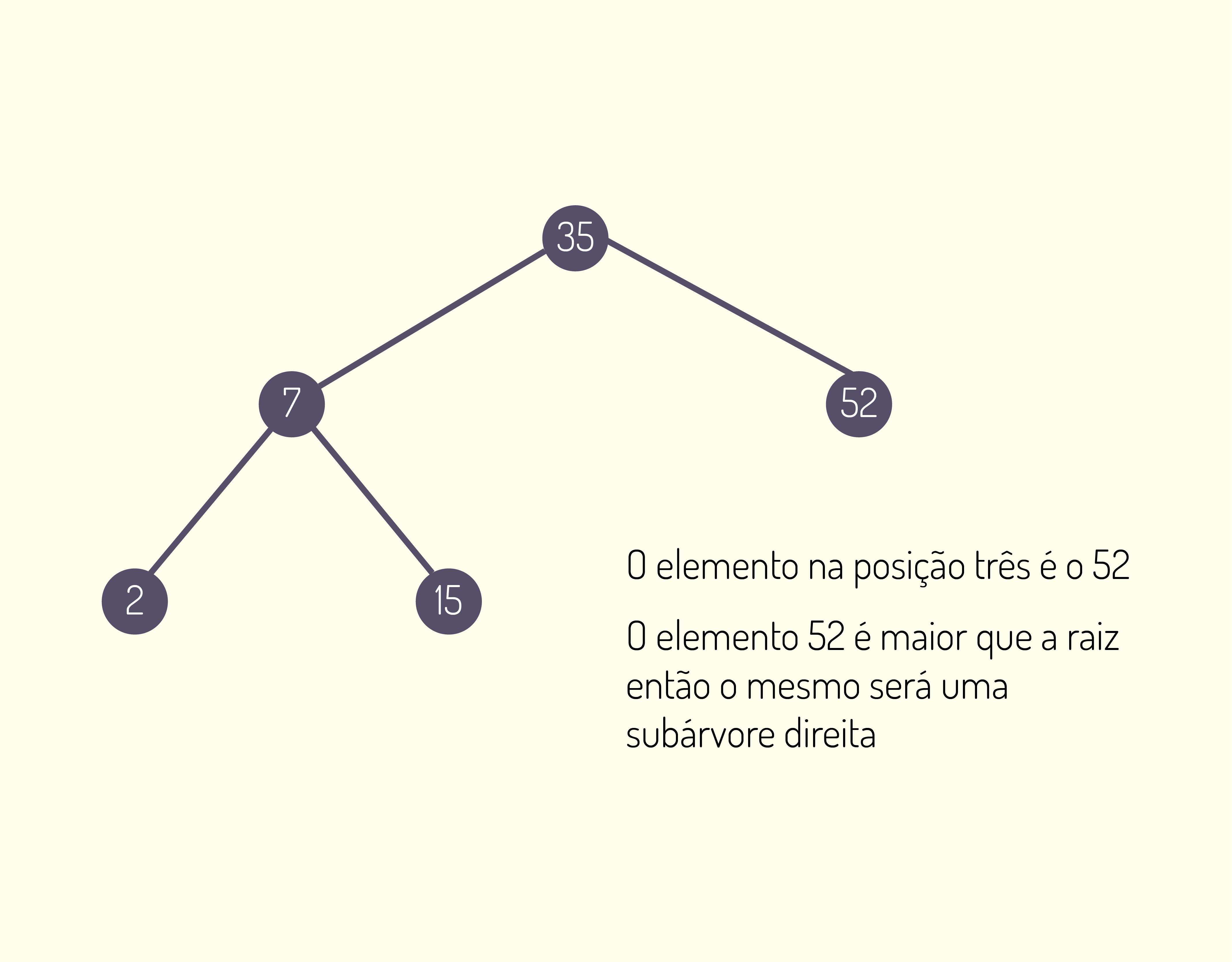
Linguagens de computação em níveis
Fonte adaptado de Schildt (1986).
|
Baixo Nível
|
Médio Nível
|
Alto Nível
|
|
Macro-assembler
Assembler
|
C
C++
FORTH
|
Ada
Modulo-2
Pascal
COBOL
FORTRAN
BASIC
|
Estrutura do arquivo de linguagem de programação C
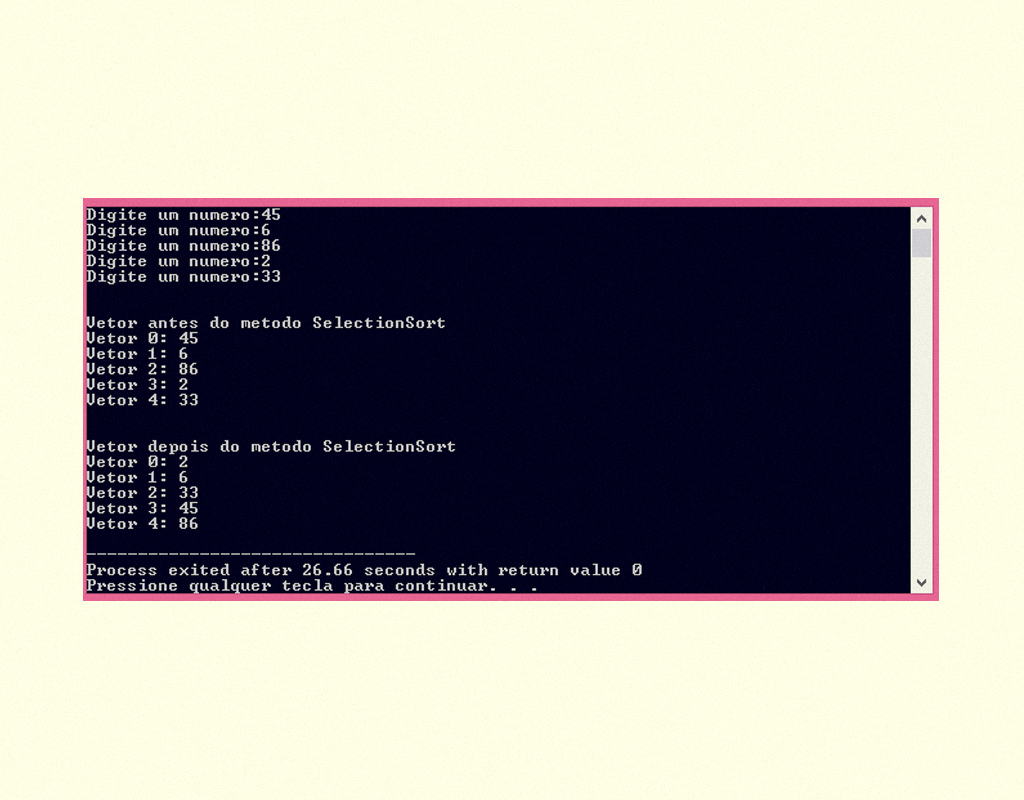
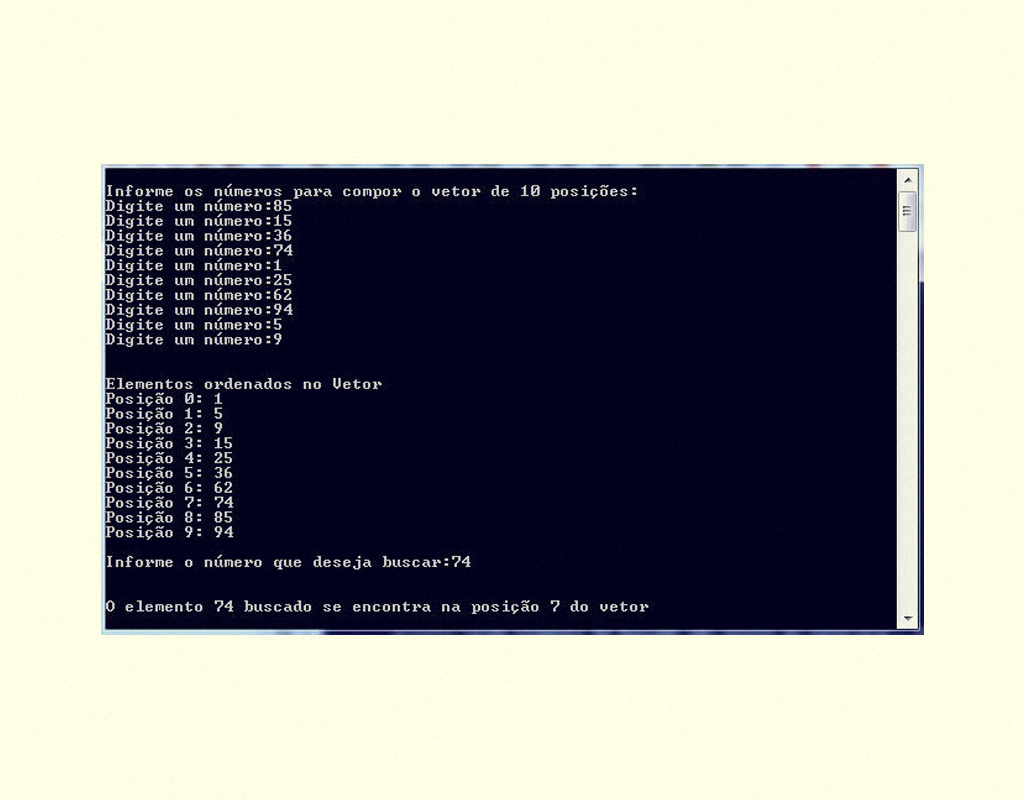
O desenvolvimento de um programa em linguagem C se inicia com a escrita do código fonte por meio de um editor e termina na compilação do código, gerando um programa executável, alguns dos principais compiladores são: GCC, Dev C++, C++ Builder, Turbo C e Visual C#. Não se preocupe, pois o código fonte não se altera independentemente do compilador escolhido. Para compreendermos melhor vamos construir nosso primeiro programa em C, como na Figura 1.2.
1259 Meu Primeiro programa em C Fonte: Dev-C ++.
Prezado(a) aluno(a), fique tranquilo, pois vamos analisar cada linha de nosso código.
Ele se inicia com a função #include , na qual estamos incluindo a biblioteca stdio.h, em que há declarações de funções para a manipulação das entradas e saídas. Por isso, não podemos esquecer de utilizá-la em nossos programas. Logo abaixo, temos a função main(){ ... }, que é a primeira a ser executada quando o programa é executado, é nesse local que todo o nosso bloco de códigos é inserido. Dentro da função main(), temos a função printf(), esta faz que os elementos sejam impressos na tela tela do computador.
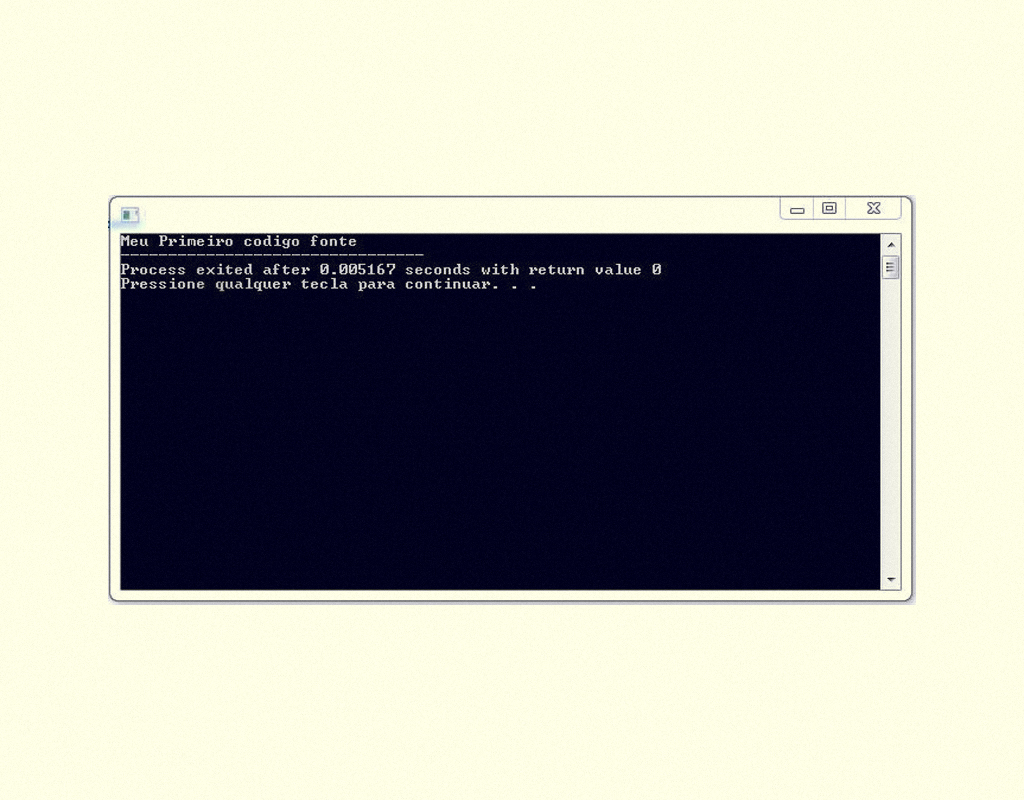
Após a compilação do código fonte, podemos executá-lo e o resultado será o apresentado na Figura 1.3.
1359 Programa “meu primeiro código” em execução Fonte: Dev-C ++
Podemos compreender que a estrutura básica de um código fonte desenvolvido em linguagem C deve conter elementos básicos como:
1459 Estrutura código em linguagem C Fonte: Dev-C ++.
Variáveis
Para que possamos efetuar a manipulação de dados, devemos utilizar variáveis. Mas o que é uma variável, afinal? Segundo Mizrahi (2008, p. 13):
As variáveis são o aspecto fundamental de qualquer linguagem de computador. Uma variável em C é um espaço de memória reservado para armazenar um certo tipo de dado e tendo um nome para referenciar o seu conteúdo. [...] uma variável é um espaço de memória que pode contar, a cada tempo, valores diferentes.
Para utilizar as variáveis, devemos declará-las no bloco de códigos, sendo necessário informar o seu tipo e um nome de referência, o espaço de memória a ser reservado é determinado com base no tipo da variável, podendo ser dados números ou caracteres (strings).
Vejamos na Figura 1.5 como efetuar a declaração de variáveis:
1559 Estrutura de declaração de variáveis Fonte: Dev-C ++.
Quando temos diversas variáveis com o mesmo tipo, podemos declarar todas na mesma linha separando apenas por uma vírgula, conforme a Figura 1.6:
1659 Declaração de variáveis Fonte: Dev-C ++.
Um ponto muito importante na declaração de uma variável é que os nomes de referência não podem começar com números, não podem conter caracteres especiais ou espaços. Veja no Quadro 1.1 algumas variáveis declaradas de modo incorreto:
|
Declaração de variável
|
|
|
int 1numero;
int 55ponto, 53ponto;
char 1nome;
char 1lugar, 2lugar;
|
Variáveis declaradas de modo incorreto, pois o nome de referência se inicia com número.
|
|
int número;
int número, código;
char endereço;
char endereço, município;
|
Variáveis declaradas de modo incorreto,pois o nome de referência contém caracteres especiais.
|
|
int número de telefone;
int número de telefone, código do produto;
char primeiro nome;
char primeiro nome, endereço residencial;
|
Variáveis declaradas de modo incorreto, pois o nome de referência contém caracteres especiais e espaços.
|
119 Declaração de variáveis de modo incorreto Fonte: o autor.
Vejamos no Quadro 1.2 como é possível declarar as variáveis anteriormente informadas de modo correto:
|
Declaração de variável
|
|
|
int numero1;
int ponto55, ponto55;
char nome1;
char lugar1, lugar2;
|
Variáveis declaradas de modo correto, pois o nome de referência não se inicia com número.
|
|
int numero;
int numero, codigo;
char endereco;
char endereco, municipio;
|
Variáveis declaradas de modo correto, pois o nome de referência não contém caracteres especiais.
|
|
int numero_de_telefone;
ou
int numerodetelefone;
int numero_de_telefone, codigo_do_produto;
char primeiro_nome;
char primeiro_nome, endereco_residencial;
|
Variáveis declaradas de modo correto, pois o nome de referência não contém caracteres especiais ou espaços (podemos substituir os espaços por underline).
|
129 Declaração de variáveis de modo correto Fonte: o autor.
Tipos de Variáveis
Na linguagem C, os tipos de variáveis mais utilizados são: char, int, float, double, enum e pointer.
O tipo char é um string (composto por caracteres), podendo conter palavras e números. O tipo int é numérico inteiro, armazena apenas números não fracionários. O tipo float é numérico de ponto flutuante, aceitando números decimais e fracionários. O tipo double é de ponto flutuante de precisão dupla, muito parecido com o float, mas apresenta maior capacidade de armazenamento. O tipo enum representa um lista predefinida pelo desenvolvedor. O tipo pointer é um tipo especial, pois não armazena dados, mas sim a localização na memória de um dado real.
|
TIPO
|
Dados aceitos
|
Tamanho em Bytes
|
|
char
|
letras, caracteres especiais e números
|
1
|
|
int
|
números inteiros de -32767 até 32767
|
2
|
|
float
|
números decimais de -3.4 x 1038 até +3.4 x 10-38, até 6 dígitos
|
4
|
|
double
|
números decimais de -1.7 x 10308 até +1.7 x 10+308 até 10 dígitos
|
8
|
139 Tipos de variáveis Fonte: o autor.
Reflita
Ao analisarmos os tipos de variáveis, é possível compreender que cada dado terá uma declaração específica. Quando não sabemos quais serão as informações a serem manipuladas, podemos dizer que será mais seguro se todos os tipos de variáveis sejam char?
Nesse caso, tenha como base a informação de que esse tipo de variável aceita letras, caracteres especiais e números.
Conforme informado anteriormente, A declaração de variáveis também pode ocorrer entre o #include e a função main(). Veja na Figura 1.7 como é possível efetuar esse procedimento.
1759 Declaração de variáveis no corpo do código fonte Fonte: Dev-C ++.
Palavras Reservadas
Todos os tipos de linguagens têm palavras reservadas, elas não podem ser utilizadas para declaração de variáveis, funções ou na manipulação de dados. Cada palavra reservada representa um conjunto de condições e tem seu uso específico. Na linguagem C, podemos citar como exemplo as palavras: operator, case, void, return. Ao todo, na linguagem C, temos 32 palavras chaves, no Quadro 1.4, são apresentadas algumas delas:
|
PALAVRAS RESERVADAS
|
|
asm
|
template
|
do
|
register
|
|
catch
|
this
|
double
|
return
|
|
class
|
virtual
|
else
|
short
|
|
delete
|
_cs
|
enum
|
signed
|
|
_export
|
_ds
|
extern
|
sizeof
|
|
friend
|
_es
|
far
|
static
|
|
inline
|
_ss
|
float
|
struct
|
|
_loadds
|
auto
|
for
|
switch
|
|
new
|
break
|
goto
|
typedef
|
|
operador
|
case
|
huge
|
union
|
|
private
|
catch
|
if
|
unsigned
|
|
protected
|
cdecl
|
int
|
void
|
|
public
|
char
|
interrupt
|
volatile
|
|
_regparam
|
const
|
long
|
while
|
|
_saveregs
|
continue
|
near
|
|
|
_seg
|
default
|
pascal
|
|
149 Palavras reservadas da linguagem C Fonte: Pappas e Murray (1991).
Entrada e Saída de Dados
Um dos objetivos principais de um programa, sendo ele em C ou qualquer outra linguagem, é a manipulação de informações, esse processo se inicia com a entrada de dados, os quais podem ser variáveis predefinidas no programa ou conteúdo digitado pelo usuário. A linguagem C utiliza a função scanf() para obter os dados digitados pelo usuário no programa.
A função scanf() permite que um valor seja lido do teclado e armazenado numa variável. Sua sintaxe consiste numa cadeia de formatação seguida de uma lista de argumentos, cada um deles sendo o endereço de uma variável .(PEREIRA, 2001, p.6)
1859 Lendo dados com a função scanf() Fonte: Pereira (2001, p. 6).
Observe que, para efetuar a leitura da entrada de dados, à frente do nome da variável, temos o caractere & (e comercial ), em que se faz a indicação do espaço reservado na memória, sem o caractere o valor não é atribuído para a variável. Esse caractere é utilizado apenas na entrada de dados, para utilizar a variável em outras partes do código fonte, não é necessário utilizá-lo.
Ao efetuar a leitura de dados, temos uma formatação específica para cada tipo de variável, no exemplo apresentado, estão sendo utilizadas duas variáveis de tipos diferentes: %d manipula dados inteiros, e %c está manipulando dados de um string. No Quadro 1.5, podemos verificar outros tipos de formatação.
|
Expressão
|
Formatação aceita
|
|
%d
|
Número decimal inteiro.
|
|
%c
|
Único caractere.
|
|
%u
|
Decimal sem sinal.
|
|
%i
|
Decimal inteiro.
|
|
%e
|
Número em ponto flutuante com sinal opcional.
|
|
%f
|
Número em ponto flutuante com ponto opcional.
|
|
%g
|
Número em ponto flutuante com expoente opcional.
|
|
%p
|
Ponteiro.
|
|
%s
|
String.
|
|
%o
|
Número em base octal.
|
|
%x
|
Número em base hexadecimal.
|
159 Expressão para manipulação de tipos de variáveis Fonte: o autor.
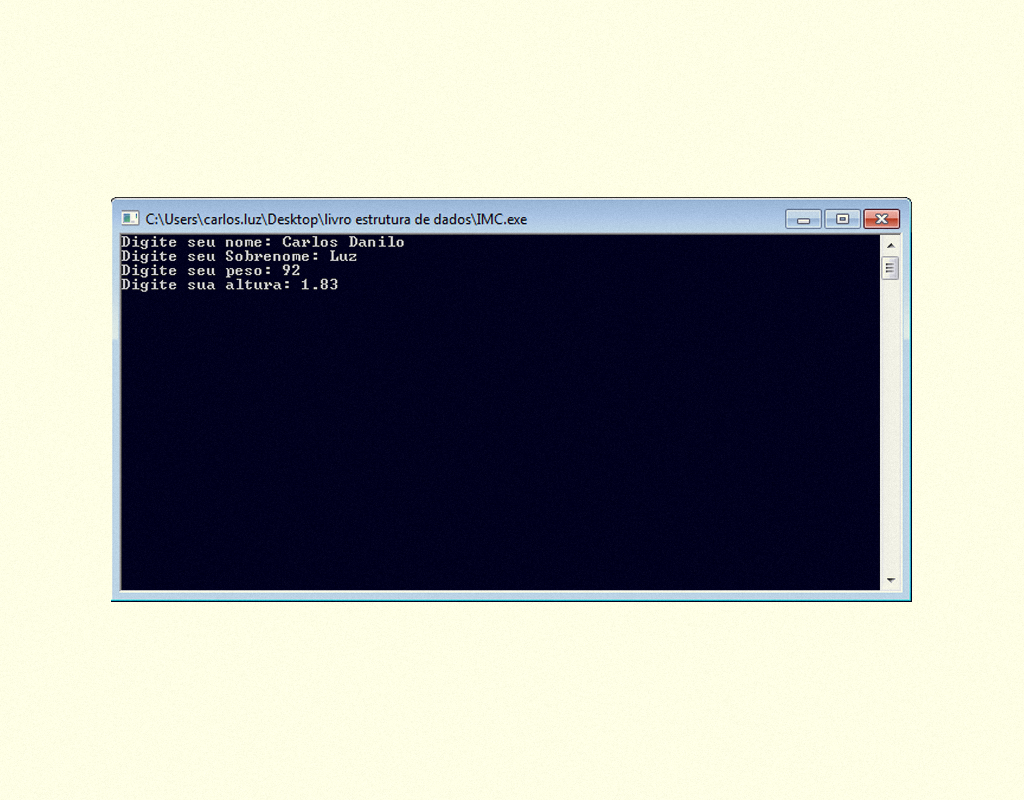
Para compreendermos melhor a utilização dessa função, vejamos o código fonte apresentado na Figura 1.9.
1959 Código fonte, leitura de variáveis Fonte: Dev-C ++.
Após compilar o código fonte e executar o programa, o usuário irá digitar o que é requisitado, conforme Figura 1.10.
11059 Resultado do código fonte, sobre leitura de variáveis Fonte: Dev-C ++.
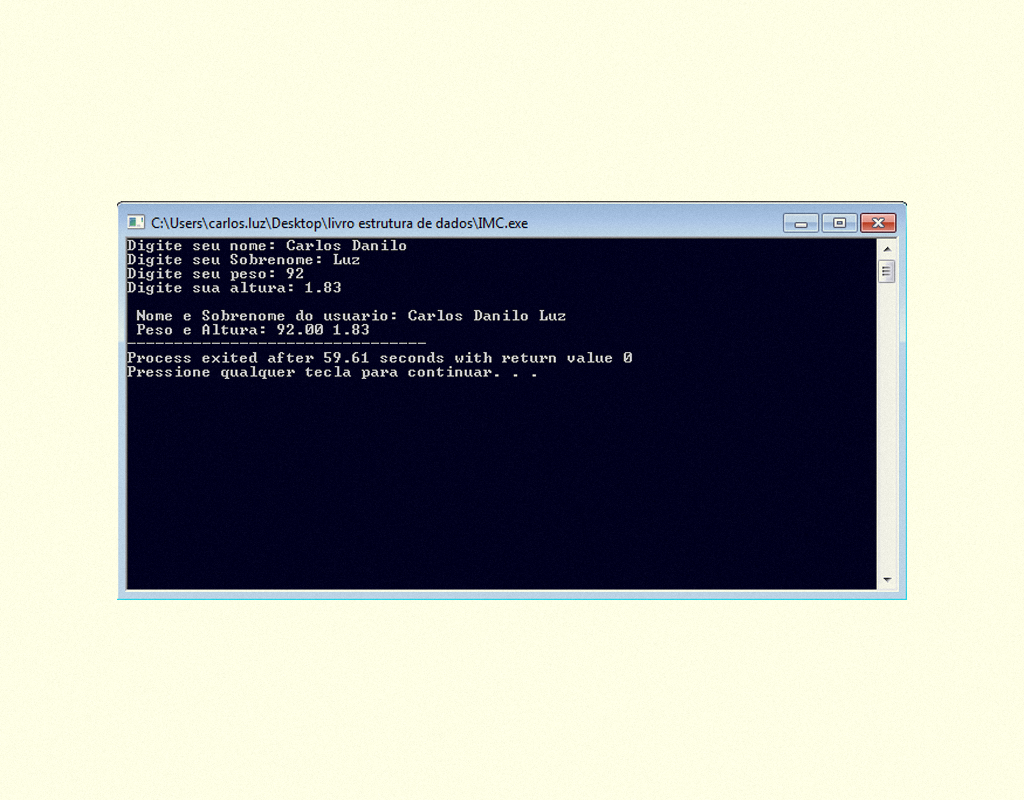
A saída de dados ou impressão na tela, como já foi citado anteriormente, se utiliza a função printf( ). Pereira (2001) afirma que “a função printf( ) nos permite exibir informações formatadas no vídeo. A sua sintaxe é essencialmente idêntica àquela da função scanf().” Podemos compreender que as expressões de entrada de dados (%d, %f, %s) são utilizadas em ambas as funções, conforme apresentado na Figura 1.11.
11159 Código fonte com itens de leitura e escrita em linguagem C Fonte: Dev-C ++.
Resultado do programa em execução:
11259 Resultado do código fonte, sobre leitura e escrita Fonte: Dev-C ++
Expressões e Operadores
A linguagem C se utiliza de um conjunto de expressões e operadores para efetuar funções matemáticas ou relacionais, são usados vários caracteres especiais para representação.
No Quadro 1.6, são apresentados os operadores aritméticos em C.
|
Operador
|
Exemplo
|
Comentário
|
|
=
|
x = y
|
O conteúdo da variável Y é atribuído à variável X (a uma variável pode ser atribuído o conteúdo de outra, um valor constante ou, ainda, o resultado de uma função).
|
|
+
|
x + y
|
Soma o conteúdo de X e de Y.
|
|
-
|
x - y
|
Subtrai o conteúdo de Y do conteúdo de X.
|
|
*
|
x * y
|
Multiplica o conteúdo de X pelo conteúdo de Y.
|
|
/
|
X / y
|
Obtém o quociente de divisão de X por Y.
Se os operadores são inteiros, o resultado da operação será o quociente inteiro da divisão.
Se os operadores são reais, o resultado da operação será a divisão.
Por exemplo:
int z = 5/2: a variável z receberá o valor 2
float z = 5/2: a variável z receberá o valor de 2,5
|
|
%
|
x % y
|
Obtém o resto da divisão de X por Y.
|
169 Operadores aritméticos em C Fonte: Ascencio e Campos (2012 p. 29).
Expressões relacionais referem-se a comparações ou validações entre dois dados e se utilizam de símbolos próprios. Através do Quadro 1.7, podemos compreender essas expressões:
|
Operador
|
Exemplo
|
Comentário
|
|
==
|
X == Y
|
O conteúdo de X é igual ao conteúdo de Y.
|
|
!=
|
X != Y
|
O conteúdo de X é diferente do conteúdo de Y.
|
|
<=
|
X <= Y
|
O conteúdo de X é menor ou igual ao conteúdo de Y.
|
|
>=
|
X >= Y
|
O conteúdo de X é maior ou igual ao conteúdo de Y.
|
|
<
|
X < Y
|
O conteúdo de X é menor que o conteúdo de Y.
|
|
>
|
X > Y
|
O conteúdo de X é maior que o conteúdo de Y.
|
179 Expressões de comparação Fonte: Ascencio e Campos (2012 p.30).
Os operadores matemáticos de atribuição são utilizados para representar de maneira sintética uma operação aritmética e, posteriormente, uma operação de atribuição (ASCENCIO; CAMPOS, 2012 p.29). Esses operadores são uma combinação das expressões aritméticas e relacionais, veja-os descritos no Quadro 1.8:
|
Operador
|
Exemplo
|
Comentário
|
|
+=
|
X += Y
|
Equivalente a X = X + Y
|
|
-=
|
X -= Y
|
Equivalente a X = X - Y
|
|
*=
|
X *= Y
|
Equivalente a X = X * Y
|
|
/=
|
X /= Y
|
Equivalente a X = X / Y
|
|
%=
|
X %= Y
|
Equivalente a X = X % Y
|
|
++
|
X++
|
Equivalente a X = X +1
|
|
++
|
Y = ++ X
|
Equivalente a X = X + 1 e depois Y = X
|
|
++
|
Y = X++
|
Equivalente a Y = X e depois X = X + 1
|
|
--
|
X--
|
Equivalente a X = X -1
|
|
--
|
Y = -- X
|
Equivalente a X = X -1 e depois Y = X
|
|
--
|
Y = X --
|
Equivalente a Y = X e depois X = X -1
|
189 Operadores Matemáticos de combinações Fonte: Ascencio e Campos (2012, p. 29).
Fique por dentro
Em linguagem C, para atribuir um dado/valor a uma variável, se utiliza apenas um igual =, ao efetuarmos uma comparação entre dois valores/dados, utilizamos dois iguais ==, esse conceito se aplica para as demais linguagem de programação conhecidas.
A linguagem C oferece operadores lógicos, que podem ser usados para formar condições mais complexas ao combinar condições simples. Os operadores lógicos são && (AND lógico), II (OR lógico) e !(NOT lógico, também chamado de negação lógica) (DEITEL; DEITEL. 2011 p.95).
O retorno de uma expressão lógica é verdadeiro ou falso, tendo como base a tabela verdade utilizada em matemática para computação. No quadro 1.9 são descritos os operadores lógicos:
|
Operadores
|
Tipo
|
|
< <= > >=
|
Relacional
|
|
== !=
|
Igualdade
|
|
&&
|
AND lógico
|
|
||
|
OR lógico
|
|
?:
|
condicional
|
|
= += -= *= /= %=
|
Atribuição
|
199 Operadores Lógicos Fonte: adaptado de Deitel e Deitel (2011, p.97).
Atividades
As entradas de dados são informações atribuídas pelo usuário, é reservado um espaço na memória por intermédio da declaração de variáveis. A linguagem C possui tipos específicos como char, int, float, entre outros, se a variável for declarada de modo errado, o programa apresentará erros. Sobre a forma de declarar as variáveis, assinale a alternativa incorreta de como efetuar esse processo.
- char nome, telefone; float altura1; int numero1.
Todas as declarações estão corretas, o telefone pode ser descrito como caracteres já que o tipo char aceita números e strings.
- float peso, altura; char nome[20], curso[20]; int rg, cpf, codigo_pessoa.
Todas as declarações estão corretas, podemos declarar mais que uma variável do mesmo tipo na mesma linha. Pode-se estipular a quantidade de caracteres de uma string (nome[20]). É possível declarar vários itens, em vez de utilizar espaço foi atribuído o underline.
- int numero, 1lugar; float peso; char nome completo, preço.
O nome da variável não pode começar com números (1lugar), também não é possível que o nome da variável contenha espaços (char nome completo)
- float Preco, ValorTotal; int QTDETotal, Unidade; char Cliente, fornecedor.
odas as declarações estão corretas. É aceitável utilizar letras maiúsculas ou minúsculas para declarar as variáveis.
- int posicao; char local; float comprimento.
Todas as declarações estão corretas, respeitando os critérios básicos.
Instruções Condicionais e de Repetição
As expressões condicionais fazem o tratamento dos dados inseridos pelo usuário, efetuando comparações ou validações, de forma que o programa execute parte do código ou não.
Uma das tarefas fundamentais de qualquer programa é decidir o que deve ser executado e seguir. Os comandos de decisão permitem determinar qual é a ação a ser tomada com base no resultado de um expressão condicional. Isso significa que podemos selecionar entre ações alternativas, dependendo de critérios desenvolvidos no decorrer da execução do programa (MIZRAHI, 2008 p.84)
Vamos estudar três tipos expressões:
- Simples (if).
- Composta (if-else).
- Múltipla Escolha (switch-case) .
Em conjunto com as expressões condicionais, temos as estruturas de repetição, também chamadas de laços, essas são utilizadas quando temos que efetuar várias entradas de dados ou executar condições.
Uma estrutura de repetição permite que você especifique que uma ação deverá ser repetida enquanto alguma condição permanecer verdadeira (DEITEL, 2011 p.52). Pode-se compreender como expressão verdadeira os exemplo de laços:
- FOR: faça a repetição enquanto não tiver o nome de 10 alunos.
- WHILE: irá fazer uma comparação para iniciar o laço, se não tiver os nomes dos aluno, caso iniciado o laço, só termina se tivermos os 10 nomes.
- DO - WHILE: executa o laço pelo menos uma vez, após iniciado só para se obter os 10 nomes de alunos.
No decorrer desta unidade, vamos compreender melhor cada um dos tipos de laços de repetição.
Instrução Condicional Simples
A expressão condicional simples efetua a comparação entre os dados informados pelo usuário para assim tomar uma decisão. De modo que, se a condição retornar verdadeira, o bloco de código é executado.
11359 Comando condicional simples Fonte: o autor.
Para que o código seja executado após a tomada de decisão, ele deve estar entre { ... }. A primeira chave, este símbolo { , marca o início do código e, após ela, todos comandos serão executados, o término da condição é identificado por uma segunda chave que fecha o código, com este símbolo: }. Toda estrutura condicional tem seu começo, meio e fim. Caso a condição seja falsa, o bloco de código não será executado.
11459 Limitações de execução Fonte: DEV C ++.
Ao analisarmos o código fonte, podemos compreender que, se o usuário informar que sua idade é de até 39 anos, o programa imprime na tela a frase “Voce e Jovem !”, pois a condição é verdadeira, caso o usuário tivesse digitado 41, não seria impresso nada na tela. Podemos utilizar expressões e operadores para efetuar a comparação de duas ou mais condições, tendo como base a tabela verdade. A estrutura do comando continua a mesma, apenas inserindo operadores da tomada de decisão, podemos também ter no mesmo código várias condições se utilizando da mesma variável para a tomada de decisão.
11559 Exemplo de comando com duas condicionais Fonte: DEV C ++.
Ao executar o programa, é possível tomar duas decisões, com base na idade informada, se utilizando de instruções condicionais simples, expressões e operadores.
Fique por dentro
Para efetuar as comparações de mais elementos na mesma condicional, utilizamos como base o conceito de tabela verdade.
Fonte o autor.
|
TABELA VERDADE
|
|
Objeto A
|
Objeto B
|
A e B
|
A ou B
|
|
Verdadeiro
|
Verdadeiro
|
Verdadeiro
|
Verdadeiro
|
|
Verdadeiro
|
Falso
|
Falso
|
Verdadeiro
|
|
Falso
|
Verdadeiro
|
Falso
|
Verdadeiro
|
|
Falso
|
Falso
|
Falso
|
Falso
|
Instrução Condicional Composta
A instrução condicional composta seria uma extensão da simples, pois temos a mesma base de estrutura de código, agora, caso a primeira condição não retornar verdadeira, o conteúdo é direcionado para a outra situação. Ao recordar do pseudocódigo, temos as expressões SE e SENÃO:
11659 Representação textual em pseudocódigo, sobre condicional composta Fonte: o autor.
O pseudocódigo apresentado, ao ser executado, efetua uma tomada de decisão sobre a nota de uma aluno, a qual se for maior ou igual que 7, torna verdadeira a condição, assim, será impresso na tela “Aprovado”, caso contrário, será impresso “Reprovado”. A estrutura do código em linguagem C segue o mesmo princípio desta expressão, dando continuidade à tomada de decisão simples:
11759 Código de exemplo condicional composta Fonte: DEV C ++.
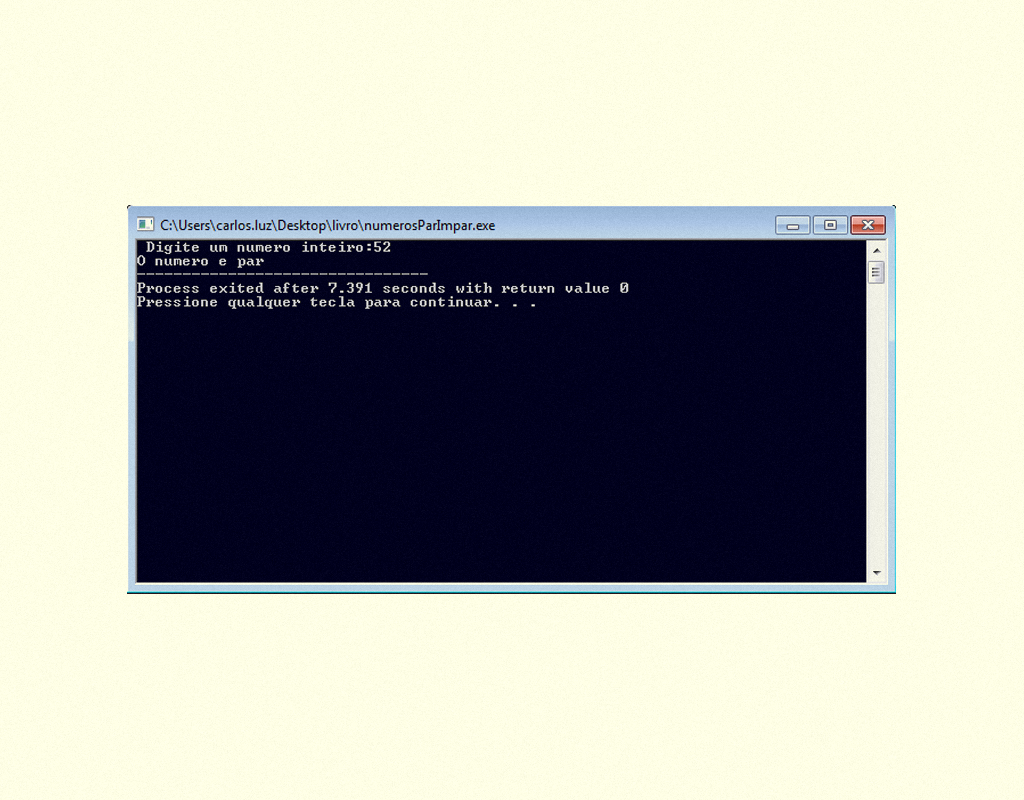
No Figura 1.18, temos o código fonte de um programa em C, em que o usuário informa um número e é retornado na tela se este é par ou ímpar, podemos utilizar a expressão % 2, na comparação do if, que retorna o resto da divisão, se o retorno for 0, ele é par, se não, é ímpar.
11859 Programa de exemplo com condicional composta Fonte: DEV C ++.
Ao executarmos o programa e inserirmos algum número, o programa efetua o procedimento e, assim, temos a seguinte resposta:
11959 Resultado do programa em execução, condicional composta Fonte: DEV C ++.
Instrução Condicional Múltipla Escolha
As estruturas condicionais simples e compostas são úteis em casos em que a tomada de decisão tem que escolher 2 caminhos, com base na expressão ou operador.
C tem um comando interno de seleção múltipla, switch, que testa sucessivamente o valor de uma expressão contra uma lista de constantes internas ou de caractere. Quando o valor coincide, os comandos associados àquela constante são executados. (SCHILDT, 1997 p. 70)
Podemos compreender que a linguagem C irá percorrer um lista de Case até encontrar a que seja a resposta de busca. Após encontrar a constante, o programa executa a sequência de código e, em seguida, a função break, que seria o comando de desvio sinalizando que o objeto já foi encontrado, não havendo mais a necessidade de continuar o switch case.
Pode-se utilizar o comando default, que é identificado como sendo a saída padrão, caso nenhum dos case atenda a necessidade, o bloco de código a ser executado será o pertencente ao default. Vamos ver como são escritos os comando em linguagem C:
12059 Composição do SWITCH CASE de forma textual Fonte: o autor.
Schildt (1997 p. 70-71) aponta três itens importantes sobre o switch-case:
O comando switch difere do comando if porque switch só pode testar igualdade, enquanto if pode avaliar uma expressão lógica ou relacional.
Duas constantes case no mesmo switch não podem ter valores idênticos. Obviamente, um comando switch incluído em outro switch mais externo pode ter as mesmas constantes case.
Se constantes de caractere são usadas em um comando switch, elas são automaticamente convertidas para seus valores inteiros.
Esses três pontos são as regras para se utilizar a instrução condicional case, para compreendermos melhor vamos analisar o código fonte a seguir:
12159 Código fonte de exemplo, utilizando SWITCH CASE Fonte: DEV C ++
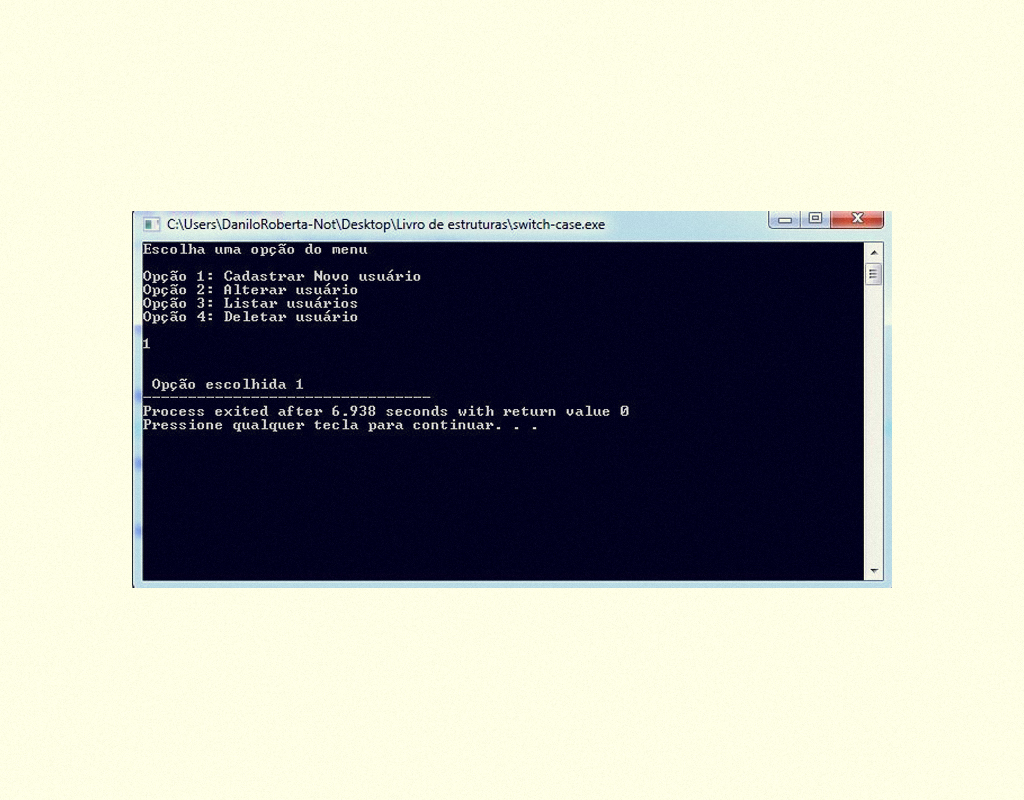
Ao compilarmos o código fonte apresentado, o usuário deverá digitar o número de uma opção (1, 2, 3, 4 ), em seguida, será executado o switch-case, efetuando as comparações. Caso a informação digitada seja compatível com alguma das opções, será impressa na tela a informação pertinente, caso não seja encontrada igualdade, a opção default será impressa na tela.
12259 Resultado do programa em execução Fonte: DEV C ++.
Estrutura de Repetição FOR
Em linguagem C e em todas as outras linguagens modernas de programação, os comandos de iteração (também chamados laços) permitem que um conjunto de instruções seja executado até que ocorra certa condição (SCHILDT, 1997, p.74).
Os laços de repetição efetuam as iterações até que uma condição seja atendida, no caso do comando for, é informado a variável de inicialização, a condição de iteração e o comando de incremento, cada item separado por ponto e vírgula - ;. Veja:
12359 Composição do comando FOR de modo textual Fonte: o autor
Prezado(a) aluno(a), veja que, como na instrução condicional, todo o código a ser executado pelo laço deve estar entre chaves, { ... }, pode-se efetuar o comando for sem elas quando tivermos apenas 1 linha do código a ser executado dentro do laço.
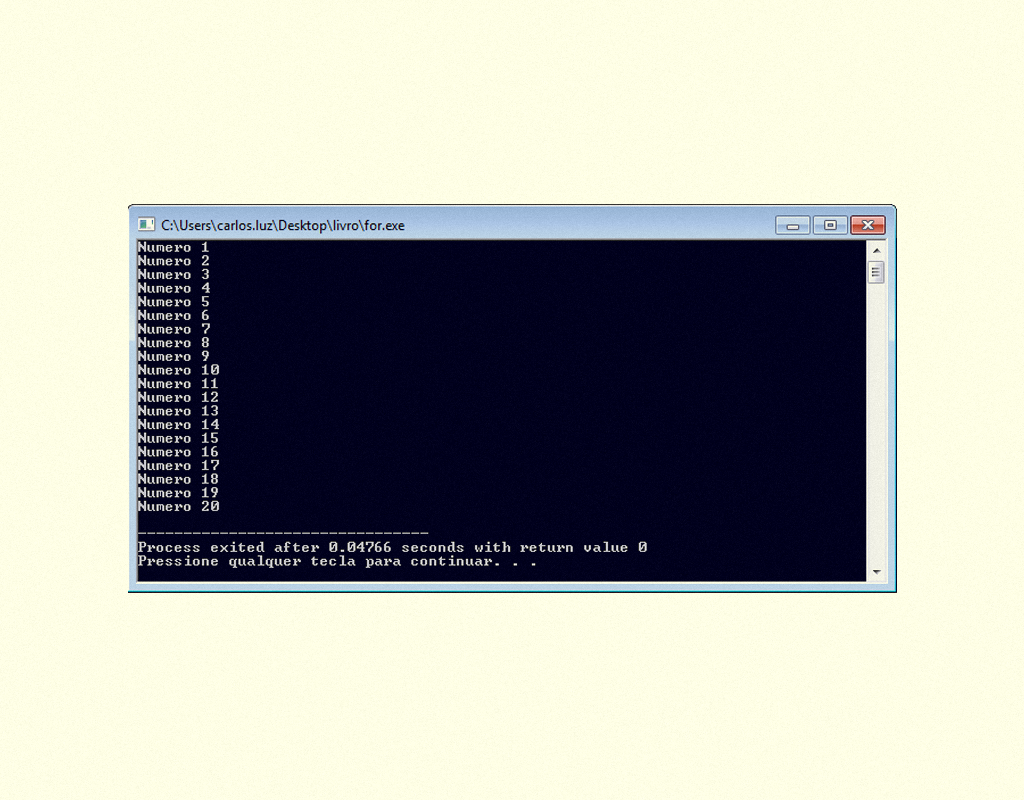
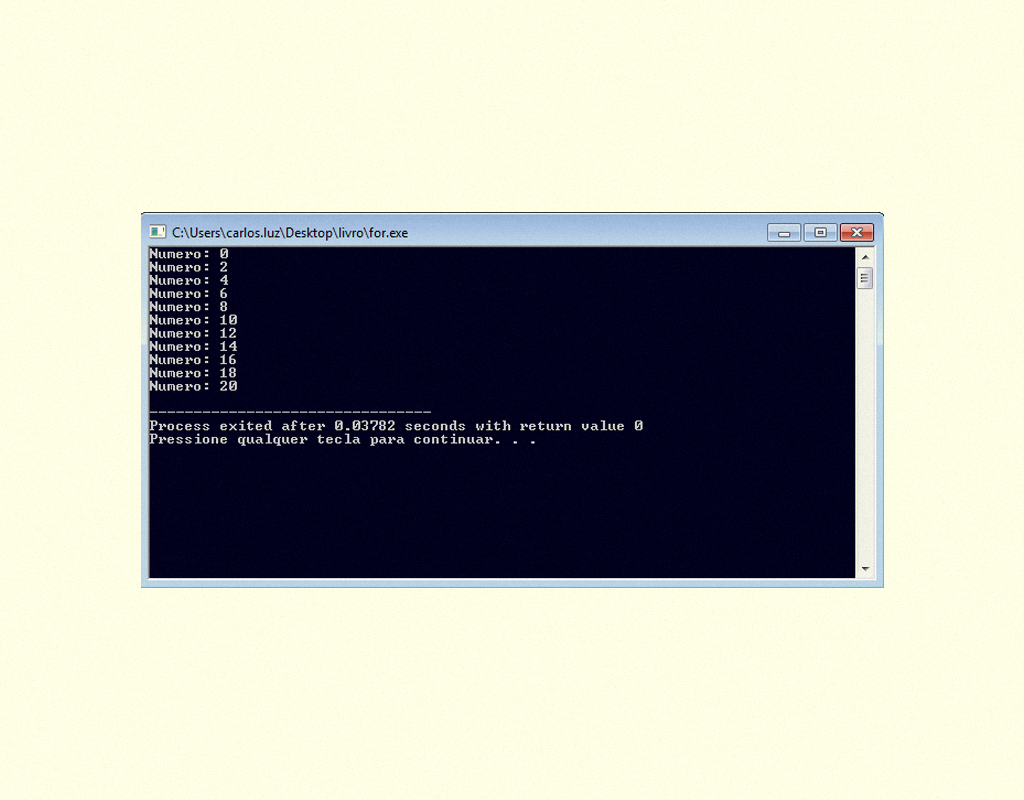
Para compreendermos melhor o laço de repetição for, observamos a Figura 1.24, na qual temos o código fonte de um programa em C que imprime na tela os números de 1 a 20.
12459 Exemplo do laço FOR Fonte: DEV C ++.
Veja o resultado do programa em C apresentado na Figura 1.24.
12559 Resultado do programa de exemplo FOR Fonte: DEV C ++.
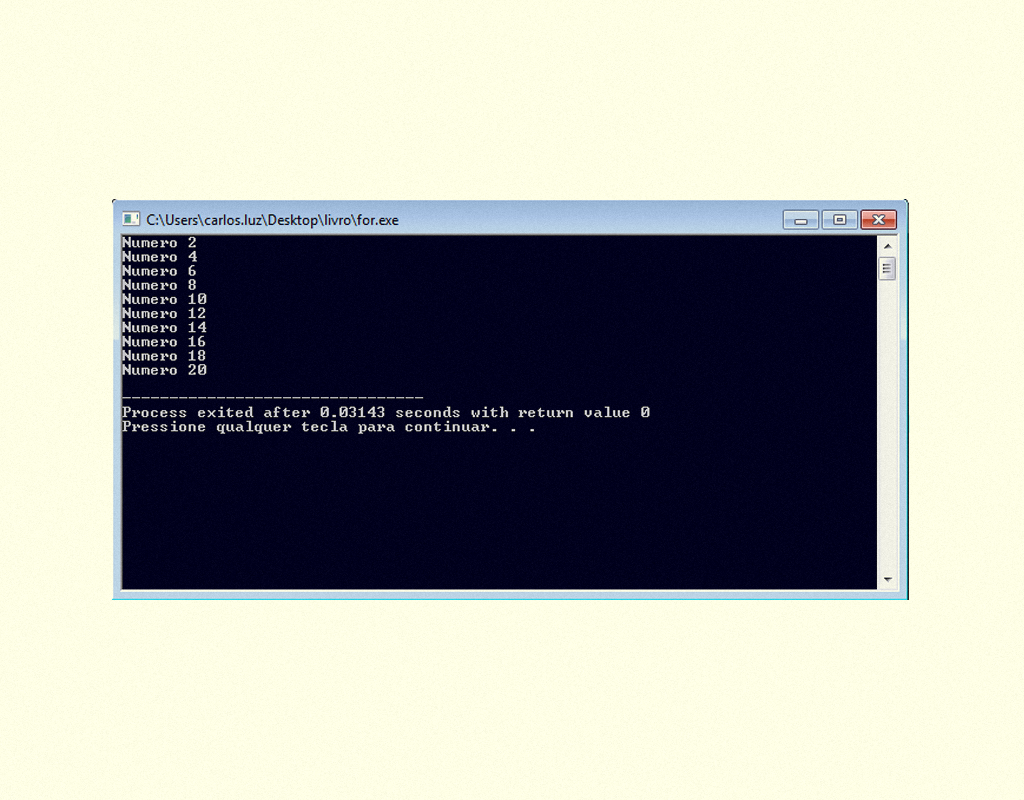
Podem-se utilizar várias funções e comandos em um laço de repetição, complementando o programa apresentado, vamos imprimir na tela agora somente os números que forem par:
12659 Exemplo de aplicação do FOR junto com outros comandos Fonte: DEV C ++
O resultado do programa em C apresentado na Figura 1.26.
12759 Resultado do exemplo FOR junto com os demais comandos Fonte: DEV C ++.
O que diferencia o laço for dos demais tipos é que determinamos a quantidade de iterações que ele deverá fazer no programa.
Estrutura de Repetição WHILE
O comando While também é um laço de repetição igual ao for e se diferencia por ser um tipo de laço condicional, ele se baseia em uma condição para efetuar a repetição.
O comando WHILE consiste na palavra-chave while seguida de uma expressão de teste entre parênteses. Se a expressão de teste for verdadeira, o corpo do laço é executado uma vez e a expressão de teste é avaliada novamente. Esse ciclo de teste e execução é repetido até que a expressão de teste se torne falsa (igual a zero), então o laço termina e o controle do programa passa para a linha seguinte ao laço . (MIZRAHI, 2008 p.73)
12859 Composição textual do laço While Fonte: o autor.
A forma de iteração do while é bem parecida com a do laço for, o que os diferencia é que o laço for efetua as x iterações pré-definidas, já o while, ao ser executado, pode parar as iterações a qualquer momento se a condição inicial for atendida.
12959 Exemplo de programa utilizando o laço While Fonte: DEV C ++.
O código fonte while apresentado efetua a mesma situação que o código for, o que o diferencia é que, antes de entrar no laço, é efetuada a consulta na condição, e ele valida a situação: se avariável i for menor ou igual a 20, o programa entra no laço while, a cada nova interação a função i++; incrementa um número na variável i.
O resultado do programa em C apresentado na Figura 1.29.
13059 Resultado do programa de exemplo WHILE Fonte: DEV C ++.
Estrutura de Repetição DO WHILE
A estrutura de repetição do... while é semelhante à estrutura while. Na instrução while, a condição da continuação de loop é testada no início do loop, antes que seu corpo seja executado. A estrutura do... while testa a condição da continuação do loop depois que o corpo do loop é executado. Portanto, o corpo do loop será executado pelo menos uma vez (DEITEL, DEITEL 2011 p.93).
Pode-se compreender que o laço de repetição DO... WHILE testa a condição no final no laço, dessa forma, ele efetua o loop pelo menos uma vez, sendo encerrado somente se a condição de saída retornar como verdadeira na condição.
Veja a sintaxe do laço de repetição:
13159 Composição textual do laço Do … While Fonte: Dev C ++.
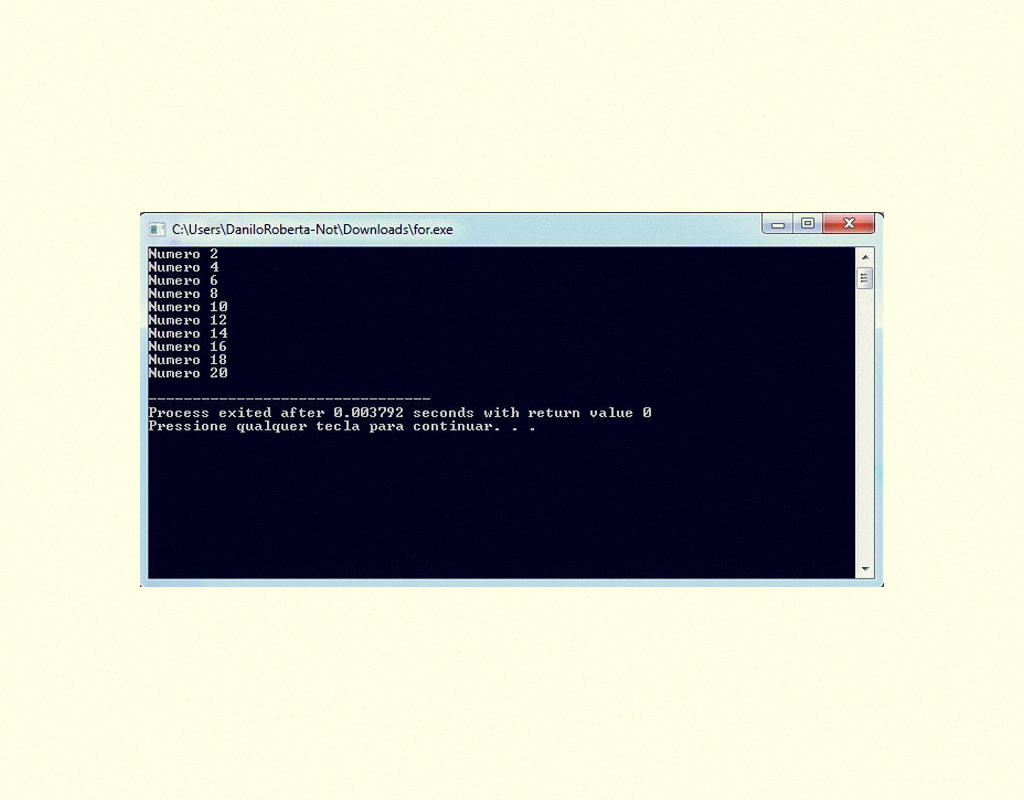
Ao apresentar a estrutura while, utilizamos um código fonte que efetuava um loop de 20 números e apresentava na tela apenas os números pares, podemos efetuar o mesmo laço de repetição com DO ... WHILE:
13259 Exemplo de de programa utilizando DO … WHILE Fonte: DEV C ++.
Veja o resultado do programa em C apresentado na Figura 1.32:
13359 Resultado do programa utilizando DO ... WHILE Fonte: DEV C ++.
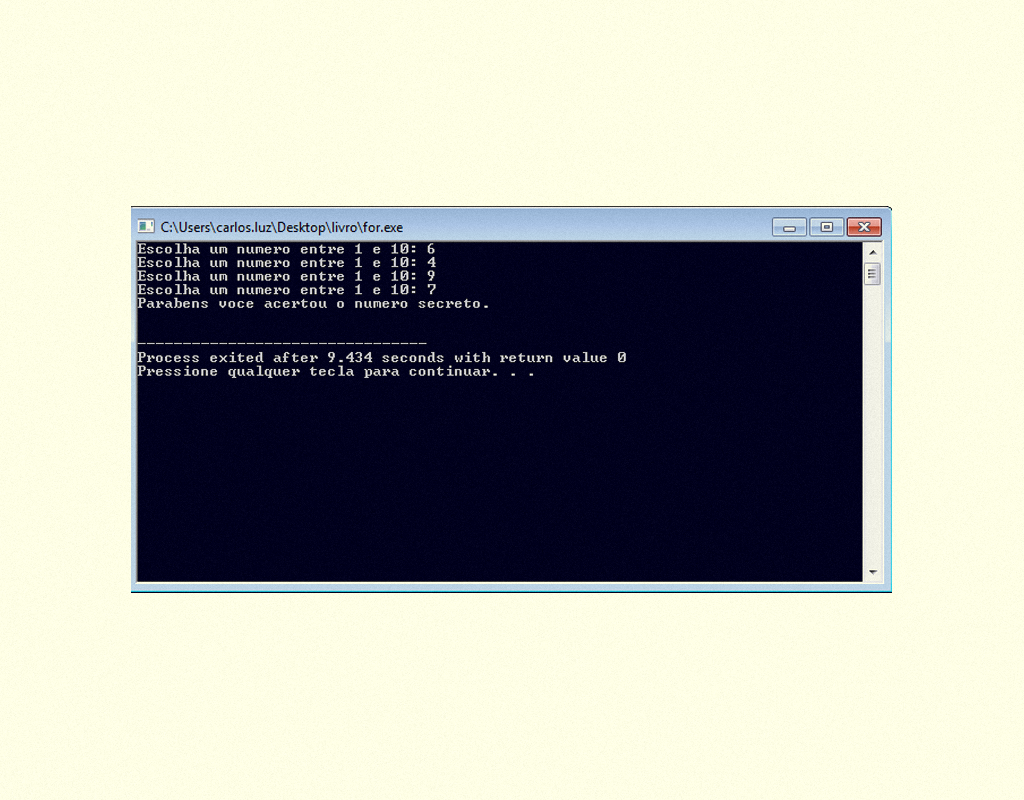
Podemos utilizar como condição de validação outros operadores além do >= ou <=, vejamos o código a seguir no qual o usuário deve descobrir qual o número secreto para poder sair do laço de repetição e concluir a execução do programa:
13459 Exemplo 2 utilizando DO ... WHILE Fonte: DEV C ++.
Resultado do programa em C apresentado na Figura 1.34.
13559 Resultado do exemplo 2 utilizando DO ... WHILE Fonte: DEV C ++
Atividades
As instruções condicionais tem como objetivo tomar uma decisão caso a condição seja verdadeira, para testar a condição, pode-se utilizar expressões ou operadores. Assinale a alternativa correta sobre a instrução condicional IF:
- if ( i >= j ) { printf(“ 1º número é maior que o 2º ”); }
Todas as condições atendem as restrições.
- if ( ) k == o { printf(“ Produto já existente”); }
Incorreta, pois a condição para a tomada de decisão deve estar entre ( … )
- if ( nome1 igual nome2) { printf(“ cliente já cadastrado ”); }
Incorreta, pois o operador igual não existe, o correto para esse tipo de verificação é ==
- if ( celular != telefone && comercial != telefone) { } printf(“telefones diferentes”);
Incorreta, pois o bloco de código deve estar estar entre { … }
- if ( opcao1 == opcao2 and opcao3 != opcao1 ) { prinf(“opções diferentes); }
Incorreta, pois a função printf está escrita de modo errado.
Vetores, Matrizes e Estruturas
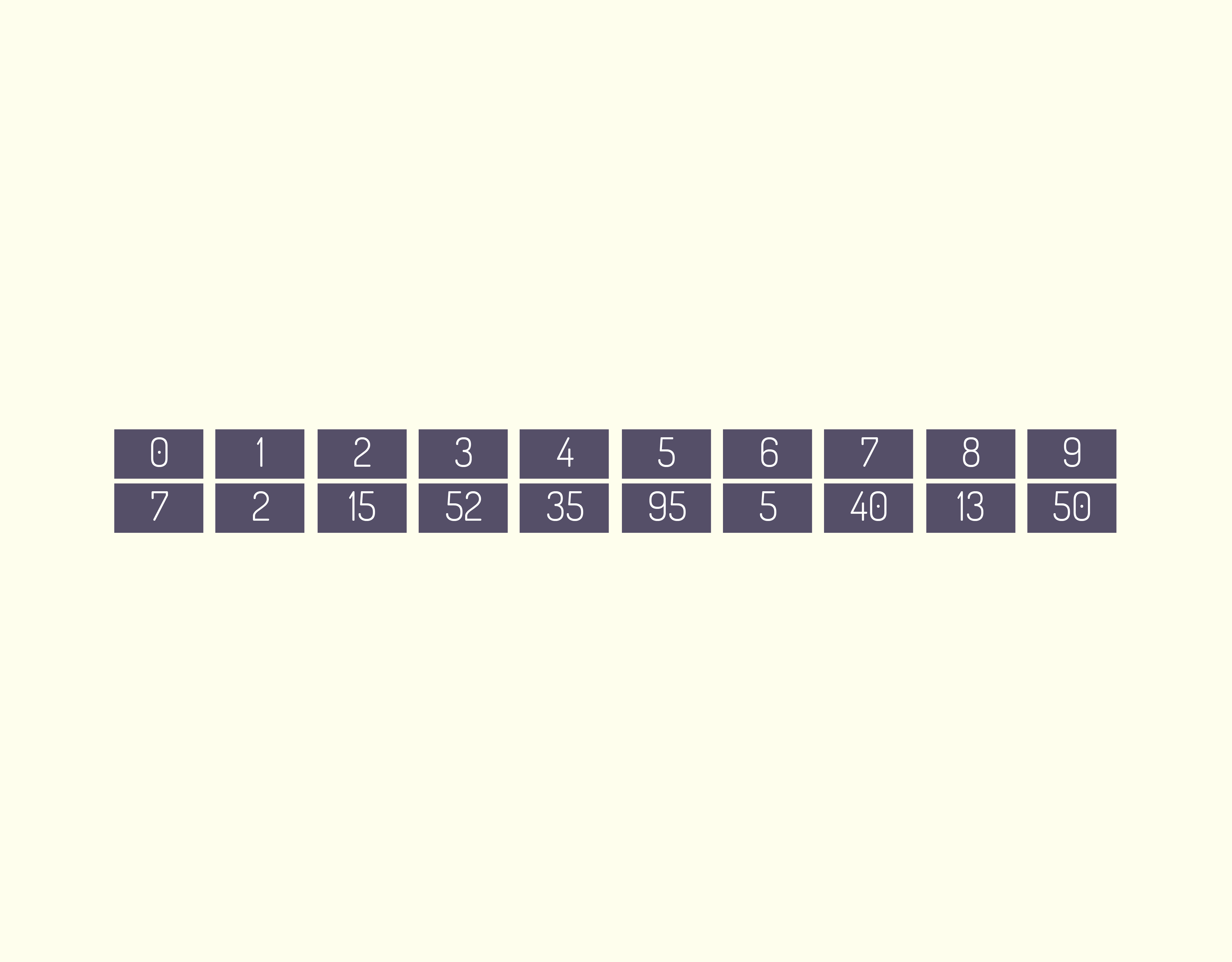
Utilizamos vetores, matrizes e estruturas (struct), quando é necessário termos muitas variáveis para o mesmo fim. Vamos pensar em um sistema que irá armazenar 10 nomes de pessoas, teríamos que ter 10 variáveis declaradas, dessa forma, ao utilizarmos um vetor, se declara apenas 1 variável.
Reflita
Prezado(a) aluno(a), quando estamos falando sobre a quantidade de declarações de variáveis, essa quantidade pode interferir no bom desempenho do programa quando executado ou isso não importa? Com o código fonte menor, o seu entendimento fica confuso ou mais organizado?
Vetores
Alguns autores identificam um vetor como array, em tese, ambos podem ser considerados a mesma coisa e têm a mesma função.
Um array é um conjunto de espaços de memória que se caracterizam pelo fato de que todos têm o mesmo nome e o mesmo tipo de variável (CHAR, INT, FLOAT) ( Adaptado de DEITEL, 2011 p.161).
Vetor também é conhecido como variável composta homogênea unidimensional. Isso quer dizer que se trata de um conjunto de variáveis de mesmo tipo, as quais possuem o mesmo identificador (nome) e são alocadas sequencialmente na memória. Como as variáveis têm o mesmo nome, o que as distingue é um índice que referencia sua localização dentro da estrutura (ASCENCIO, CAMPOS 2007 p.144).
A entrada de dados nesse vetor só será aceito se ele for de igual tipo declarado. Exemplo: se o vetor for declarado com o tipo INT, só serão armazenados dados numéricos inteiros.
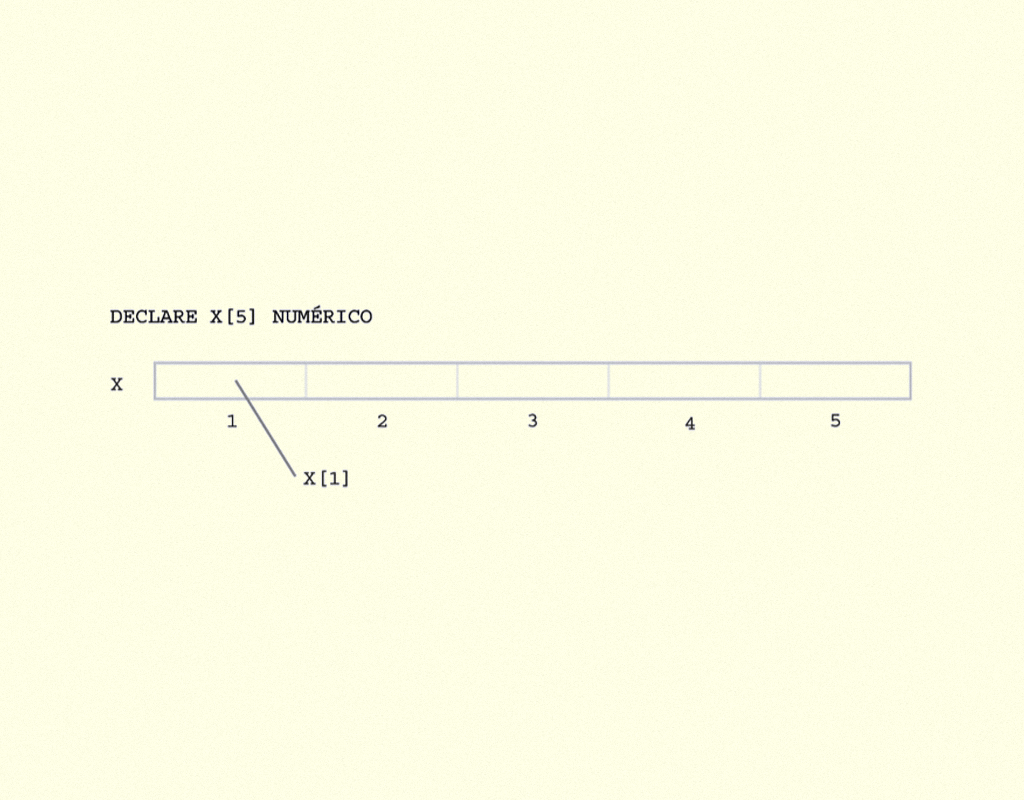
Veja a sintaxe da declaração de um vetor:
13659 Composição textual da declaração de um vetor Fonte: o autor.
O código apresenta a declaração de um vetor com o nome numero, cujo tamanho será de 5, do tipo INT. O tamanho do vetor aceita apenas números inteiros, pois esse valor representa o local que um dado será armazenado no vetor.
13759 Representação de alocação de um dado no vetor Fonte: Ascencio e Campos (2007 p.144).
Para que possamos acessar algum local no vetor, devemos informar qual o local:
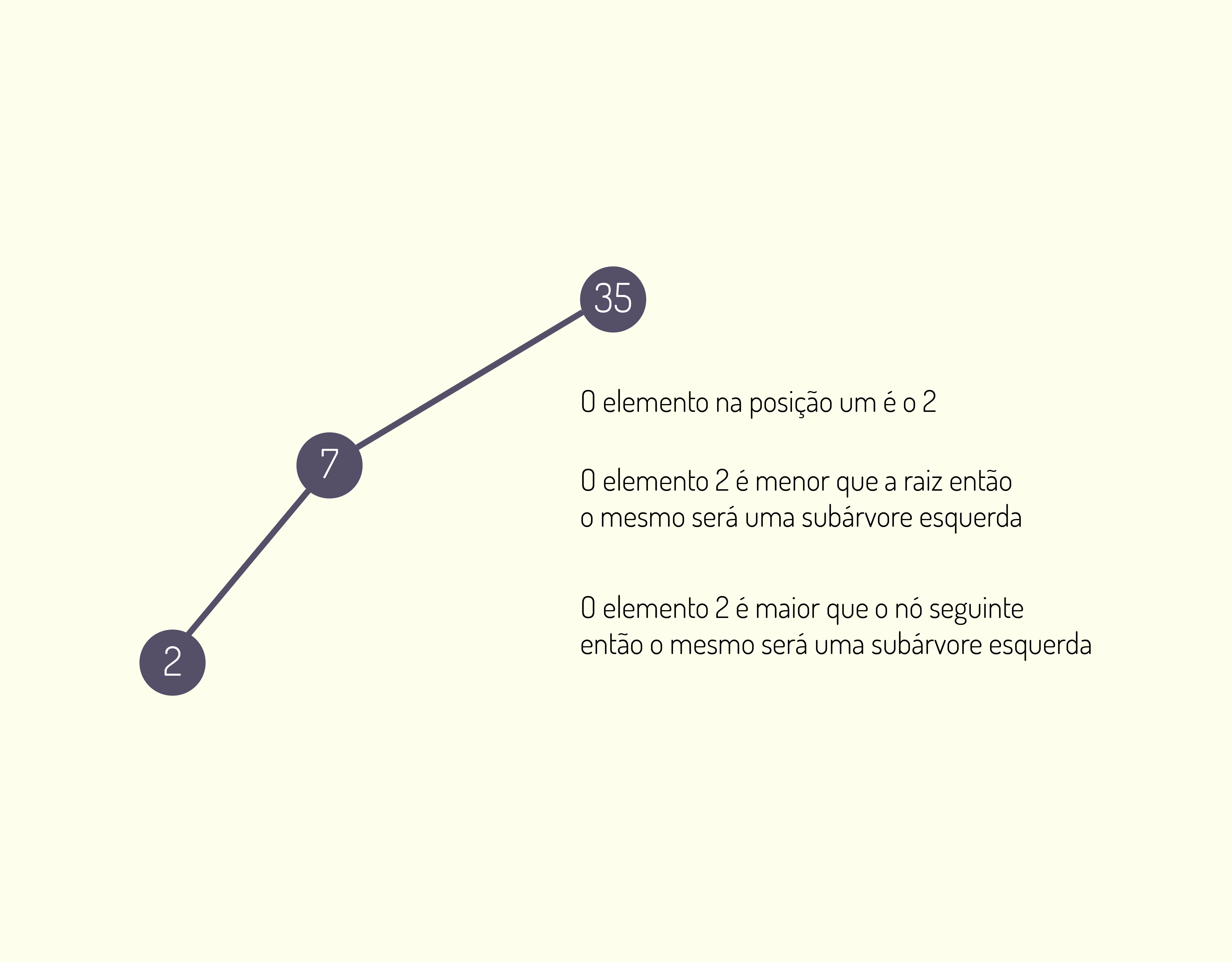
- x[1] = representa a 1º posição do vetor, é possível acessar o dado armazenado se referenciando a sua posição.
- x[4] = representa a 4º posição do vetor, é possível acessar o dado armazenado se referenciando a sua posição.
- x[45] = representa a 45º posição do vetor, é possível acessar o dado armazenado se referenciando a sua posição.
13859 Exemplo de alocação de dados no vetor Fonte: Ascencio e Campos (2007 p.145).
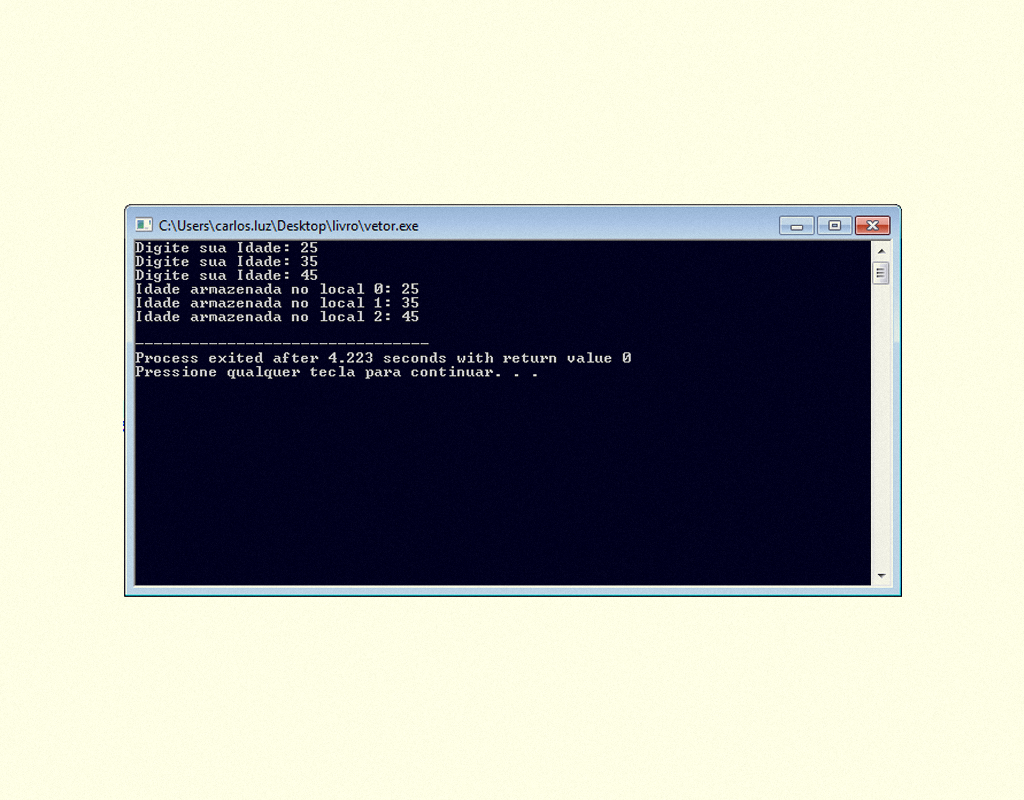
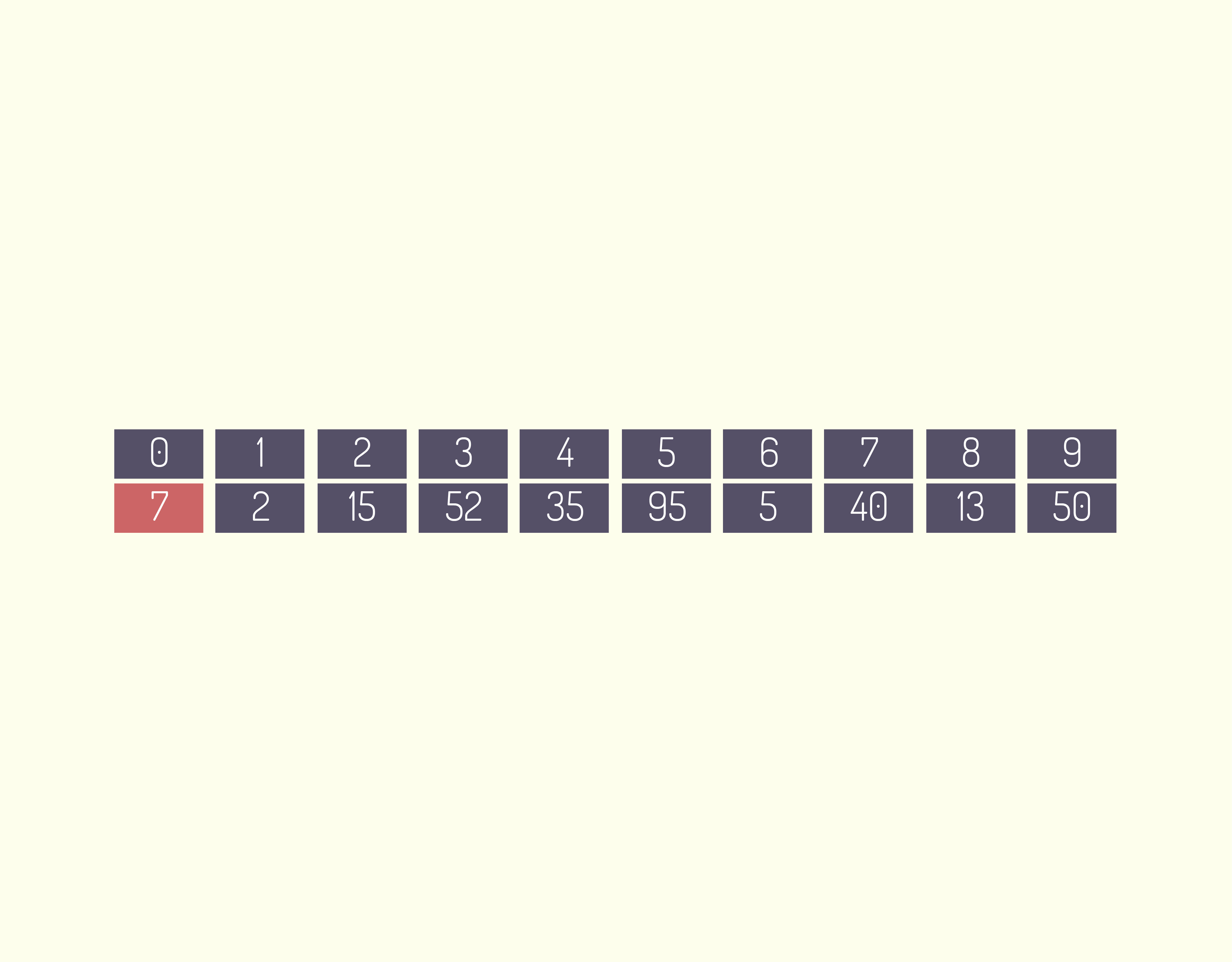
Em um mesmo programa, podemos ter vários vetores de diversos tipos, normalmente as informações são inseridas no vetor através de um laço de repetição ( FOR, WHILE ou DO ... WHILE ), conforme visto no código a seguir.
13959 Exemplo de programa utilizando variável com vetor Fonte: DEV C ++.
Resultado do programa em C apresentado na Figura 1.39.
14059 Resultado do exemplo utilizando vetores Fonte: DEV C ++.
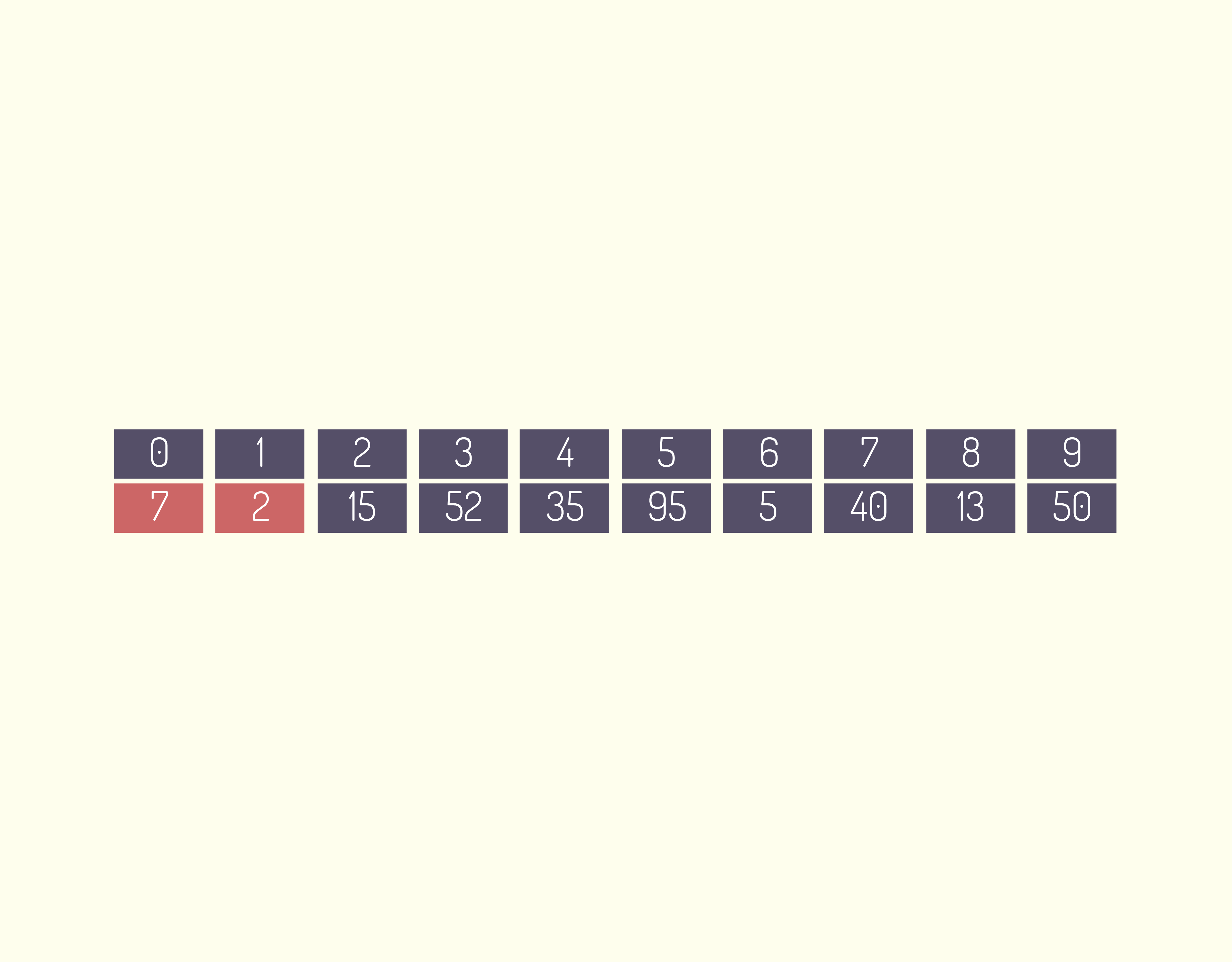
Através do laço de repetição for, foram inseridas 3 entradas de dados nas posições do vetor número, posteriormente, em outro laço de repetição for, foram apresentados os dados na tela.
Um ponto muito importante que devemos observar é que todo e qualquer vetor ou matriz tem sua posição inicial como zero, por exemplo:
- ao declararmos um vetor de 3 posições idade[3]
- as posições respectivamente serão idade[0], idade[1] e idade [2]
Matrizes
Podemos considerar que uma matriz é um vetor melhorado, pois conforme visto anteriormente, os vetores guardam dados do mesmo tipo de variável em uma única linha, através de colunas. Uma matriz trabalha com linhas e colunas, sendo a primeira posição a quantidade de linha e a segunda, a de colunas, assim podemos multiplicar os espaços de armazenamento.
A sintaxe da declaração de uma matriz:
14159 Composição textual da declaração de uma matriz Fonte: o autor.
Ao declararmos um vetor como sendo idade[5], estamos informando que a variável irá armazenar 5 idades, cada uma em sua posição no vetor, ao efetuarmos o mesmo processo utilizando uma matriz idade[5][3], será possível armazenar 5*3 = 15 registros, pois teremos 5 linhas e 3 colunas.
Para manipular os elementos dentro de uma matriz, são utilizadas as coordenadas de sua posição:
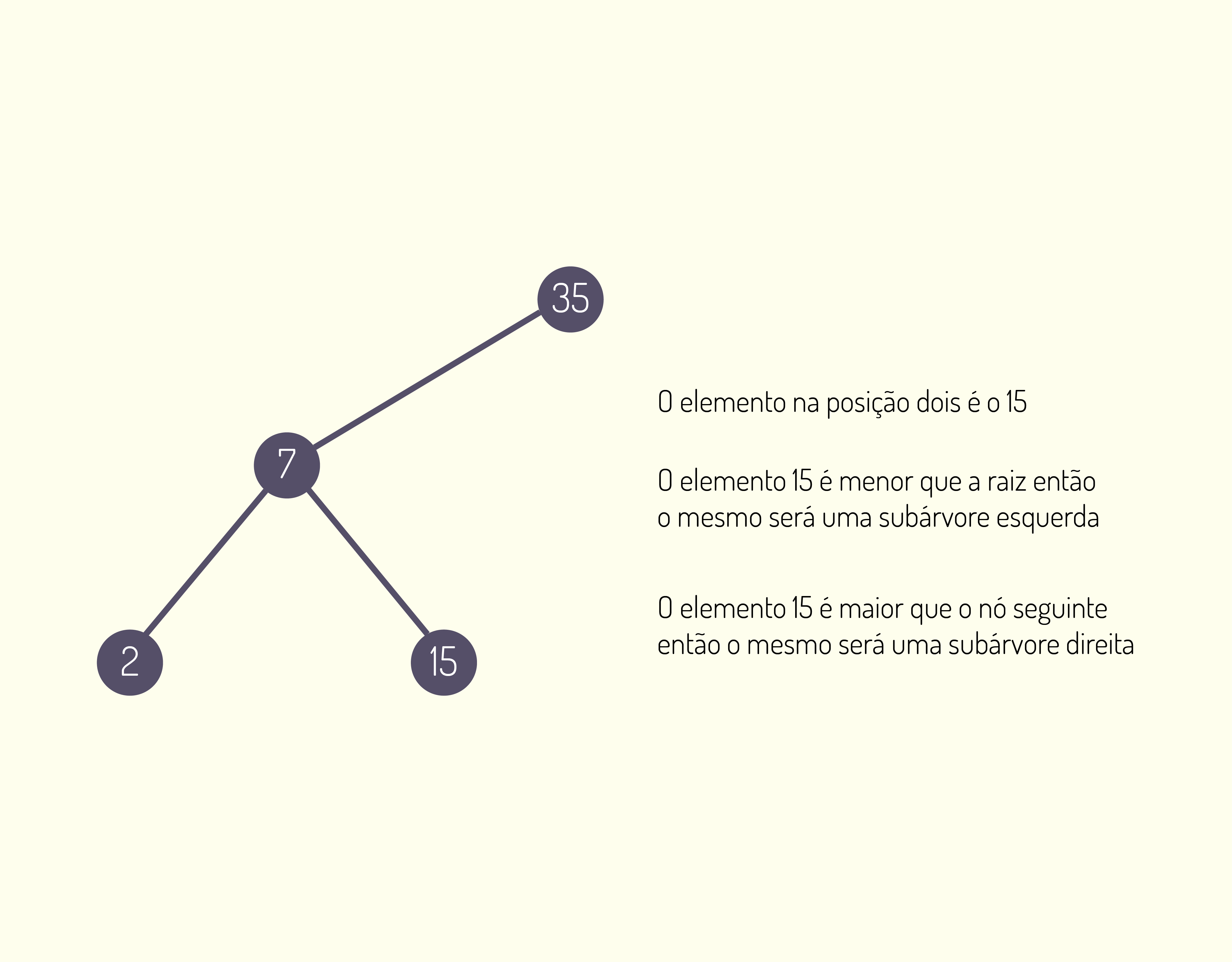
- idade[3][2] = será acessada a 3ª linha e buscados os dados contidos na 2ª coluna;
- numero[1][16] = será acessada a 1ª linha e buscados os dados contidos na 16ª coluna;
- idade[45][13] = será acessada a 45ª linha e buscados os dados contidos na 13ª coluna.
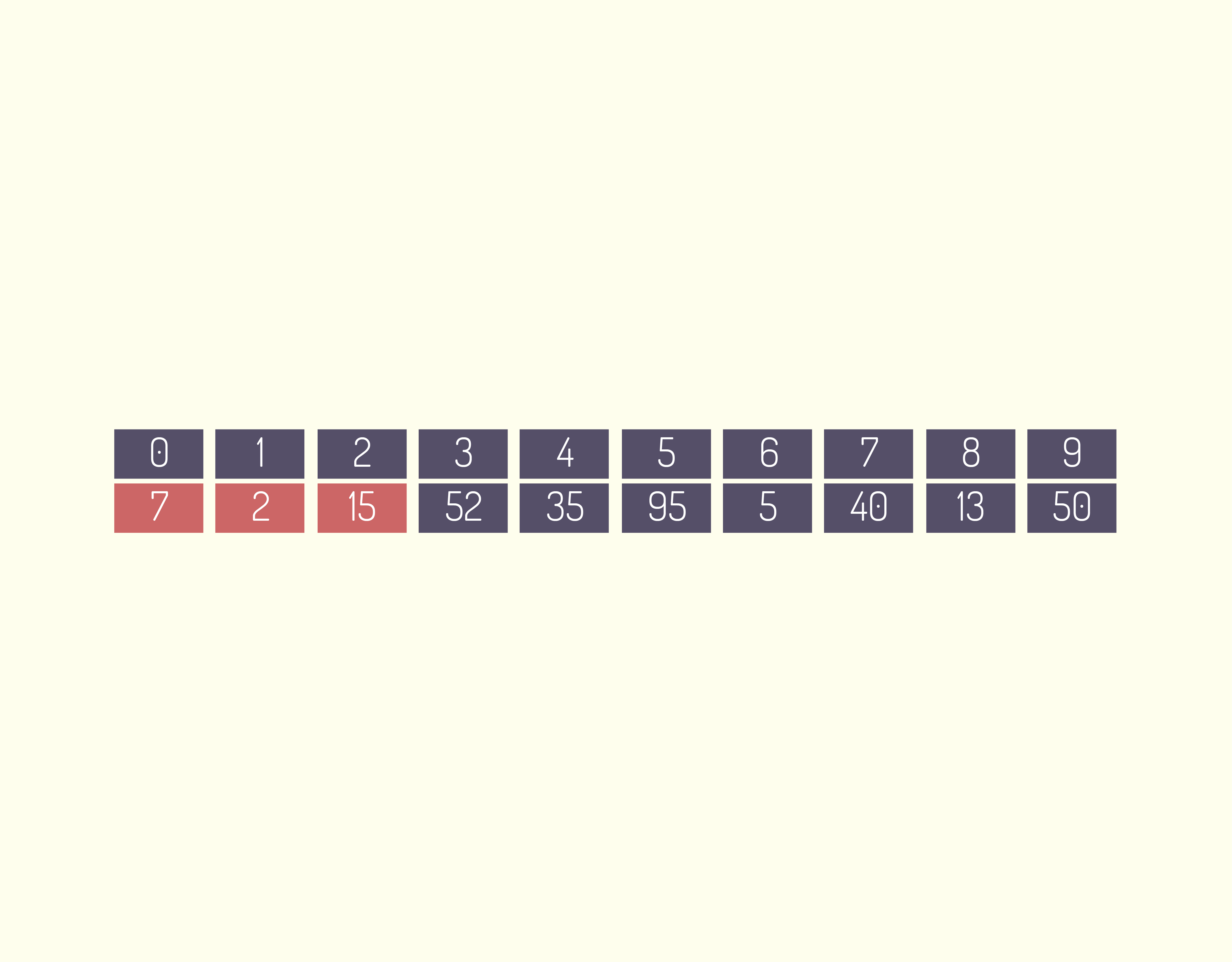
A forma de entrada de dados é muito parecida com a do vetor, mas dessa vez temos que utilizar dois laços de repetição, um que representa a linha, e outro, a coluna.
14259 Exemplo de programa utilizando uma matriz Fonte: DEV C ++.
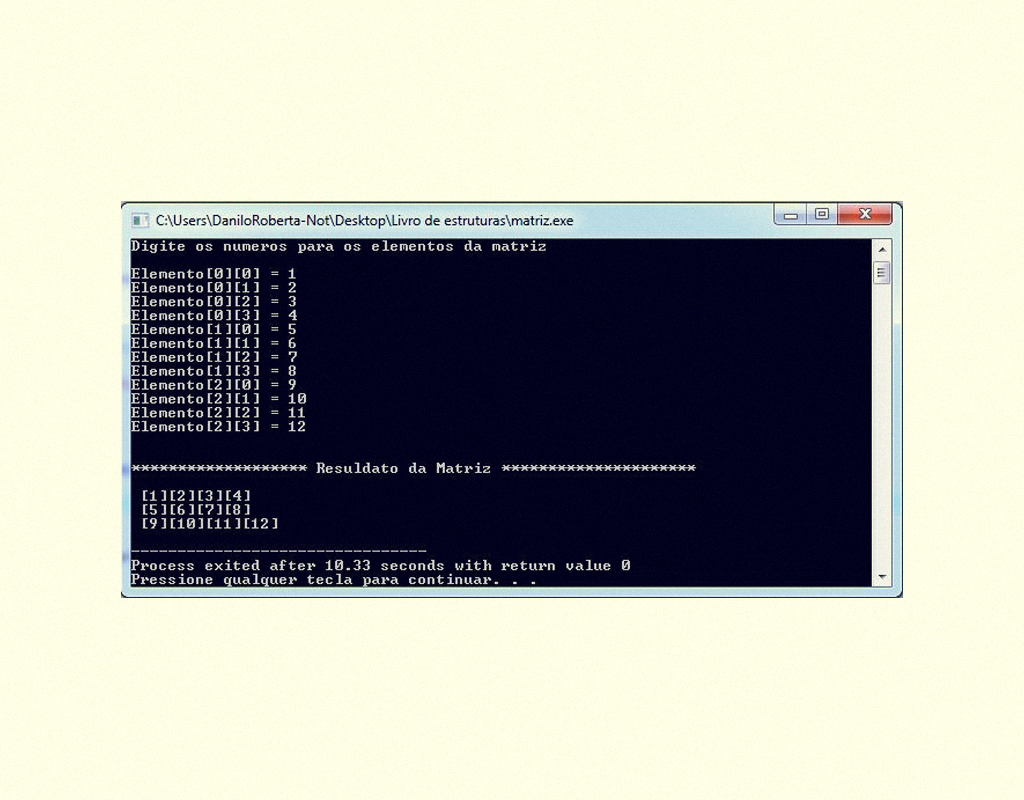
Resultado do programa em C apresentado na Figura 1.42.
14359 Resultado do programa utilizando uma Matriz Fonte: DEV C ++
Estruturas
Os vetores e matrizes são utilizados para o agrupamento de variáveis que sejam do mesmo tipo (INT, FLOAT, DOUBLE, CHAR). Já o comando struct efetua o agrupamento de diferentes tipos de variáveis.
Por meio da palavra-chave struct, definimos um novo tipo de dado. Definir um tipo de dado significa informar ao compilador seu nome, tamanho em bytes e forma como deve ser armazenado e recuperado da memória. Após ter sido definido, o novo tipo existe e pode ser utilizado para criar variáveis de modo similar a qualquer tipo simples (MIZRAHI, 2008 p.223).
Observe a sintaxe da declaração de uma matriz:
14459 Composição textual da declaração de uma struct (estrutura) Fonte: o autor.
Em uma struct,é possível agrupar uma lista de n variáveis de diversos tipos, as quais são declaradas entre as chaves { ... }, da mesma forma como se estivessem sendo declaradas as variáveis fora das chaves.
14559 Exemplo de programa utilizando Struct Fonte: DEV C ++.
Resultado do programa em C apresentado na Figura 1.45.
14659 Resultado do Exemplo utilizando Struct Fonte: DEV C ++
Atividades
Podemos agrupar variáveis do mesmo tipo através de um vetor, sabendo que este armazena os dados de modo linear, em formar de linha, ou em uma matriz, utilizando-se linhas e colunas. Assinale a alternativa correspondente a onde os dados do Aluno Carlos estão sendo armazenados: nome[15], dados_pessoa[5][6], nota[1]:
- O nome está na 15ª posição, os dados pessoais estão na posição 56 da matriz, sua nota está na 1ª posição
Os dados pessoais estão na 5 linha e 6 coluna
- O nome está na 15ª posição, os dados pessoais estão na coluna 5 linha 6 da matriz, sua nota está na 1ª posição.
As posições dos dados pessoais estão invertidas, o correto é linha 5 coluna 6.
- O nome está na 15ª posição, os dados estão na posição 56, a nota do aluno é 1.
A posição dos dados pessoais estão totalmente incorretos e a nota do aluno não é 1, ela está armazenada na 1ª posição do vetor.
- O nome se encontra na 15ª posição, os dados do aluno estão na linha 5 e coluna 6, e sua nota está na 1ª posição.
Posição 15ª , Posição 5ª linha 6ª coluna e nota na 1ª posição do vetor.
- Nenhuma das alternativas, pois a forma de declarar os vetores e a matriz está incorreta.
A alternativa B está correta, por isso, há uma alternativa correta.
Funções e Ponteiros
Em certos pontos de um programa, temos que repetir um bloco de código por várias vezes, essa repetição deixará nosso código fonte muito extenso podendo causar lentidão quando executado.
Podemos utilizar funções para evitar que um trecho seja repetido por várias vezes de modo desnecessário, havendo também um reaproveitamento do código já desenvolvido.
Pensando no aproveitamento de código, podemos utilizar os ponteiros, os quais podem assumir o armazenamento de outras variáveis, posteriormente efetuando o apontamento do local.
Funções
Os principais benefícios de se utilizarem funções seriam: uma melhor organização e reaproveitamento do código, consequentemente, um melhor entendimento.
As funções são blocos de construção em C, em que ocorrem todas as atividades do programa. Assim que uma função tenha sido escrita e depurada, poderá ser reutilizada quantas vezes for necessário ( SCHILDT, 1986 p.78).
Veja a sintaxe da declaração de uma função:
14759 Composição textual da declaração de função Fonte: o autor.
Podem-se declarar as variáveis que serão utilizadas na função de três formas: globais, locais e parâmetros formais.
- Variáveis globais: são declaradas fora da função, como as demais, Albano e Albano (2010 p.132) complementam dizendo que “a mesma pode ser utilizada ou acessada por qualquer função ou bloco de comando.”
- Variáveis locais: são declaradas dentro da função a ser utilizada, Albano e Albano (2010 p.132) afirmam que “as variáveis locais pertencem apenas à função onde foram declaradas, não podendo, portanto, ser acessadas por meio de outra função de forma direta”.
- Parâmetros formais: são declarados na passagem de dados para a função, veremos com mais detalhe no próximo tópico.
14859 Exemplo da criação de uma função. Fonte: Dev C ++.
Vamos analisar os códigos a seguir, sendo um desenvolvido de modo convencional e outro com a aplicação de funções:
14959 Exemplo de programa sem utilizar funções Fonte: DEV C ++.
15059 Código com aplicação de funções Fonte: DEV C ++.
É possível ver claramente que, ao se utilizar a função, nosso código fonte ficou menor, podendo agora efetuar a chamada da função soma() em qualquer parte do código fonte.
Resultado do programa em C apresentado na Figura 1.50.
15159 Resultado do programa utilizando a função Fonte: DEV C ++.
Informando parâmetros de função
Ao utilizarmos funções, em alguns casos, temos que informar alguns dados para a manipulação dessas, pode-se efetuar esse comando por meios das variáveis de parâmetros formais. A sintaxe da função sofre apenas algumas modificações, pois é inserida uma lista de parâmetros esperada para ser utilizada dentro da função.
15259 Composição textual da passagem de parâmetros da função Fonte: o autor.
Na passagem de parâmetros, os dados das variáveis são armazenados em novas variáveis, sendo respeitada a respectiva ordem de parâmetros. Temos então dois tipos: os parâmetros reais, que são dados obtidos na entrada pelo usuário, e os formais, que são os parâmetros declarados na função.
15359 Exemplo de programa utilizando passagem de parâmetros para a função Fonte: DEV C ++.
Resultado do programa em C apresentado na Figura 1.53.
15459 Resultado do programa utilizando passagem de parâmetros Fonte: DEV C ++.
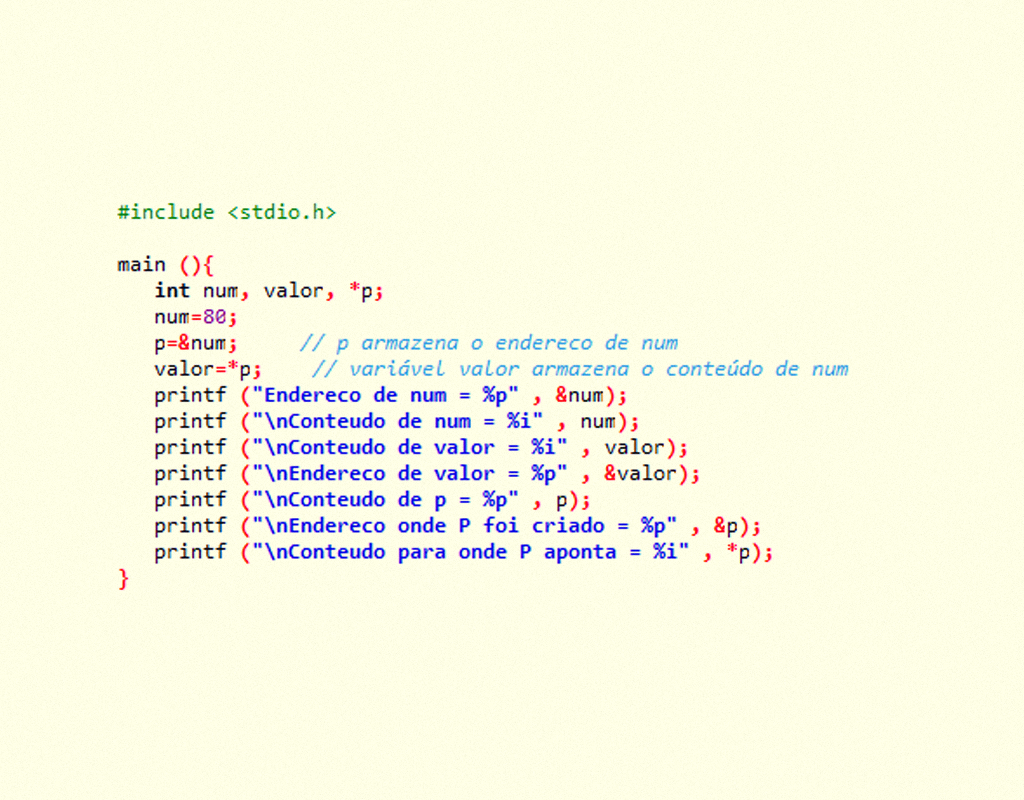
Ponteiros
Como já apresentado, ao declararmos uma variável, ela se reserva um espaço na memória para armazenamento dos dados, cada espaço possui um endereço lógico, um número hexadecimal e, por meio desse endereço, é possível recuperar as informações armazenadas. Calma, prezado(a) aluno(a), não é necessário saber qual é o endereço lógico, pois quem efetua essa manipulação é o próprio SO (Sistema Operacional) e o programa em execução.
Basicamente, um ponteiro é uma variável que armazena um endereço de memória, isto é, o ponteiro é um tipo de variável capaz de atribuir somente os endereços de outra variável ao seu conteúdo, o qual é bem diferente das variáveis comuns com as quais estávamos trabalhando até o momento (ALBANO, ALBANO 2010 p.156).
Um ponteiro é considerado uma variável, o modo de declará-lo é bem parecido com as demais, a única diferença é que antes do nome do ponteiro é inserido o caractere asterisco *, sintaxe de declaração de um ponteiro:
15559 Composição textual da declaração de um ponteiro Fonte: o autor.
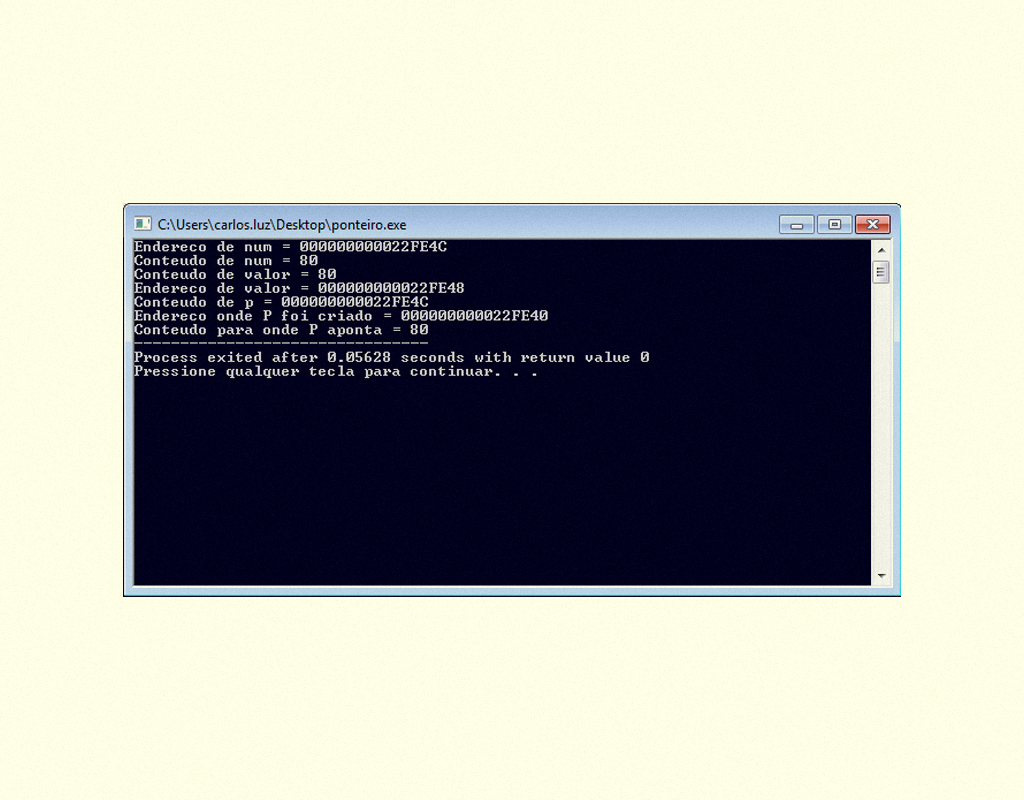
Pode-se utilizar um ponteiro com variável de diversos tipos como INT, FLOAT, CHAR e também STRUCT, vejamos a seguir um código no qual se utiliza um ponteiro do tipo inteiro:
15659 Exemplo de programa utilizando ponteiro Fonte: DEV C ++.
Resultado do programa em C apresentado na Figura 1.56.
15759 Resultado do programa utilizando ponteiro Fonte: DEV C ++.
Vejamos agora outro exemplo de ponteiros.
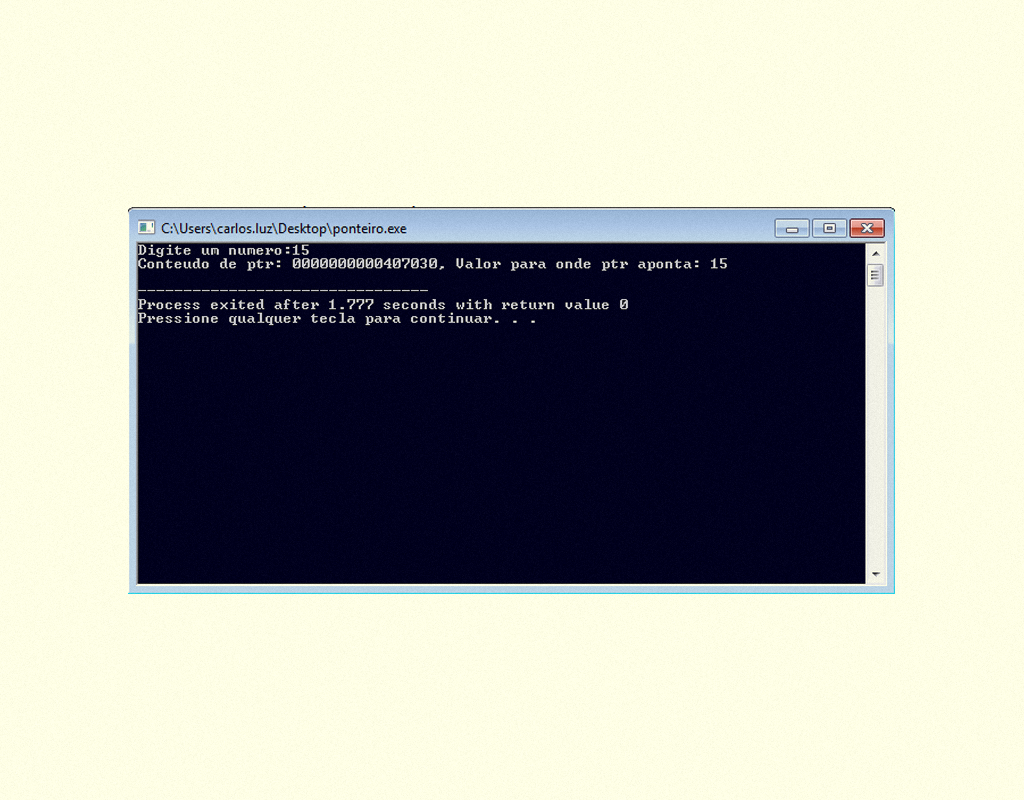
15859 Exemplo 2 de programa utilizando ponteiros Fonte: DEV C ++.
Resultado do programa em C apresentado na Figura 1.58.
15959 Resultado do exemplo 2, utilizando ponteiros Fonte: DEV C ++.
Atividades
O principal benefício de se utilizar uma função no desenvolvimento de um programa é o fato de se reaproveitar trechos do código e diminuí-lo. Para manipular os dados dentro de uma função, podem-se usar variáveis. Com base nisso, assinale a alternativa correta sobre os tipos de declarações de uma variável em linguagem Cl
- Parâmetros formais, locais, globais.
Conforme apresentado na Unidade, são essas as 3 formas de declarações de uma variável em C.
- Locais, externas, parâmetros gerais.
A forma de declaração não é Gerais, mas Globais, e a forma externa já e a global.
- Globais, internas, gerais.
Globais e Gerais é a mesma coisa, faltou parâmetros formais.
- Parâmetros formais, globais, internas.
A declaração dentro da função é chamada de Locais.
- Globais, locais, independentes.
Não existe a forma de declaração independente.
Indicação de leitura
Nome do livro: Programação em Linguagem C
Editora: Ciência Moderna
Autor: ALBANO, Ricardo Sonaglio; ALBANO, Silvie Guedes.
ISBN: 978-857393-949-1
Sinopse: A linguagem C é utilizada na área de programação. O livro “Programação em linguagem C” oferece mais de 200 códigos-fontes, distribuídos entre exemplos e exercícios de fixação. É indicado para alunos de cursos de graduação, técnicos ou cursos livres. Além disso, os autodidatas poderão utilizar este livro, já que ele abrange, de forma sequencial, a fase introdutória da linguagem de programação C até a sua fase intermediária. Essa obra contém vários exercícios executados passo a passo que permitem que o leitor possa acompanhar o desenvolvimento de maneira útil e eficaz. Dessa forma, o próprio leitor poderá implementar cada exercício à medida que vai lendo o livro. A obra apresenta-se estruturada de forma que, ao final de cada capítulo, sejam apresentados exercícios de revisão abrangendo cada conteúdo estudado, com o objetivo de avaliar e consolidar os conhecimentos adquiridos. Salientando que todos os exercícios possuem resolução contida no final do livro.























































{kind=link}